Ameya P.
@bayesiankitten.bsky.social
570 followers
130 following
15 posts
Postdoctoral Researcher @ Bethgelab, University of Tübingen
Benchmarking | LLM Agents | Data-Centric ML | Continual Learning | Unlearning
drimpossible.github.io
Posts
Media
Videos
Starter Packs
Reposted by Ameya P.


Reposted by Ameya P.

Reposted by Ameya P.

Reposted by Ameya P.



Ameya P.
@bayesiankitten.bsky.social
· Mar 12

Reposted by Ameya P.

Reposted by Ameya P.

Hilde Kuehne
@hildekuehne.bsky.social
· Feb 19
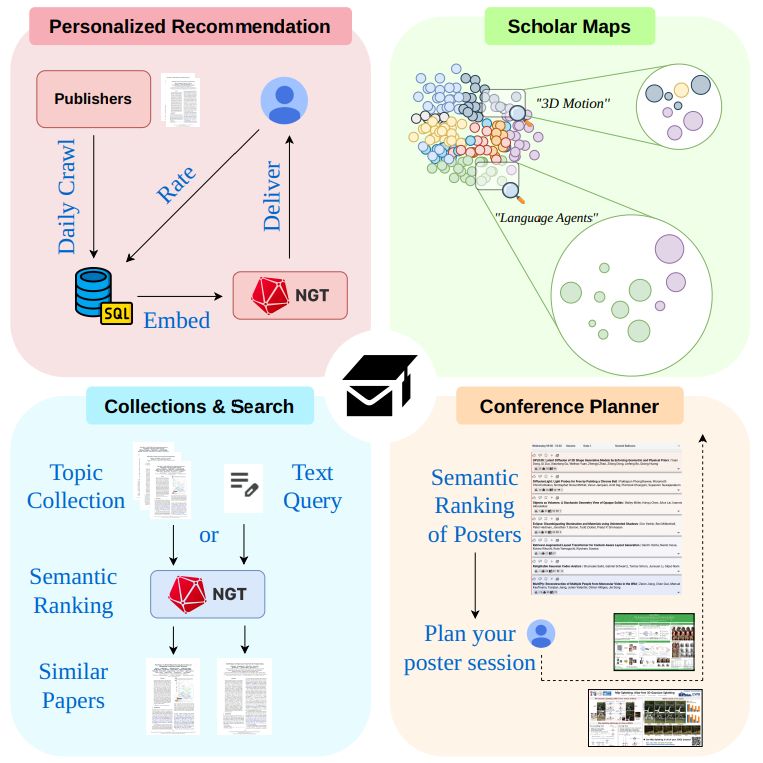
Conference Management Toolkit - Login
Microsoft's Conference Management Toolkit is a hosted academic conference management system. Modern interface, high scalability, extensive features and outstanding support are the signatures of Micros...
cmt3.research.microsoft.com
Reposted by Ameya P.

