



Richard Bishop
@richardb.bsky.social
Distributed systems, databases, and the foundational primitives for better (more robust, efficient, accessible) computing.
Currently at Snowflake building managed Postgres. Formerly Crunchy Data and AWS.
Currently at Snowflake building managed Postgres. Formerly Crunchy Data and AWS.
Reposted by Richard Bishop

Five years ago I joined @crunchydata.com, shortly after I wrote about having unfinished business with Postgres. Today as part of Snowflake that journey is continuing. We've built some amazing things, but are just getting started.
www.crunchydata.com/blog/crunchy...
www.crunchydata.com/blog/crunchy...
Crunchy Data Joins Snowflake | Crunchy Data Blog
We are excited to announce that Crunchy Data is joining Snowflake to bring Postgres to the AI Data Cloud.
www.crunchydata.com
June 2, 2025 at 8:44 PM
Five years ago I joined @crunchydata.com, shortly after I wrote about having unfinished business with Postgres. Today as part of Snowflake that journey is continuing. We've built some amazing things, but are just getting started.
www.crunchydata.com/blog/crunchy...
www.crunchydata.com/blog/crunchy...
Reposted by Richard Bishop

A small issue in Amazon RDS for PostgreSQL: at the "Repeatable Read” isolation level, which in PostgreSQL normally means Snapshot Isolation, Amazon RDS for PostgreSQL clusters appear to exhibit Long Fork. We observed this behavior in healthy clusters, in versions ranging from 13.15 to 17.4 […]
Original post on mastodon.jepsen.io
mastodon.jepsen.io
April 29, 2025 at 2:31 PM
A small issue in Amazon RDS for PostgreSQL: at the "Repeatable Read” isolation level, which in PostgreSQL normally means Snapshot Isolation, Amazon RDS for PostgreSQL clusters appear to exhibit Long Fork. We observed this behavior in healthy clusters, in versions ranging from 13.15 to 17.4 […]
If you're using Postgres for your app data you can stop stitching together a myriad of ETL tools and analytics data stores and use one database for everything. This is both awesome and a lot of fun to use.
Today we're announcing the availability of logical replication from Postgres to Iceberg with Crunchy Data Warehouse.
Now you can seamlessly move data and stream changes from your operational database into an analytical system.
www.crunchydata.com/blog/logical...
Now you can seamlessly move data and stream changes from your operational database into an analytical system.
www.crunchydata.com/blog/logical...
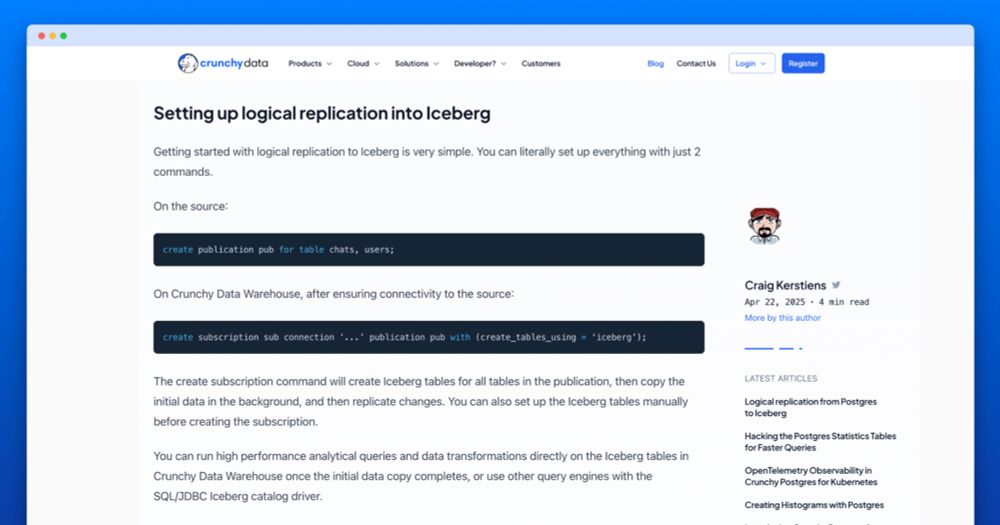
Logical replication from Postgres to Iceberg | Crunchy Data Blog
We've launched native logical replication from Postgres tables in any Postgres server to Iceberg tables managed by Crunchy Data Warehouse.
www.crunchydata.com
April 22, 2025 at 3:30 PM
