
AlgoPerf
@algoperf.bsky.social
34 followers
15 following
12 posts
AlgoPerf benchmark for faster neural network training via better training algorithms
Posts
Media
Videos
Starter Packs

AlgoPerf
@algoperf.bsky.social
· Sep 8

GitHub - mlcommons/algorithmic-efficiency: MLCommons Algorithmic Efficiency is a benchmark and competition measuring neural network training speedups due to algorithmic improvements in both training a...
MLCommons Algorithmic Efficiency is a benchmark and competition measuring neural network training speedups due to algorithmic improvements in both training algorithms and models. - mlcommons/algori...
github.com

AlgoPerf
@algoperf.bsky.social
· Apr 3

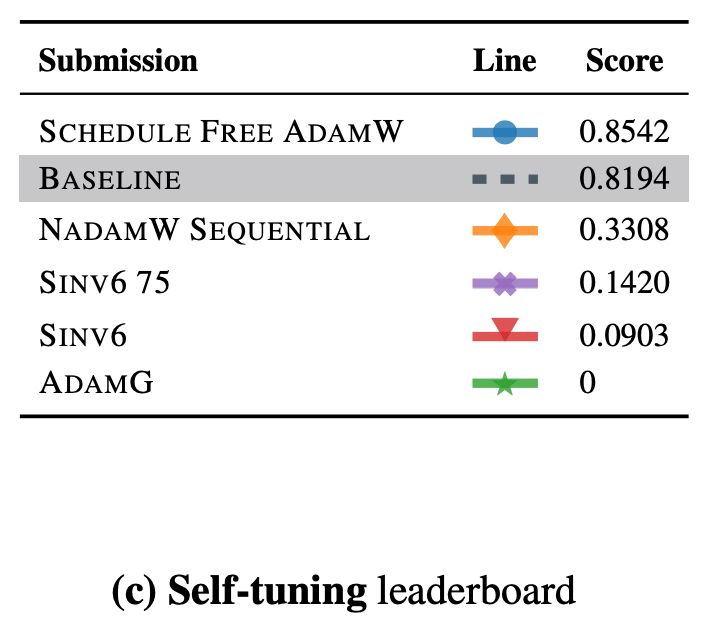
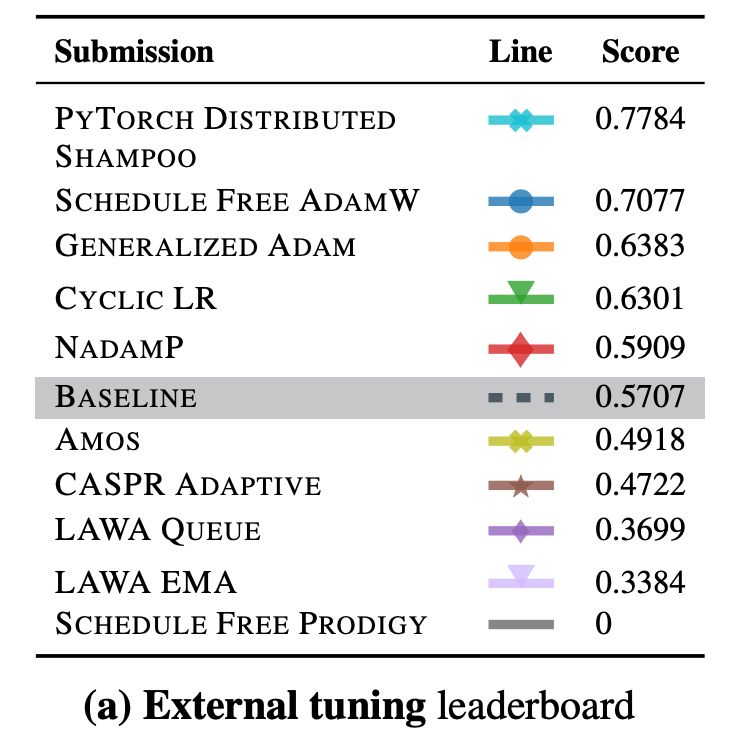
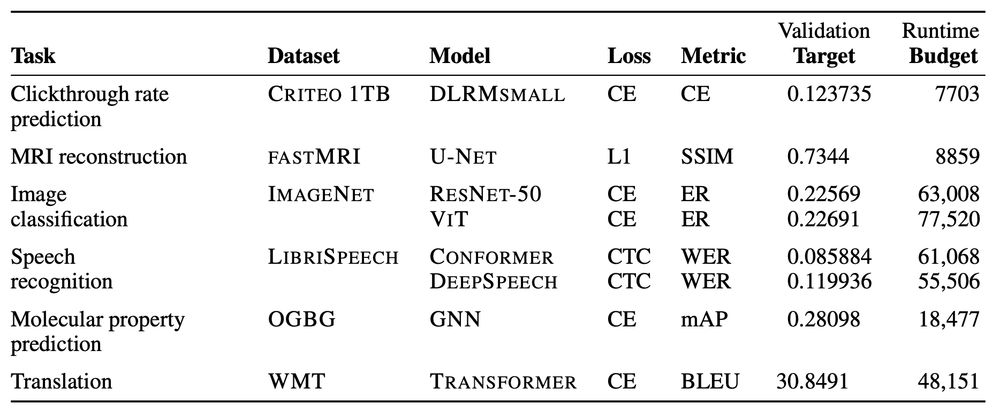
AlgoPerf
@algoperf.bsky.social
· Mar 14
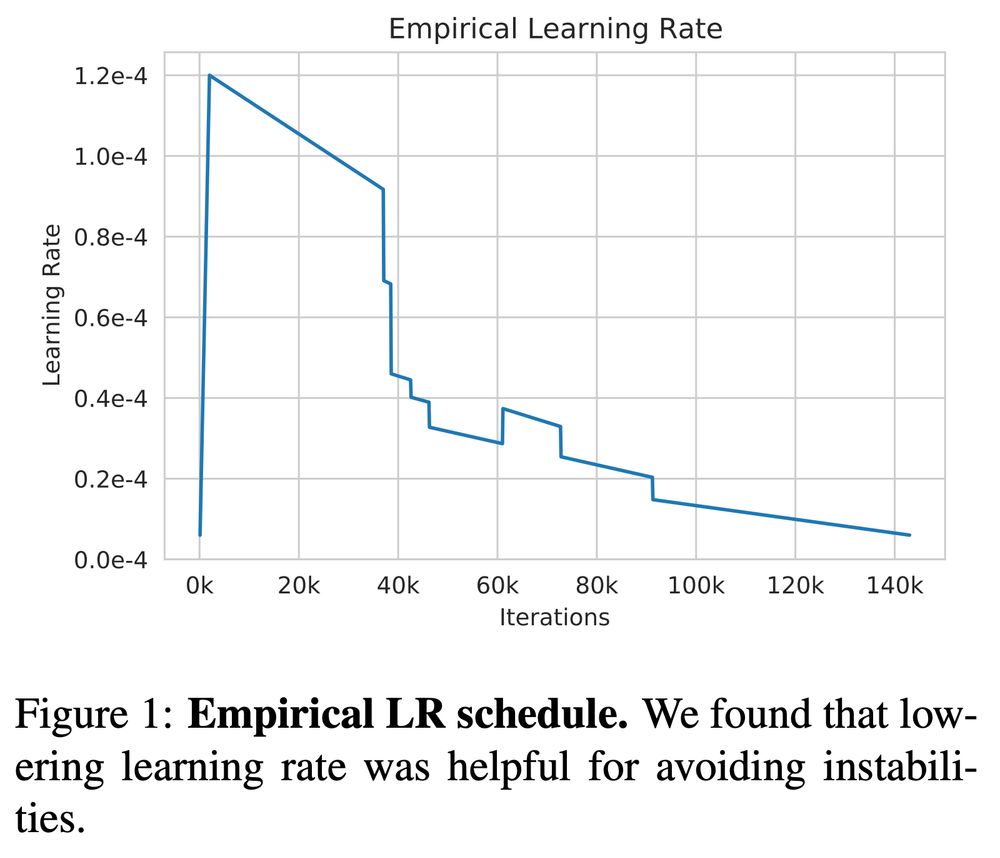
AlgoPerf
@algoperf.bsky.social
· Mar 14