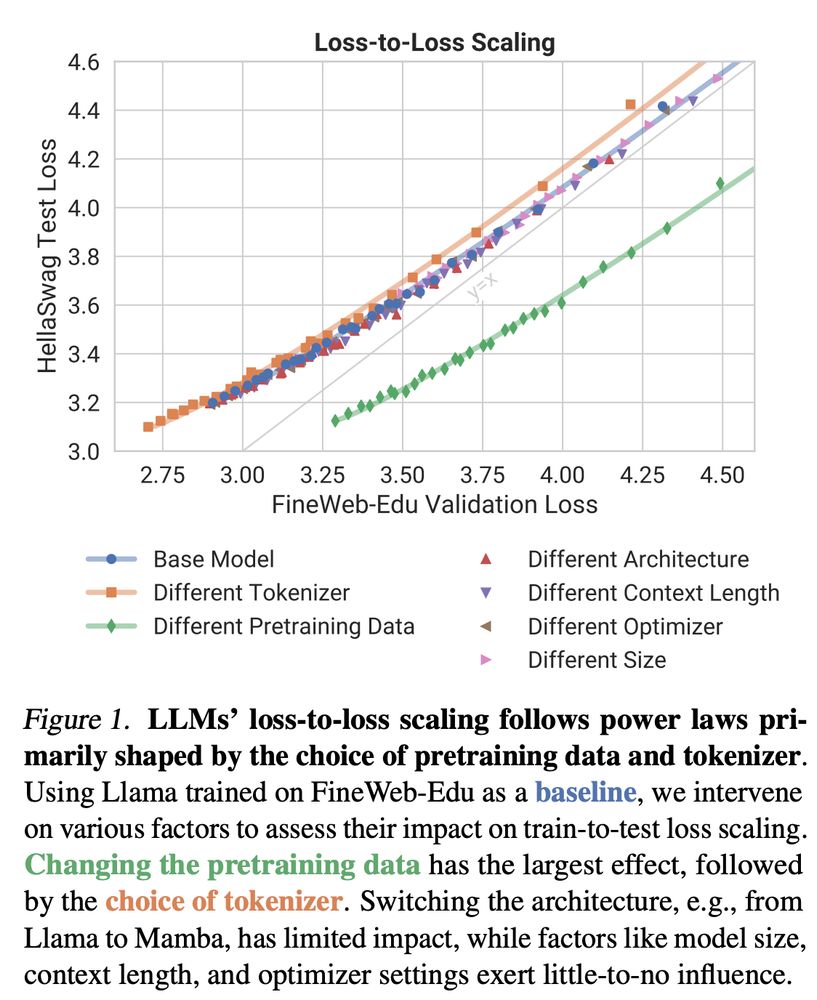
Ameya P.
@bayesiankitten.bsky.social
· Feb 17
Reposted by Ameya P.


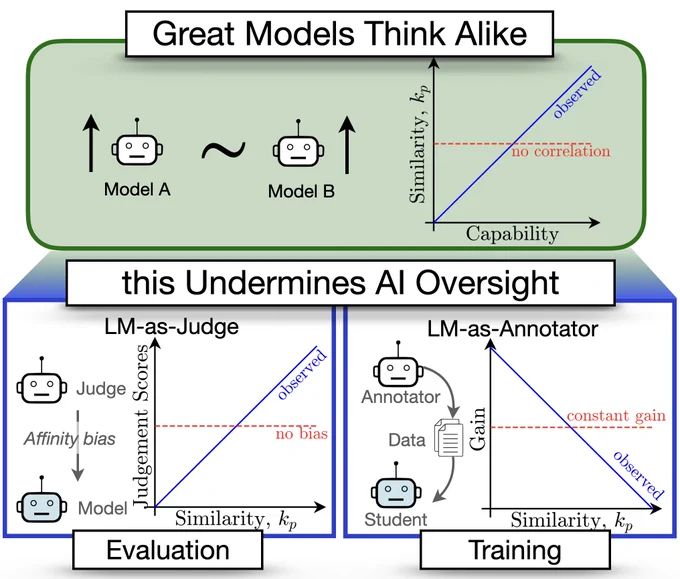
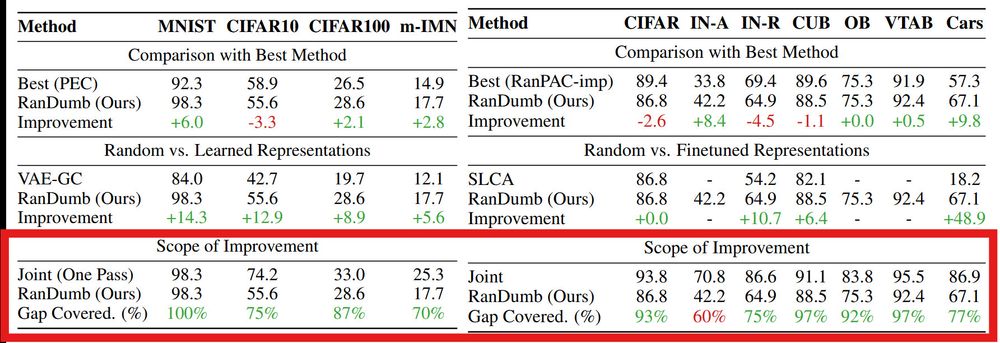
Ameya P.
@bayesiankitten.bsky.social
· Dec 13