If you're using Postgres for your app data you can stop stitching together a myriad of ETL tools and analytics data stores and use one database for everything. This is both awesome and a lot of fun to use.
People trying to use clusters of Mac Minis for AI reminds me of when SSDs first came out and people tried to use them for RAM
April 18, 2025 at 10:43 PM
People trying to use clusters of Mac Minis for AI reminds me of when SSDs first came out and people tried to use them for RAM
Is 10am on a Thursday the official newsletter time for tech companies? My inbox is getting blown up.
April 10, 2025 at 5:30 PM
Is 10am on a Thursday the official newsletter time for tech companies? My inbox is getting blown up.
Reposted by Richard Bishop
I got a number of questions on how we saved $30k a month on cloudwatch by moving logs directly to S3/Iceberg with Postgres so I wrote up how in a bit more detail - www.crunchydata.com/blog/reducin...
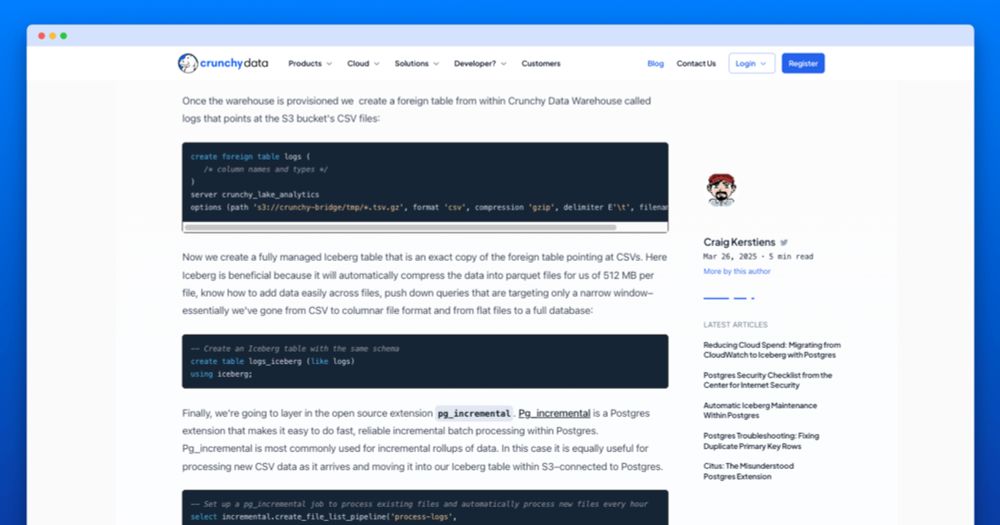
Reducing Cloud Spend: Migrating Logs from CloudWatch to Iceberg with Postgres | Crunchy Data Blog
How we migrated our internal logging for our database as a service, Crunchy Bridge, from CloudWatch to S3 with Iceberg and Postgres. The result was simplified logging management, better access with SQ...
www.crunchydata.com
March 26, 2025 at 5:59 PM
I got a number of questions on how we saved $30k a month on cloudwatch by moving logs directly to S3/Iceberg with Postgres so I wrote up how in a bit more detail - www.crunchydata.com/blog/reducin...
If you like coffee, computers, and power of 2 numbers then you'll also like my favorite pour over recipe:
16 grams of coffee
16:1 water to coffee ratio
Slowly pour 48mL (the pointer size on 64-bit platforms) of water every 45 seconds until you reach 256 total mL
16 grams of coffee
16:1 water to coffee ratio
Slowly pour 48mL (the pointer size on 64-bit platforms) of water every 45 seconds until you reach 256 total mL
March 10, 2025 at 5:58 PM
If you like coffee, computers, and power of 2 numbers then you'll also like my favorite pour over recipe:
16 grams of coffee
16:1 water to coffee ratio
Slowly pour 48mL (the pointer size on 64-bit platforms) of water every 45 seconds until you reach 256 total mL
16 grams of coffee
16:1 water to coffee ratio
Slowly pour 48mL (the pointer size on 64-bit platforms) of water every 45 seconds until you reach 256 total mL
The whole family is getting outfitted in Framework computers this christmas www.theverge.com/news/618785/...
February 25, 2025 at 9:16 PM
The whole family is getting outfitted in Framework computers this christmas www.theverge.com/news/618785/...
Fun high level overview on Meta's infrastructure approach. I enjoyed this bit about fault-tolerant commodity hardware, which AWS had to pivot on to expensive, more reliable hardware due to their customers not building fault-tolerant services. cacm.acm.org/research/met...

