
Sohee Yang
@soheeyang.bsky.social
120 followers
68 following
27 posts
PhD student/research scientist intern at UCL NLP/Google DeepMind (50/50 split). Previously MS at KAIST AI and research engineer at Naver Clova. #NLP #ML 👉 https://soheeyang.github.io/
Posts
Media
Videos
Starter Packs
Pinned



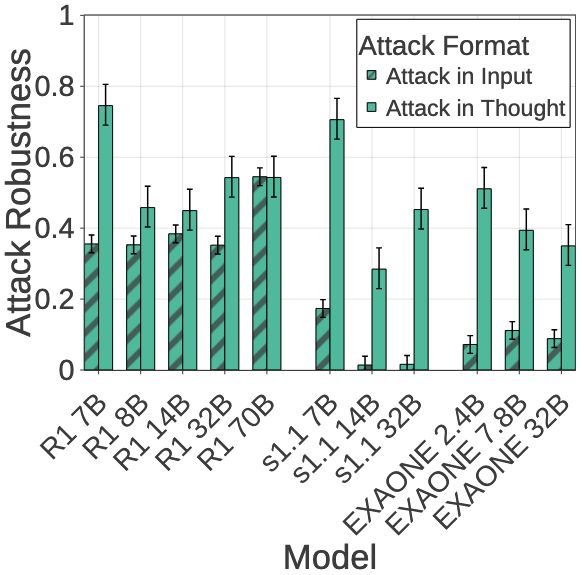
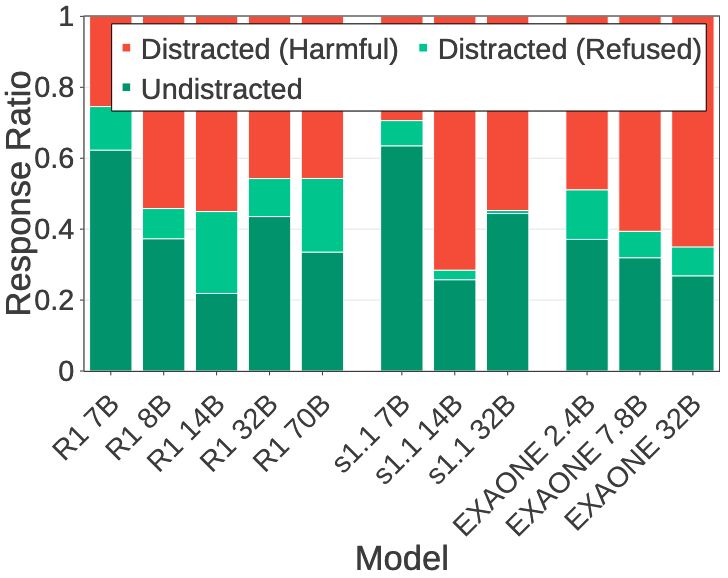