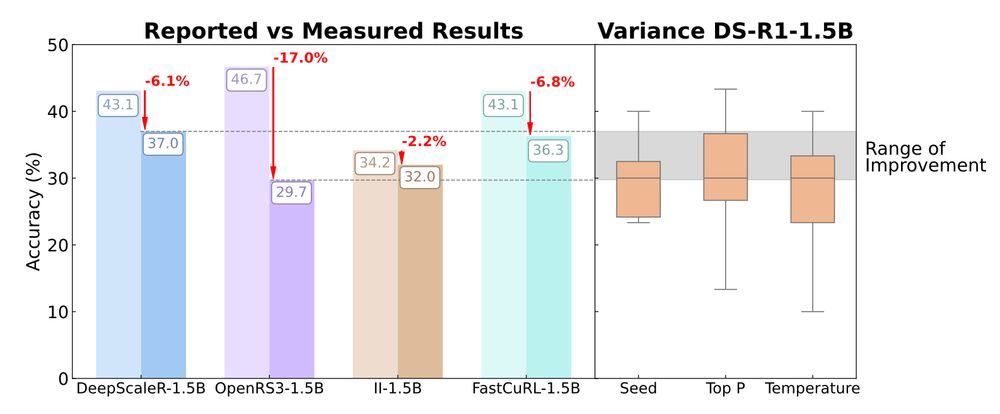
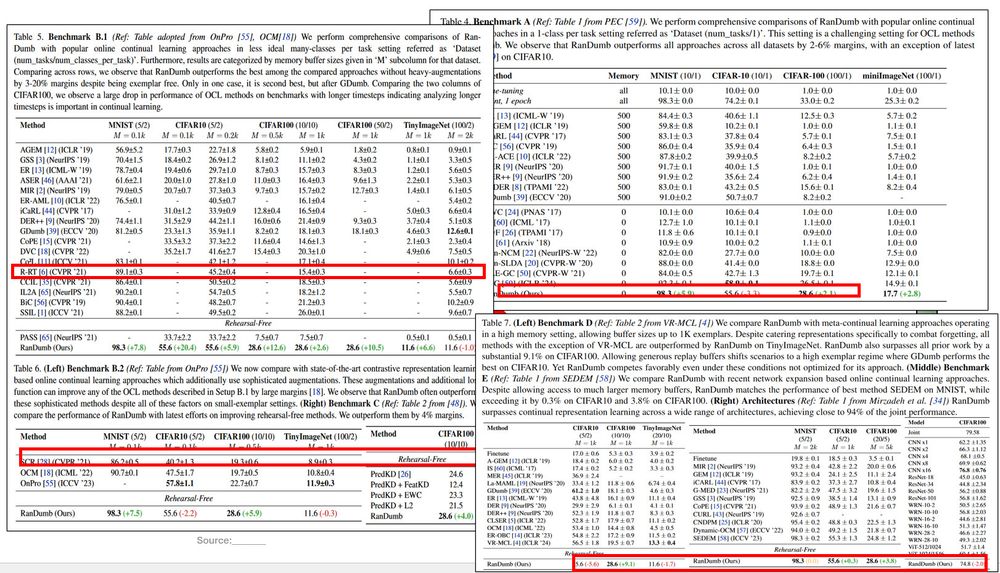
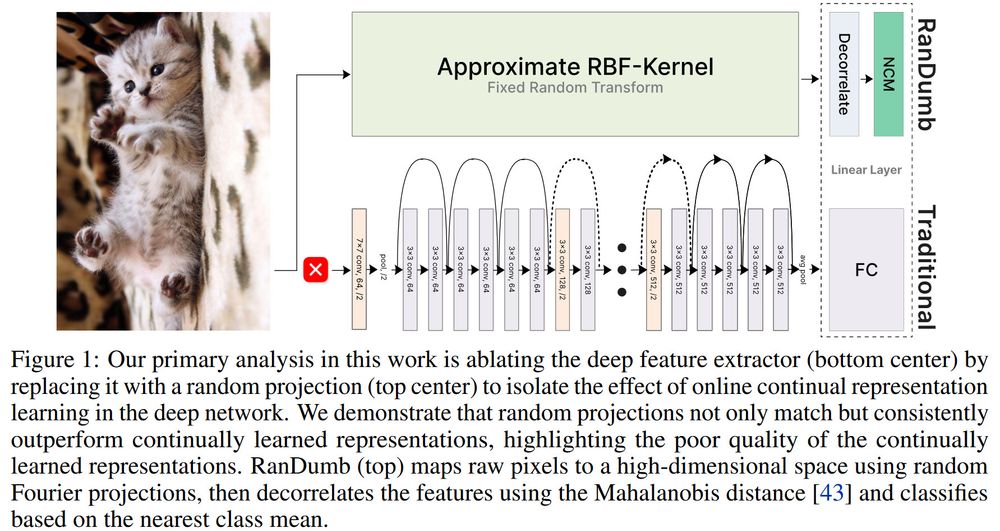
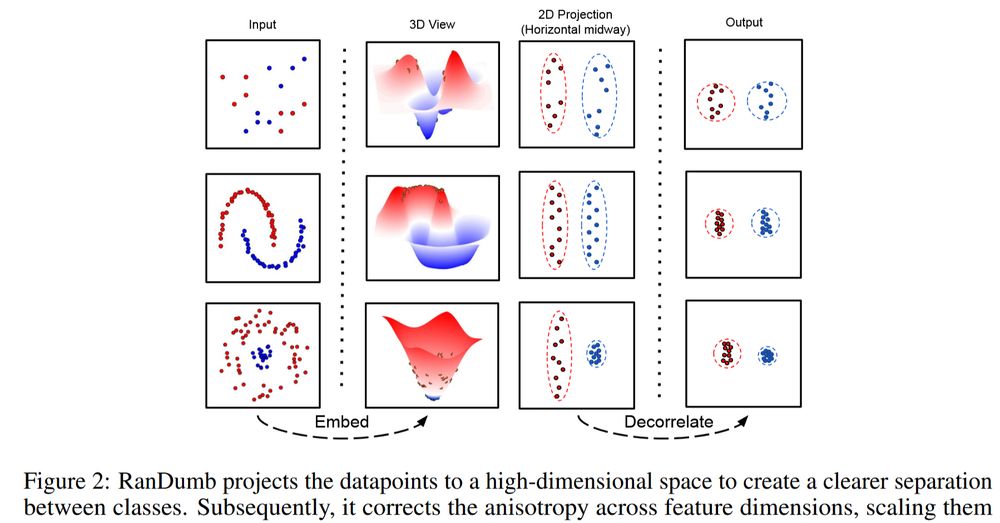
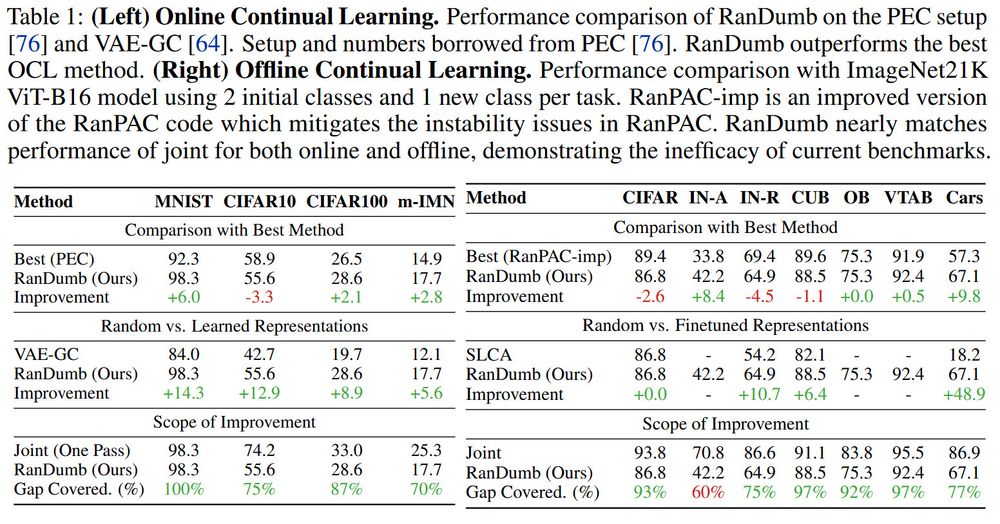
Random Representations Outperform Online Continually Learned Representations
Continual learning has primarily focused on the issue of catastrophic forgetting and the associated stability-plasticity tradeoffs. However, little attention has been paid to the efficacy of continual...
arxiv.org
Reposted by Ameya P.