February 14, 2025 at 11:05 PM
Fun high level overview on Meta's infrastructure approach. I enjoyed this bit about fault-tolerant commodity hardware, which AWS had to pivot on to expensive, more reliable hardware due to their customers not building fault-tolerant services. cacm.acm.org/research/met...
Just typo'd AI agents as AI gnats in the context of some hucksters inflating their usage and I'm fine with leaving it that way
February 14, 2025 at 10:58 PM
Just typo'd AI agents as AI gnats in the context of some hucksters inflating their usage and I'm fine with leaving it that way
If I’m ever calling the shots someday our Dev Relations team will be tasked with improving the relationships between the engineers on the dev team and Dev Advocates will travel far and wide to tell tales of our epic conquests
February 6, 2025 at 11:10 PM
If I’m ever calling the shots someday our Dev Relations team will be tasked with improving the relationships between the engineers on the dev team and Dev Advocates will travel far and wide to tell tales of our epic conquests
A break through in ML efficiency was never going to come from a US company. The incentives, especially for Big Tech, aren't aligned with it. Constraints are a necessity for invention. This feels like the automotive industry handicapping the Japanese manufacturers all over again.
January 27, 2025 at 11:41 PM
A break through in ML efficiency was never going to come from a US company. The incentives, especially for Big Tech, aren't aligned with it. Constraints are a necessity for invention. This feels like the automotive industry handicapping the Japanese manufacturers all over again.
In a complete surprise to nobody, far more people are more concerned about Nvidia's stock price than are excited by a boon for deep learning.
January 27, 2025 at 11:31 PM
In a complete surprise to nobody, far more people are more concerned about Nvidia's stock price than are excited by a boon for deep learning.

There's something very satisfying about sshing into my home server from an airplane
December 17, 2024 at 7:18 PM
There's something very satisfying about sshing into my home server from an airplane
I wasn’t prepared for the MySQL and cloud references that are in Home Sweet Home Alone
December 13, 2024 at 2:43 AM
I wasn’t prepared for the MySQL and cloud references that are in Home Sweet Home Alone
Just to make sure I have this right:
For object storage AWS has S3 and CloudFlare has R2
For distributed SQL CloudFlare has D2 and AWS has D
For object storage AWS has S3 and CloudFlare has R2
For distributed SQL CloudFlare has D2 and AWS has D
December 3, 2024 at 10:58 PM
Just to make sure I have this right:
For object storage AWS has S3 and CloudFlare has R2
For distributed SQL CloudFlare has D2 and AWS has D
For object storage AWS has S3 and CloudFlare has R2
For distributed SQL CloudFlare has D2 and AWS has D
Reposted by Richard Bishop
"Postgres compatible"
- No views/triggers/sequences
- No foreign key constraints
- No extensions
- No NOTIFY ("ERROR: Function pg_notify not supported")
- No nested transactions
- No JSONB
What, what IS it compatible with?
- No views/triggers/sequences
- No foreign key constraints
- No extensions
- No NOTIFY ("ERROR: Function pg_notify not supported")
- No nested transactions
- No JSONB
What, what IS it compatible with?