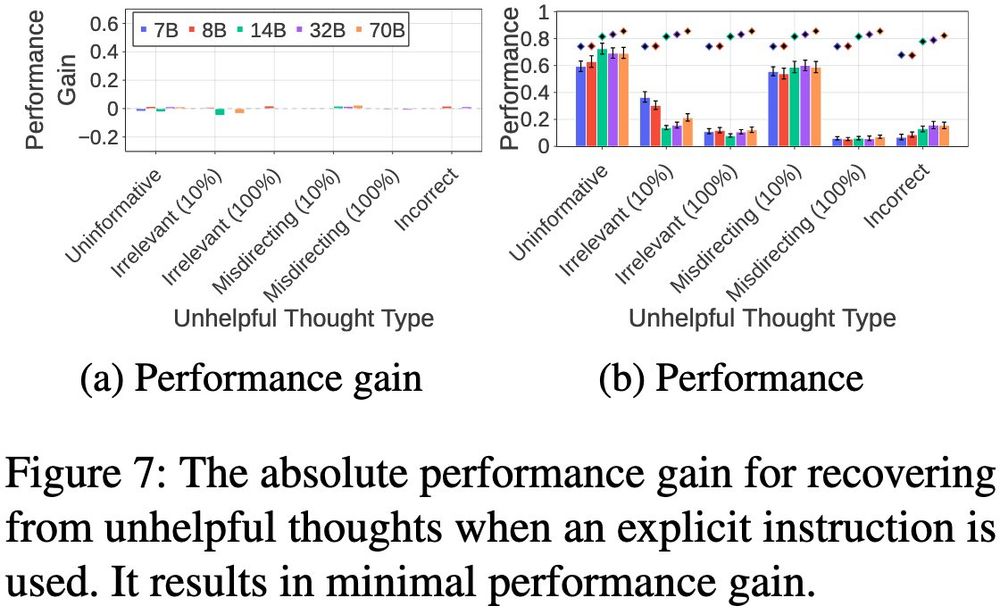
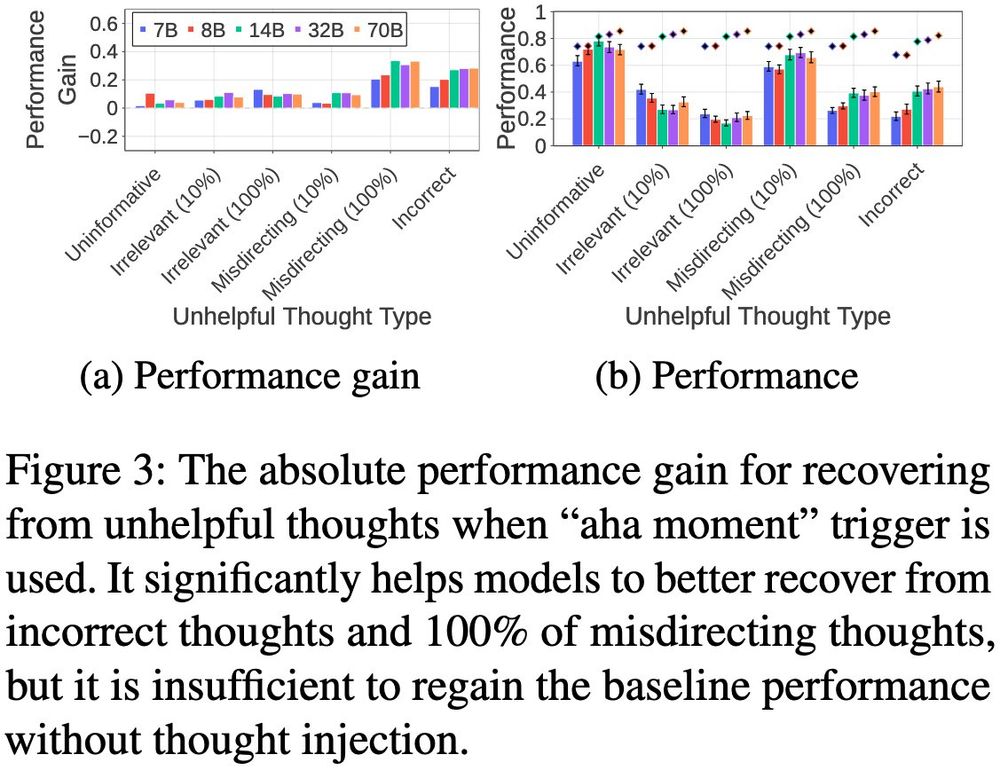
Sohee Yang
@soheeyang.bsky.social
· Jun 13
Sohee Yang
@soheeyang.bsky.social
· Jun 13
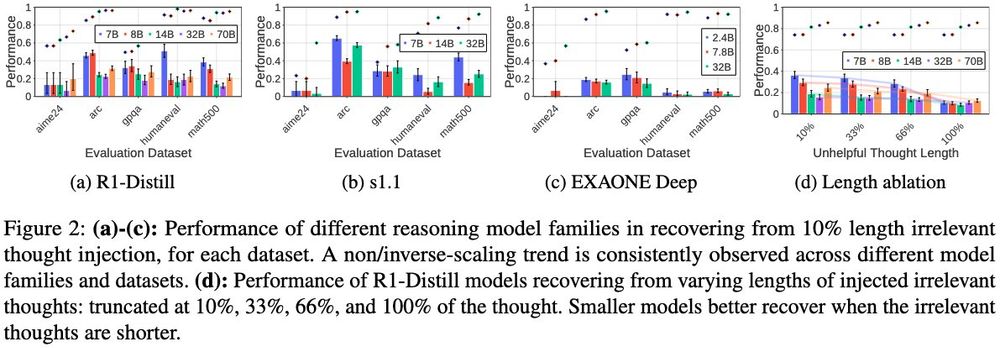
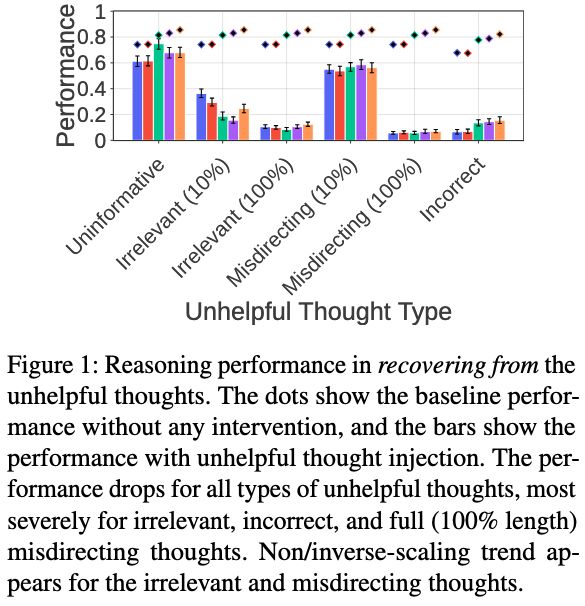
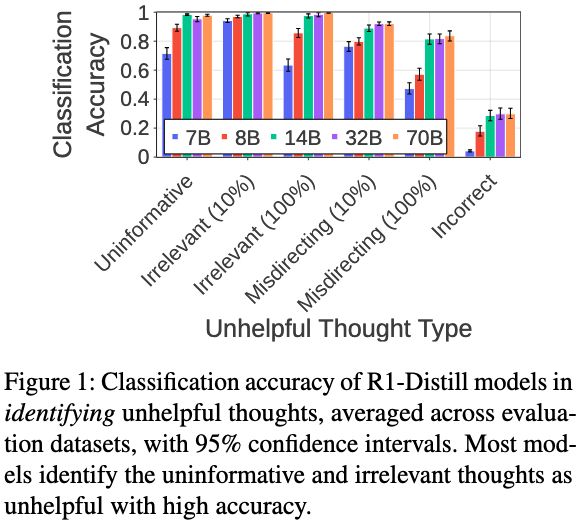
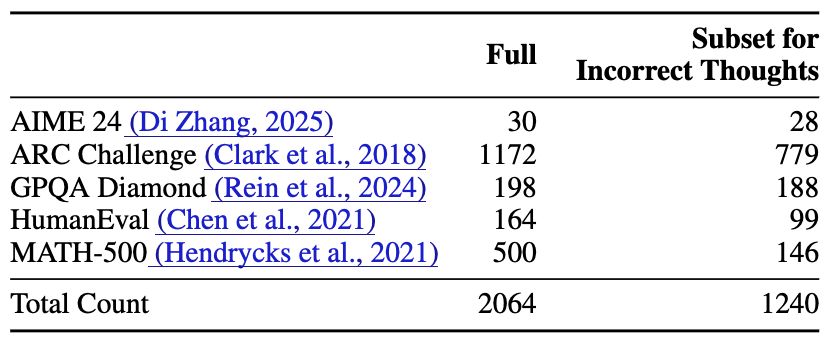


Sohee Yang
