Wang Bill Zhu
@billzhu.bsky.social
93 followers
70 following
13 posts
CS Ph.D. candidate @ USC, https://billzhu.me
Posts
Media
Videos
Starter Packs


Wang Bill Zhu
@billzhu.bsky.social
· Apr 16







Wang Bill Zhu
@billzhu.bsky.social
· Apr 16

Cancer-Myth: Evaluating AI Chatbot on Patient Questions with False Presuppositions
Cancer patients are increasingly turning to large language models (LLMs) as a new form of internet search for medical information, making it critical to assess how well these models handle complex, pe...
arxiv.org
Reposted by Wang Bill Zhu

Robin Jia
@robinjia.bsky.social
· Dec 9
Wang Bill Zhu
@billzhu.bsky.social
· Oct 10

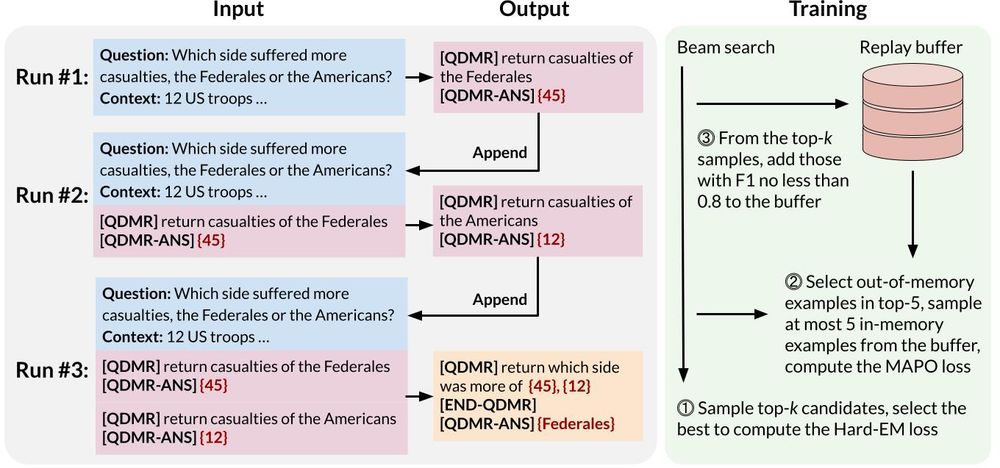
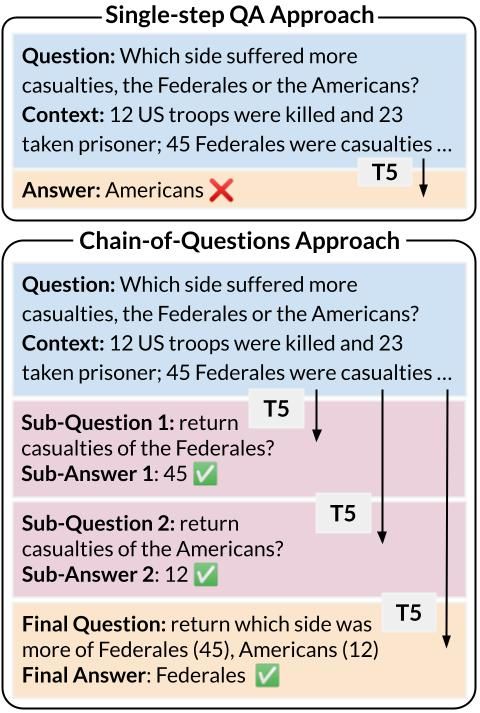
Chain-of-Questions Training with Latent Answers for Robust...
We train a language model (LM) to robustly answer multistep questions by generating and answering sub-questions. We propose Chain-of-Questions, a framework that trains a model to generate...
arxiv.org