


Orion Weller
@orionweller.bsky.social
PhD Student at Johns Hopkins University. Previously: Allen Institute for AI, Apple, Samaya AI. Research for #NLProc #IR
Ever wonder how test-time compute would do in retrieval? 🤔
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵


February 26, 2025 at 2:57 PM
Ever wonder how test-time compute would do in retrieval? 🤔
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵
Reposted by Orion Weller

We use this collection of tasks to propose multiple benchmarks for multilingual, code, European and Indic languages, and many more.
We find that smaller multilingual models (~500M) outperform notably larger 7B models, likely due to a limited multilingual pre-training.
We find that smaller multilingual models (~500M) outperform notably larger 7B models, likely due to a limited multilingual pre-training.

February 20, 2025 at 9:57 AM
We use this collection of tasks to propose multiple benchmarks for multilingual, code, European and Indic languages, and many more.
We find that smaller multilingual models (~500M) outperform notably larger 7B models, likely due to a limited multilingual pre-training.
We find that smaller multilingual models (~500M) outperform notably larger 7B models, likely due to a limited multilingual pre-training.
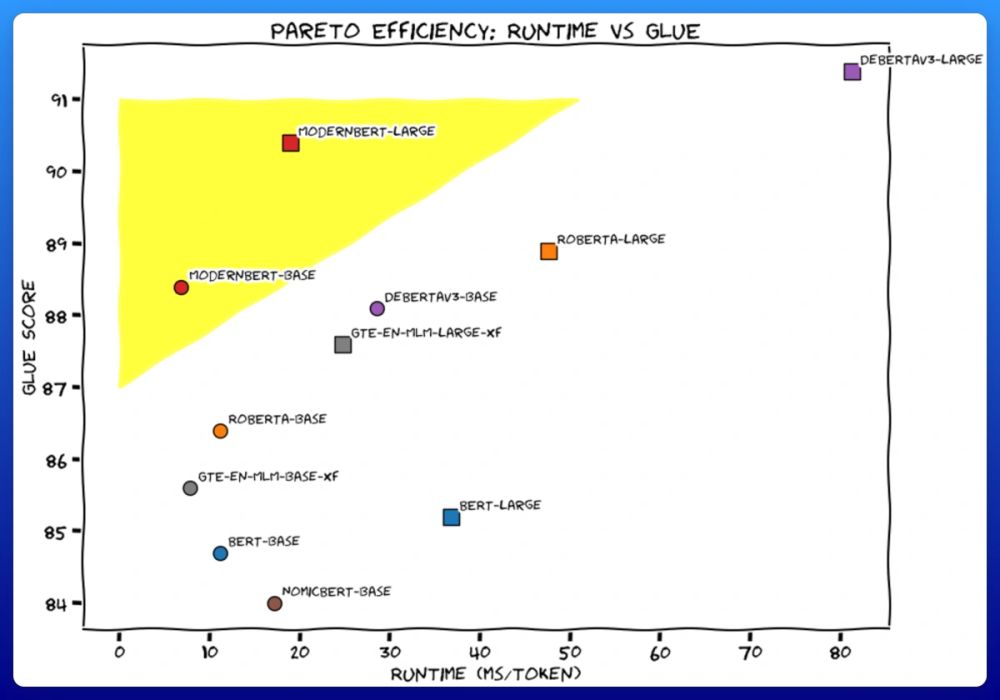
Check out our new encoder model, ModernBERT! 🤖
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 9:28 PM
Check out our new encoder model, ModernBERT! 🤖
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀
MASC is such a fun time! If your university is in the mid-Atlantic, please consider hosting!