@soheeyang.bsky.social
· Jun 13
Reposted by Sohee Yang

Laura
@lauraruis.bsky.social
· Nov 20
Reposted by Sohee Yang


Sohee Yang
@soheeyang.bsky.social
· Nov 27

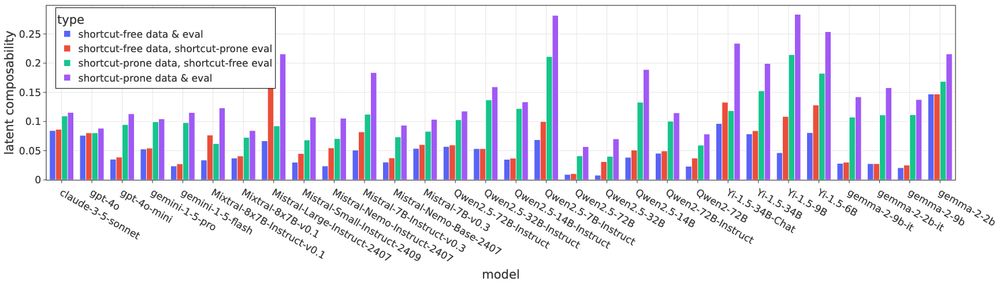
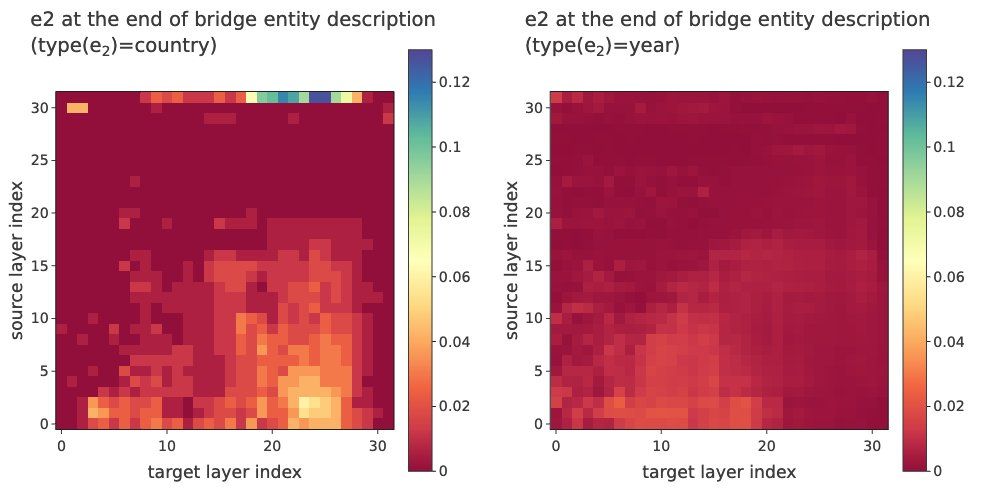
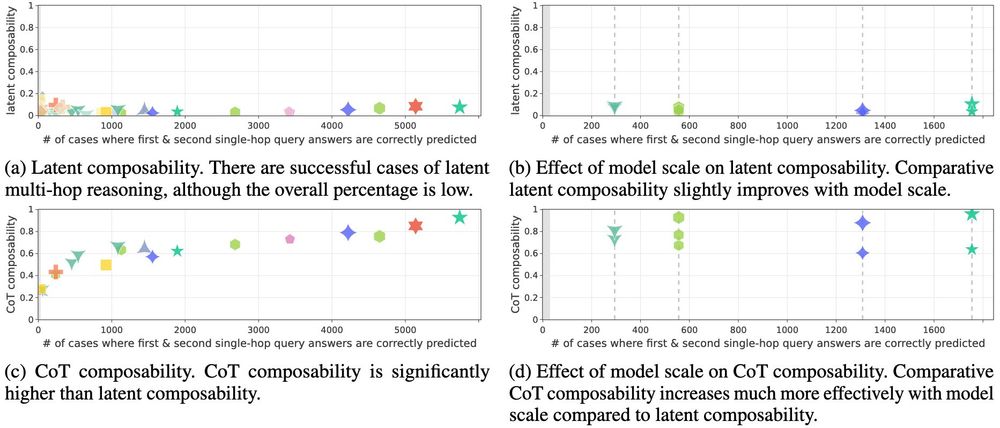
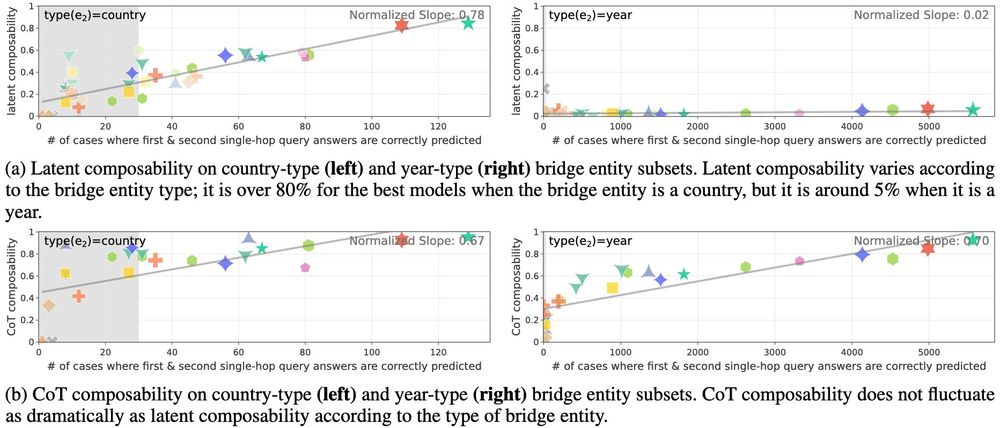
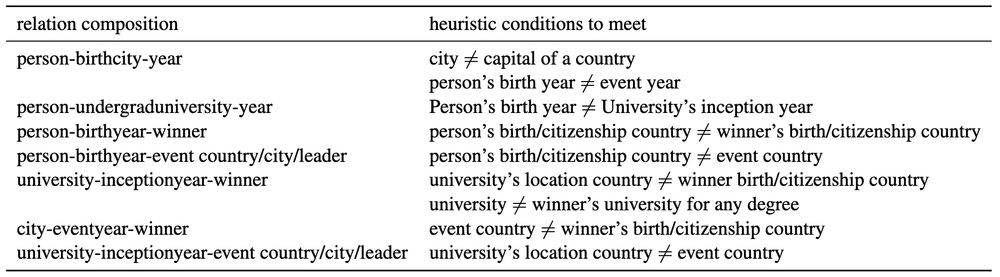
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
We evaluate how well Large Language Models (LLMs) latently recall and compose facts to answer multi-hop queries like "In the year Scarlett Johansson was born, the Summer Olympics were hosted in the co...
arxiv.org
Sohee Yang
@soheeyang.bsky.social
· Nov 27

Sohee Yang
@soheeyang.bsky.social
· Nov 27