



@craigmacdonald.bsky.social
6/7. Another cool addition by
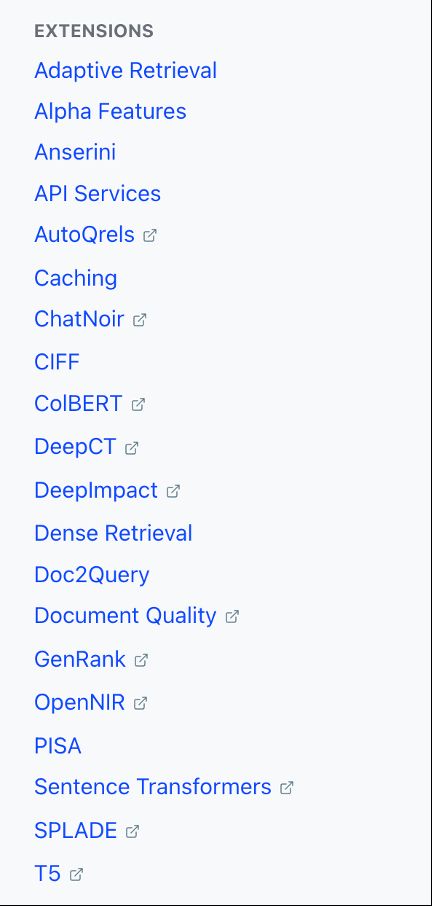
@macavaney.bsky.social: integrating PyTerrier extension docs into pyterrier.readthedocs.io, including as pyterrier_dr (dense retrieval), pyterrier_doc2query, pyterrier_pisa etc. One place now has a full list of lots of SOTA extensions for retrieval.
@macavaney.bsky.social: integrating PyTerrier extension docs into pyterrier.readthedocs.io, including as pyterrier_dr (dense retrieval), pyterrier_doc2query, pyterrier_pisa etc. One place now has a full list of lots of SOTA extensions for retrieval.
December 19, 2024 at 1:14 PM
6/7. Another cool addition by
@macavaney.bsky.social: integrating PyTerrier extension docs into pyterrier.readthedocs.io, including as pyterrier_dr (dense retrieval), pyterrier_doc2query, pyterrier_pisa etc. One place now has a full list of lots of SOTA extensions for retrieval.
@macavaney.bsky.social: integrating PyTerrier extension docs into pyterrier.readthedocs.io, including as pyterrier_dr (dense retrieval), pyterrier_doc2query, pyterrier_pisa etc. One place now has a full list of lots of SOTA extensions for retrieval.
5/7.
@macavaney.bsky.social
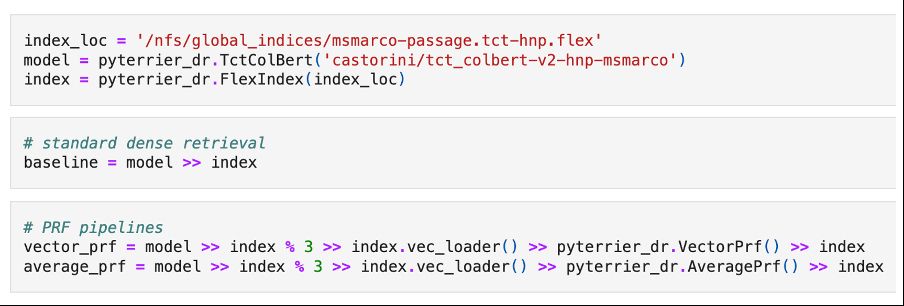
has been polishing pyterrier_dr (github.com/terrierteam/...) – our single-vector Dense Retrieval framework, for instance including PRF:
@macavaney.bsky.social
has been polishing pyterrier_dr (github.com/terrierteam/...) – our single-vector Dense Retrieval framework, for instance including PRF:
December 19, 2024 at 1:14 PM
5/7.