📢 Want to host MASC 2025?
The 12th Mid-Atlantic Student Colloquium is a one day event bringing together students, faculty and researchers from universities and industry in the Mid-Atlantic.
Please submit this very short form if you are interested in hosting! Deadline January 6th. #MASC2025
The 12th Mid-Atlantic Student Colloquium is a one day event bringing together students, faculty and researchers from universities and industry in the Mid-Atlantic.
Please submit this very short form if you are interested in hosting! Deadline January 6th. #MASC2025
December 16, 2024 at 9:25 PM
MASC is such a fun time! If your university is in the mid-Atlantic, please consider hosting!
Reposted by Orion Weller

I'm looking for an intern to introduce Sparse Embedding models to Sentence Transformers! If you're passionate about open source, interested in helping practitioners use your tools, and enjoy embedders/retrievers/rerankers, then I'd love to hear from you!
Links with details and to apply in 🧵
Links with details and to apply in 🧵

November 27, 2024 at 2:31 PM
I'm looking for an intern to introduce Sparse Embedding models to Sentence Transformers! If you're passionate about open source, interested in helping practitioners use your tools, and enjoy embedders/retrievers/rerankers, then I'd love to hear from you!
Links with details and to apply in 🧵
Links with details and to apply in 🧵
Reposted by Orion Weller

I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
November 23, 2024 at 7:54 PM
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Creating a 🦋 starter pack for people working in IR/RAG: go.bsky.app/88ULgwY
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
November 23, 2024 at 9:19 PM
Creating a 🦋 starter pack for people working in IR/RAG: go.bsky.app/88ULgwY
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
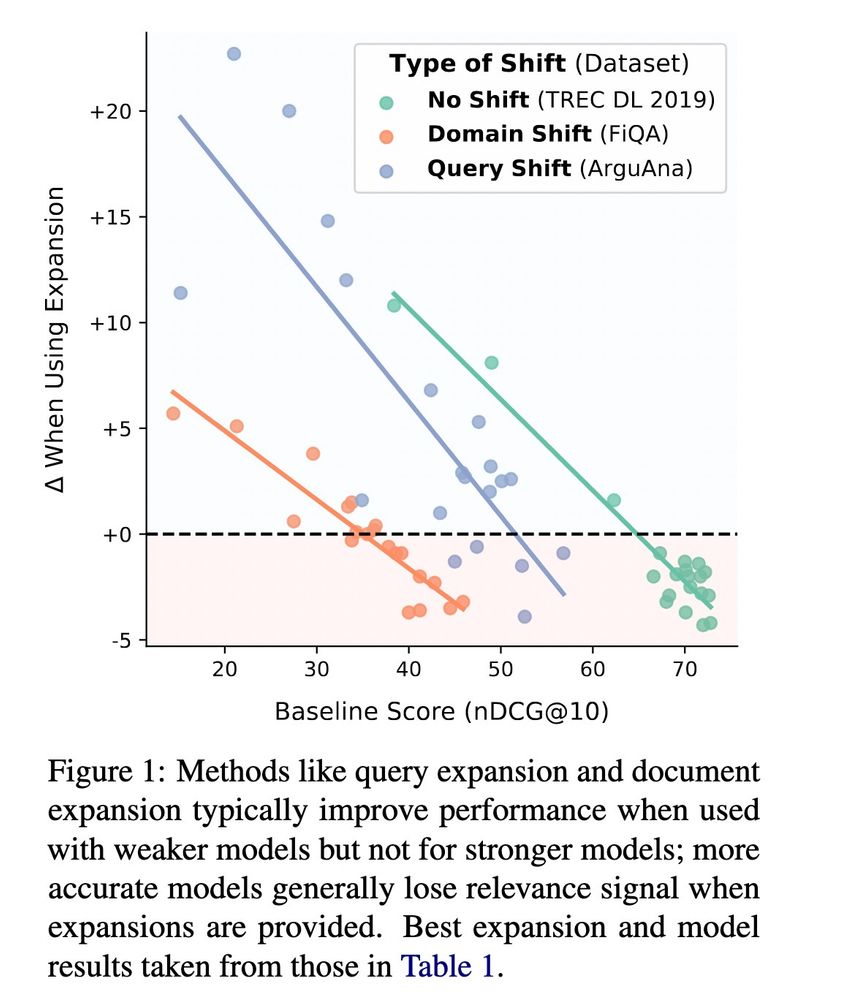
Using LLMs for query or document expansion in retrieval (e.g. HyDE and Doc2Query) have scores going 📈
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
November 18, 2024 at 10:30 AM
Using LLMs for query or document expansion in retrieval (e.g. HyDE and Doc2Query) have scores going 📈
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...