
@simjeg.bsky.social
230 followers
36 following
16 posts
Senior LLM Technologist @NVIDIA
Views and opinions are my own
Posts
Media
Videos
Starter Packs






Reposted

simjeg.bsky.social
@simjeg.bsky.social
· Nov 21

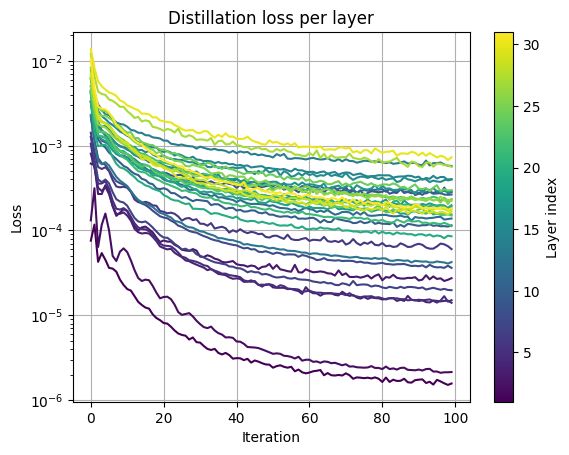
simjeg.bsky.social
@simjeg.bsky.social
· Nov 20
simjeg.bsky.social
@simjeg.bsky.social
· Nov 20

simjeg.bsky.social
@simjeg.bsky.social
· Nov 19
simjeg.bsky.social
@simjeg.bsky.social
· Nov 19