December 3, 2024 at 7:31 PM
"Postgres compatible"
- No views/triggers/sequences
- No foreign key constraints
- No extensions
- No NOTIFY ("ERROR: Function pg_notify not supported")
- No nested transactions
- No JSONB
What, what IS it compatible with?
- No views/triggers/sequences
- No foreign key constraints
- No extensions
- No NOTIFY ("ERROR: Function pg_notify not supported")
- No nested transactions
- No JSONB
What, what IS it compatible with?
There should be nutrition labels for databases.
Ingredients: Paxos, NVMe drives, RDMA, epoll, blood, sweat, tears.
Packaged in a facility that contains clock skew and inter-zone networking charges.
Ingredients: Paxos, NVMe drives, RDMA, epoll, blood, sweat, tears.
Packaged in a facility that contains clock skew and inter-zone networking charges.
December 3, 2024 at 7:19 PM
There should be nutrition labels for databases.
Ingredients: Paxos, NVMe drives, RDMA, epoll, blood, sweat, tears.
Packaged in a facility that contains clock skew and inter-zone networking charges.
Ingredients: Paxos, NVMe drives, RDMA, epoll, blood, sweat, tears.
Packaged in a facility that contains clock skew and inter-zone networking charges.
Congrats to all involved in launching Amazon DSQL (AWS finally has a Spanner competitor!) but the marketing strikes me as a bit disingenuous:
"PostgreSQL compatible, offering a subset of PostgreSQL" != PostgreSQL compatible. YugaByte and Cockroach already made this mistake.
"PostgreSQL compatible, offering a subset of PostgreSQL" != PostgreSQL compatible. YugaByte and Cockroach already made this mistake.
December 3, 2024 at 7:15 PM
Congrats to all involved in launching Amazon DSQL (AWS finally has a Spanner competitor!) but the marketing strikes me as a bit disingenuous:
"PostgreSQL compatible, offering a subset of PostgreSQL" != PostgreSQL compatible. YugaByte and Cockroach already made this mistake.
"PostgreSQL compatible, offering a subset of PostgreSQL" != PostgreSQL compatible. YugaByte and Cockroach already made this mistake.
Active-active as a term has lost all meaning. Forwarding writes to a leader is not active-active, but quite a few databases do that and claim to be active-active.
The concern is really about write latency and the consequences of eschewing coordination to achieve latency goals.
The concern is really about write latency and the consequences of eschewing coordination to achieve latency goals.
December 3, 2024 at 5:54 PM
Active-active as a term has lost all meaning. Forwarding writes to a leader is not active-active, but quite a few databases do that and claim to be active-active.
The concern is really about write latency and the consequences of eschewing coordination to achieve latency goals.
The concern is really about write latency and the consequences of eschewing coordination to achieve latency goals.
Call me crazy but attempting to update the most pragmatic deployment philosophy with a design by committee of a gaggle of enterprise people, most which aren’t devs/SREs, probably isn’t going to be true to the spirit of the original 12factor.net/blog/open-so...
The Twelve-Factor App
A methodology for building modern, scalable, maintainable software-as-a-service apps.
12factor.net
December 3, 2024 at 4:20 PM
Call me crazy but attempting to update the most pragmatic deployment philosophy with a design by committee of a gaggle of enterprise people, most which aren’t devs/SREs, probably isn’t going to be true to the spirit of the original 12factor.net/blog/open-so...
Reposted by Richard Bishop

November 22, 2024 at 1:30 PM
Reposted by Richard Bishop
About a year ago, we set out to build a modern Postgres data warehouse at Crunchy Data.
Our principles were:
- Most data lives in S3
- @duckdb.org has the best query engine
- Iceberg will be the dominant table format
- No compromise on Postgres features
So, we built Crunchy Data Warehouse.
1/n
Our principles were:
- Most data lives in S3
- @duckdb.org has the best query engine
- Iceberg will be the dominant table format
- No compromise on Postgres features
So, we built Crunchy Data Warehouse.
1/n
Announcing Crunchy Data Warehouse! A next-generation Postgres-native data warehouse that provides full Iceberg support for fast analytical queries and transactions.Read more in our announcement. www.crunchydata.com/blog/crunchy...

Crunchy Data Warehouse: Postgres with Iceberg for High Performance Analytics | Crunchy Data Blog
We are excited to release Crunchy Data Warehouse, a modern data warehouse for Postgres. Crunchy Data Warehouse combines Postgres with Iceberg, Parquet, and data lake formats for fast analytics queries...
www.crunchydata.com
November 20, 2024 at 3:08 PM
About a year ago, we set out to build a modern Postgres data warehouse at Crunchy Data.
Our principles were:
- Most data lives in S3
- @duckdb.org has the best query engine
- Iceberg will be the dominant table format
- No compromise on Postgres features
So, we built Crunchy Data Warehouse.
1/n
Our principles were:
- Most data lives in S3
- @duckdb.org has the best query engine
- Iceberg will be the dominant table format
- No compromise on Postgres features
So, we built Crunchy Data Warehouse.
1/n
Reposted by Richard Bishop

Announcing Crunchy Data Warehouse! A next-generation Postgres-native data warehouse that provides full Iceberg support for fast analytical queries and transactions.Read more in our announcement. www.crunchydata.com/blog/crunchy...
Crunchy Data Warehouse: Postgres with Iceberg for High Performance Analytics | Crunchy Data Blog
We are excited to release Crunchy Data Warehouse, a modern data warehouse for Postgres. Crunchy Data Warehouse combines Postgres with Iceberg, Parquet, and data lake formats for fast analytics queries...
www.crunchydata.com
November 20, 2024 at 2:45 PM
Announcing Crunchy Data Warehouse! A next-generation Postgres-native data warehouse that provides full Iceberg support for fast analytical queries and transactions.Read more in our announcement. www.crunchydata.com/blog/crunchy...