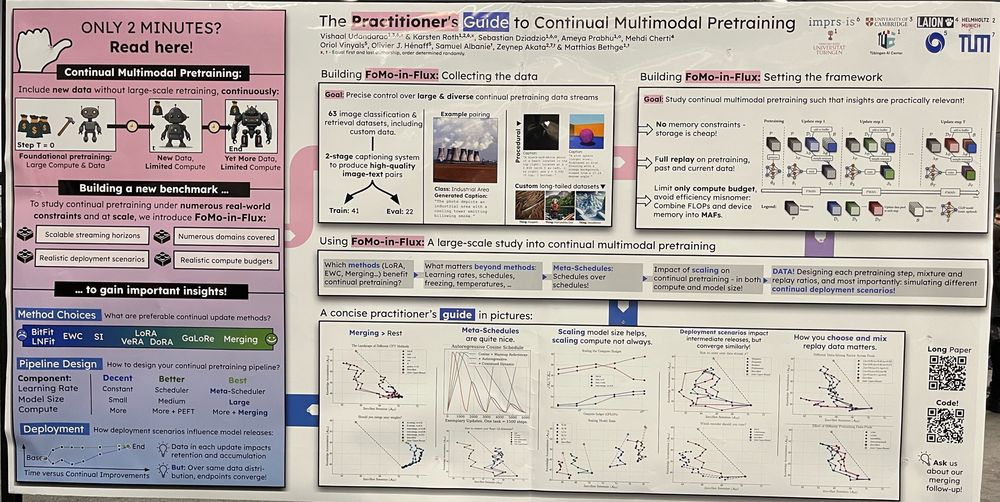
Ameya P.
@bayesiankitten.bsky.social
· Dec 11