@macavaney.bsky.social
has been polishing pyterrier_dr (github.com/terrierteam/...) – our single-vector Dense Retrieval framework, for instance including PRF:
@macavaney.bsky.social
has been polishing pyterrier_dr (github.com/terrierteam/...) – our single-vector Dense Retrieval framework, for instance including PRF:
4/7. A complete rework of pipeline compilation by
@macavaney.bsky.social. PyTerrier compilation rewrites a pipeline by, e.g. applying rank cutoff earlier. So these two pipelines are equivalent, but potentially faster – .compile() allows that optimisation to happen automatically
@macavaney.bsky.social. PyTerrier compilation rewrites a pipeline by, e.g. applying rank cutoff earlier. So these two pipelines are equivalent, but potentially faster – .compile() allows that optimisation to happen automatically

December 19, 2024 at 1:14 PM
4/7. A complete rework of pipeline compilation by
@macavaney.bsky.social. PyTerrier compilation rewrites a pipeline by, e.g. applying rank cutoff earlier. So these two pipelines are equivalent, but potentially faster – .compile() allows that optimisation to happen automatically
@macavaney.bsky.social. PyTerrier compilation rewrites a pipeline by, e.g. applying rank cutoff earlier. So these two pipelines are equivalent, but potentially faster – .compile() allows that optimisation to happen automatically
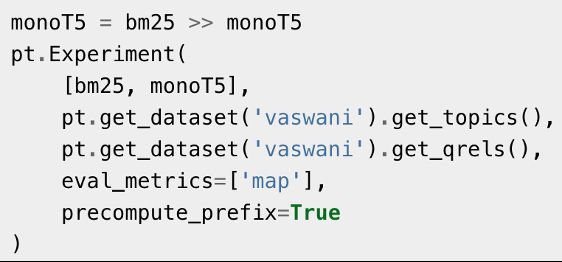
3/7. Precomputation of common pipeline prefixes is something really 😎. For this example experiment comparing BM25 with BM25 >> monoT5, this means that only one BM25 retrieval is needed to evaluate both pipelines. Great for speeding up comparative experiments on large query sets!
December 19, 2024 at 1:14 PM
3/7. Precomputation of common pipeline prefixes is something really 😎. For this example experiment comparing BM25 with BM25 >> monoT5, this means that only one BM25 retrieval is needed to evaluate both pipelines. Great for speeding up comparative experiments on large query sets!
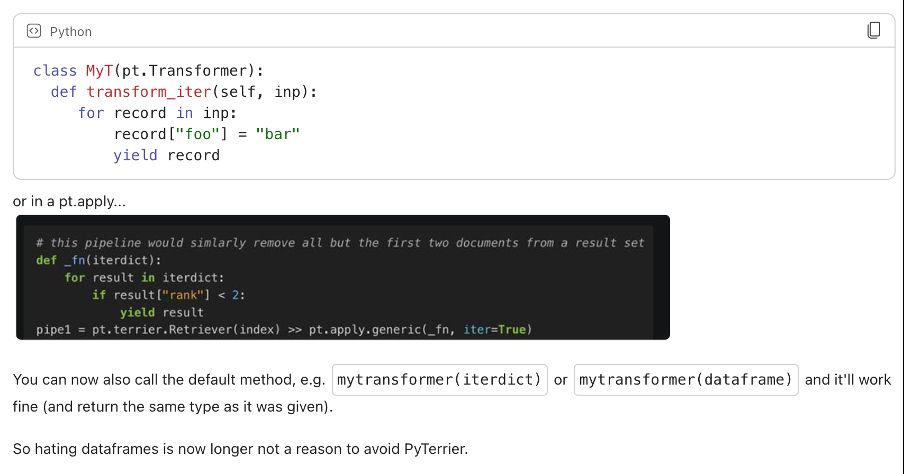
2/7. Making transform_iter() into a first-class citizen of pt.Transformer – no need to manipulate dataframes – you can now write transformers that operate on a list of dicts. This (backwards compatible) change is big news as PyTerrier has been dataframe based from the outset.
December 19, 2024 at 1:14 PM
2/7. Making transform_iter() into a first-class citizen of pt.Transformer – no need to manipulate dataframes – you can now write transformers that operate on a list of dicts. This (backwards compatible) change is big news as PyTerrier has been dataframe based from the outset.