



Mohit Iyyer
@miyyer.bsky.social
associate prof at UMD CS researching NLP & LLMs
Reposted by Mohit Iyyer

Well this is sure to be a blockbuster AI article... @jennarussell.bsky.social et al are kicking ass and taking names in journalism, both individuals and organizations.
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774


October 23, 2025 at 1:53 PM
Well this is sure to be a blockbuster AI article... @jennarussell.bsky.social et al are kicking ass and taking names in journalism, both individuals and organizations.
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774
Reposted by Mohit Iyyer

AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:

October 22, 2025 at 3:24 PM
AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
Tired of AI slop? Our work on "Frankentexts" shows how LLMs can stitch together random fragments of human writing into coherent, relevant responses to arbitrary prompts.
Frankentexts are weirdly creative, and they also pose problems for AI detectors: are they AI? human? More 👇
Frankentexts are weirdly creative, and they also pose problems for AI detectors: are they AI? human? More 👇

🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.

June 3, 2025 at 4:16 PM
Tired of AI slop? Our work on "Frankentexts" shows how LLMs can stitch together random fragments of human writing into coherent, relevant responses to arbitrary prompts.
Frankentexts are weirdly creative, and they also pose problems for AI detectors: are they AI? human? More 👇
Frankentexts are weirdly creative, and they also pose problems for AI detectors: are they AI? human? More 👇
Llama 4's massive context window is impressive! However, the best Llama model for long-context understanding over books is still Llama 3.1 405B. Llama 4 Scout is especially bad at our NoCha benchmark, performing below random chance.

April 8, 2025 at 1:48 AM
Llama 4's massive context window is impressive! However, the best Llama model for long-context understanding over books is still Llama 3.1 405B. Llama 4 Scout is especially bad at our NoCha benchmark, performing below random chance.
Thinking about paying $20k/month for a "PhD-level AI agent"? You might want to wait until their web browsing skills are on par with those of human PhD students 😛 Check out our new BEARCUBS benchmark, which shows web agents struggle to perform simple multimodal browsing tasks!

Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%

March 12, 2025 at 4:08 PM
Thinking about paying $20k/month for a "PhD-level AI agent"? You might want to wait until their web browsing skills are on par with those of human PhD students 😛 Check out our new BEARCUBS benchmark, which shows web agents struggle to perform simple multimodal browsing tasks!
New synthetic benchmark for multilingual long-context LLMs! Surprisingly, English and Chinese are not the top-performing languages (it's Polish!). We also observe a widening gap between high and low-resource languages as context size increases. Check out the paper for more 👇

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇

March 5, 2025 at 6:44 PM
New synthetic benchmark for multilingual long-context LLMs! Surprisingly, English and Chinese are not the top-performing languages (it's Polish!). We also observe a widening gap between high and low-resource languages as context size increases. Check out the paper for more 👇
How can we generate synthetic data for a task that requires global reasoning over a long context (e.g., verifying claims about a book)? LLMs aren't good at *solving* such tasks, let alone generating data for them. Check out our paper for a compression-based solution!
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
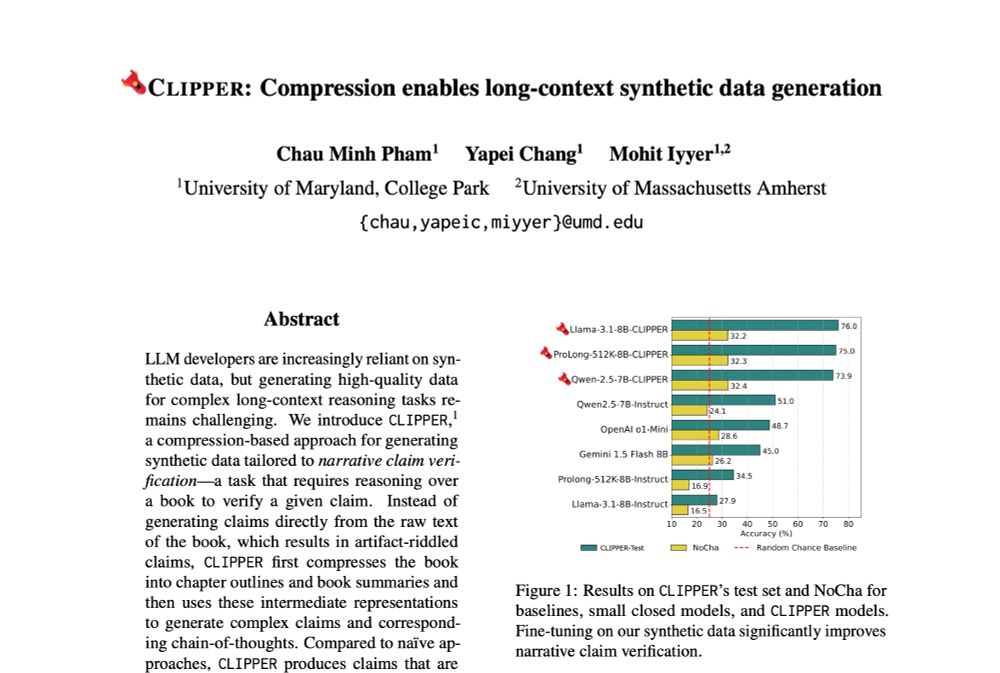
February 21, 2025 at 4:37 PM
How can we generate synthetic data for a task that requires global reasoning over a long context (e.g., verifying claims about a book)? LLMs aren't good at *solving* such tasks, let alone generating data for them. Check out our paper for a compression-based solution!
Lots of recent work focuses on 𝐚𝐮𝐭𝐨𝐦𝐚𝐭𝐢𝐜 detection of LLM-generated text. But how well do 𝐡𝐮𝐦𝐚𝐧𝐬 fare? TLDR: ppl who frequently use ChatGPT for writing tasks are elite at spotting AI text! See our paper for more (and congrats to @jennarussell.bsky.social on her first paper!!)
People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯

January 28, 2025 at 3:12 PM
Lots of recent work focuses on 𝐚𝐮𝐭𝐨𝐦𝐚𝐭𝐢𝐜 detection of LLM-generated text. But how well do 𝐡𝐮𝐦𝐚𝐧𝐬 fare? TLDR: ppl who frequently use ChatGPT for writing tasks are elite at spotting AI text! See our paper for more (and congrats to @jennarussell.bsky.social on her first paper!!)