Sebastian Dziadzio
@dziadzio.bsky.social
· Dec 11

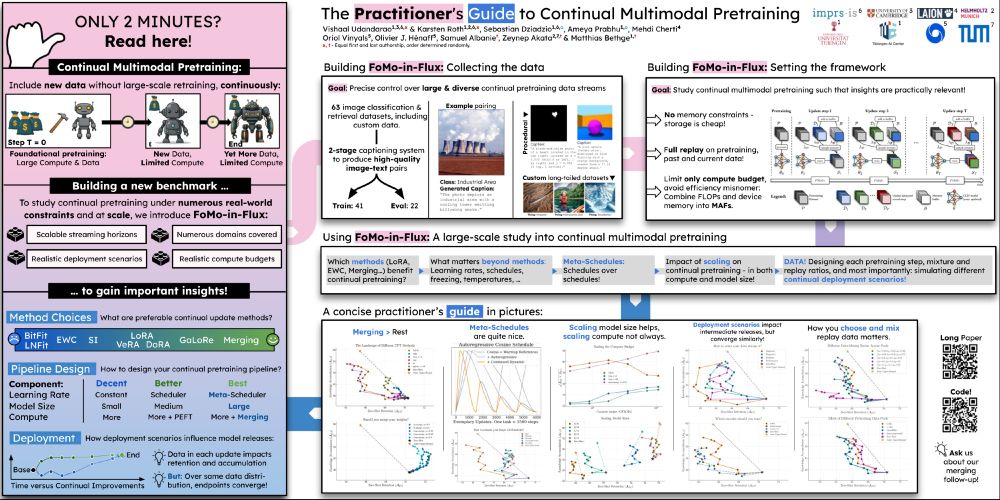
How to Merge Your Multimodal Models Over Time?
Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches...
arxiv.org
Ameya P.
@bayesiankitten.bsky.social
· Dec 10