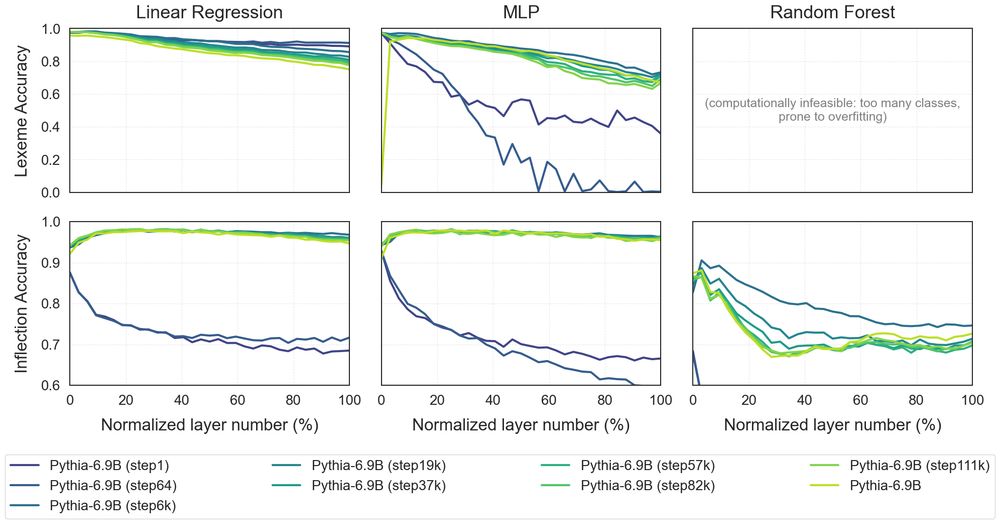
🎯 These patterns hold across all 16 models - despite huge differences (encoder/decoder, 100M->8B params, instruction-tuning)
Despite rapid advances since BERT, certain aspects of how LMs process language remain remarkably consistent💡
Paper:
arxiv.org/abs/2506.02132Code:
github.com/ml5885/model...