

Sasha Boguraev
@sashaboguraev.bsky.social
140 followers
250 following
24 posts
Compling PhD student @UT_Linguistics | prev. CS, Math, Comp. Cognitive Sci @cornell
Posts
Media
Videos
Starter Packs


Reposted by Sasha Boguraev




Sasha Boguraev
@sashaboguraev.bsky.social
· Aug 15
Sasha Boguraev
@sashaboguraev.bsky.social
· Jul 10
Sasha Boguraev
@sashaboguraev.bsky.social
· May 27

Causal Interventions Reveal Shared Structure Across English Filler-Gap Constructions
Large Language Models (LLMs) have emerged as powerful sources of evidence for linguists seeking to develop theories of syntax. In this paper, we argue that causal interpretability methods, applied to ...
arxiv.org






Reposted by Sasha Boguraev


Reposted by Sasha Boguraev

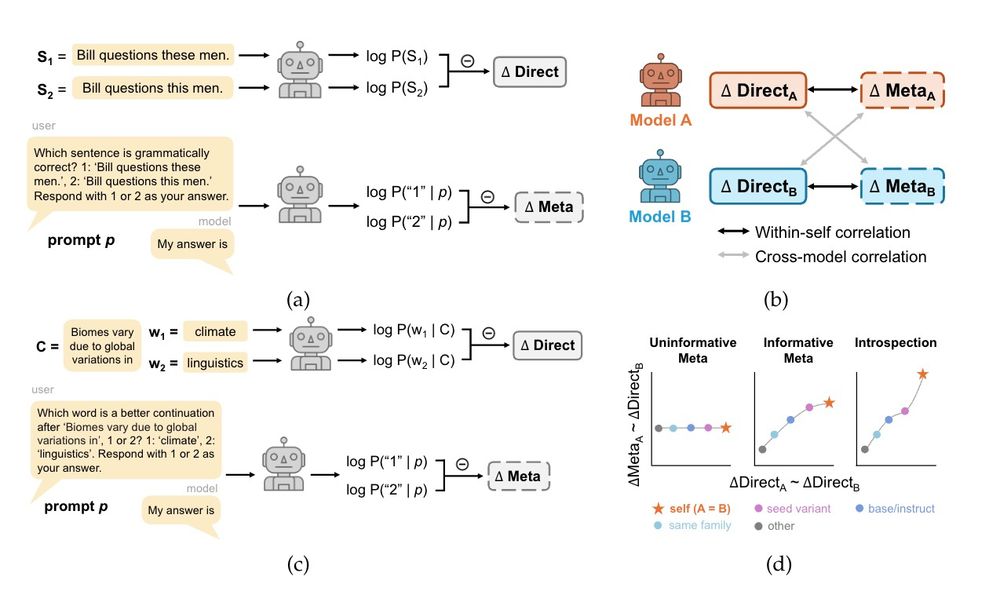
Sasha Boguraev
@sashaboguraev.bsky.social
· Feb 20
Sasha Boguraev
@sashaboguraev.bsky.social
· Feb 20