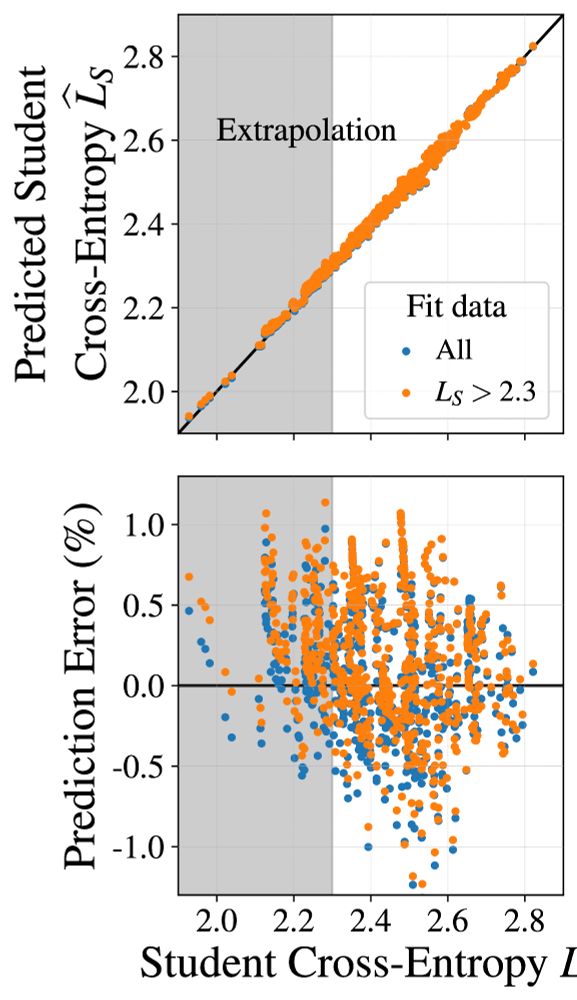
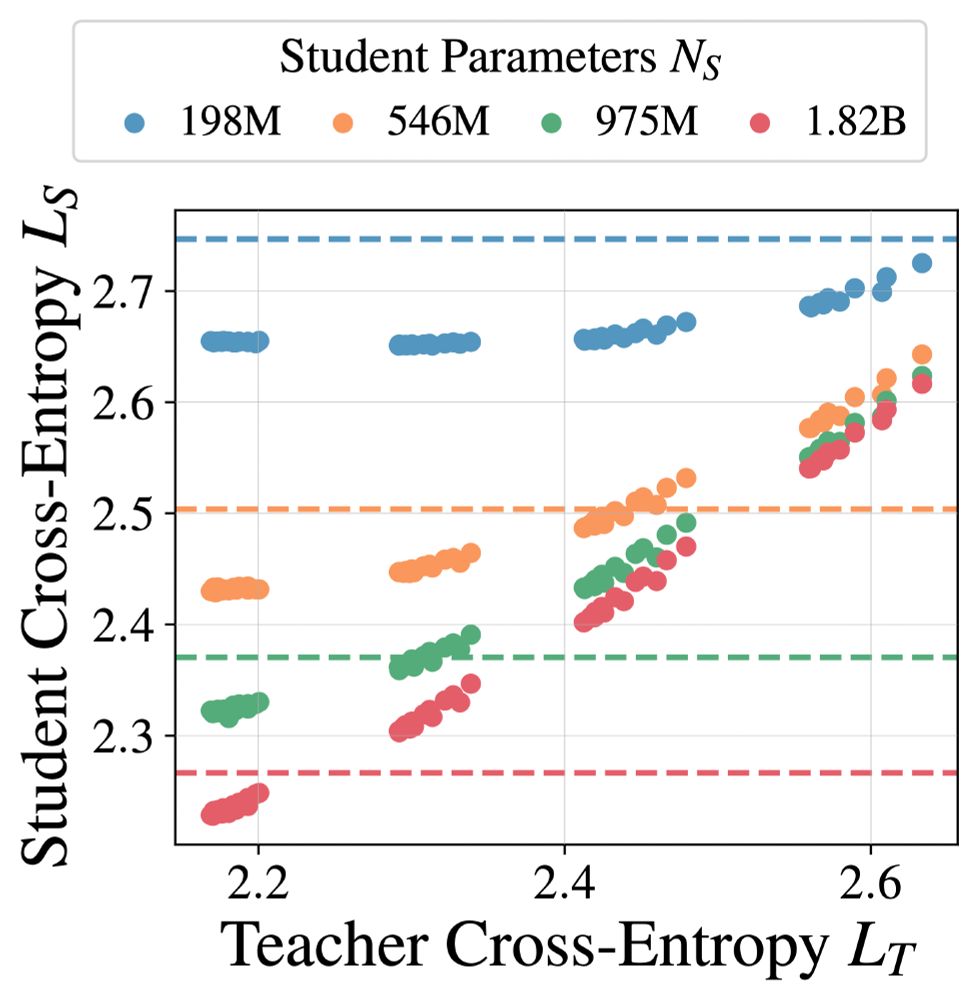
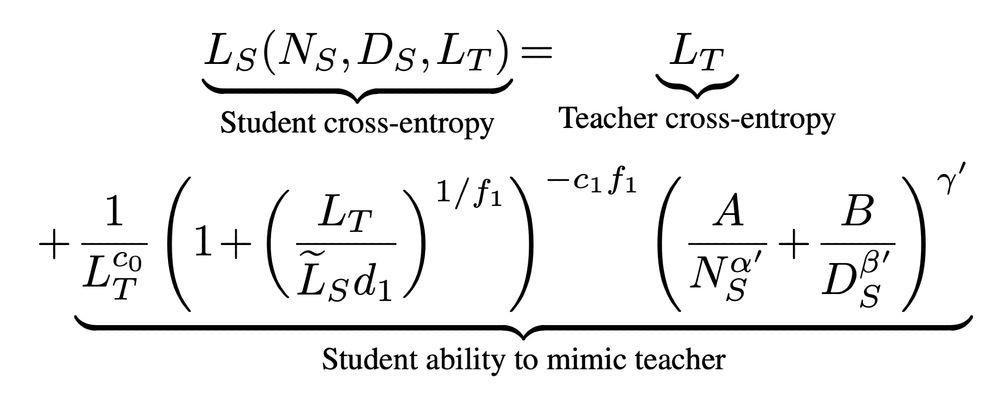
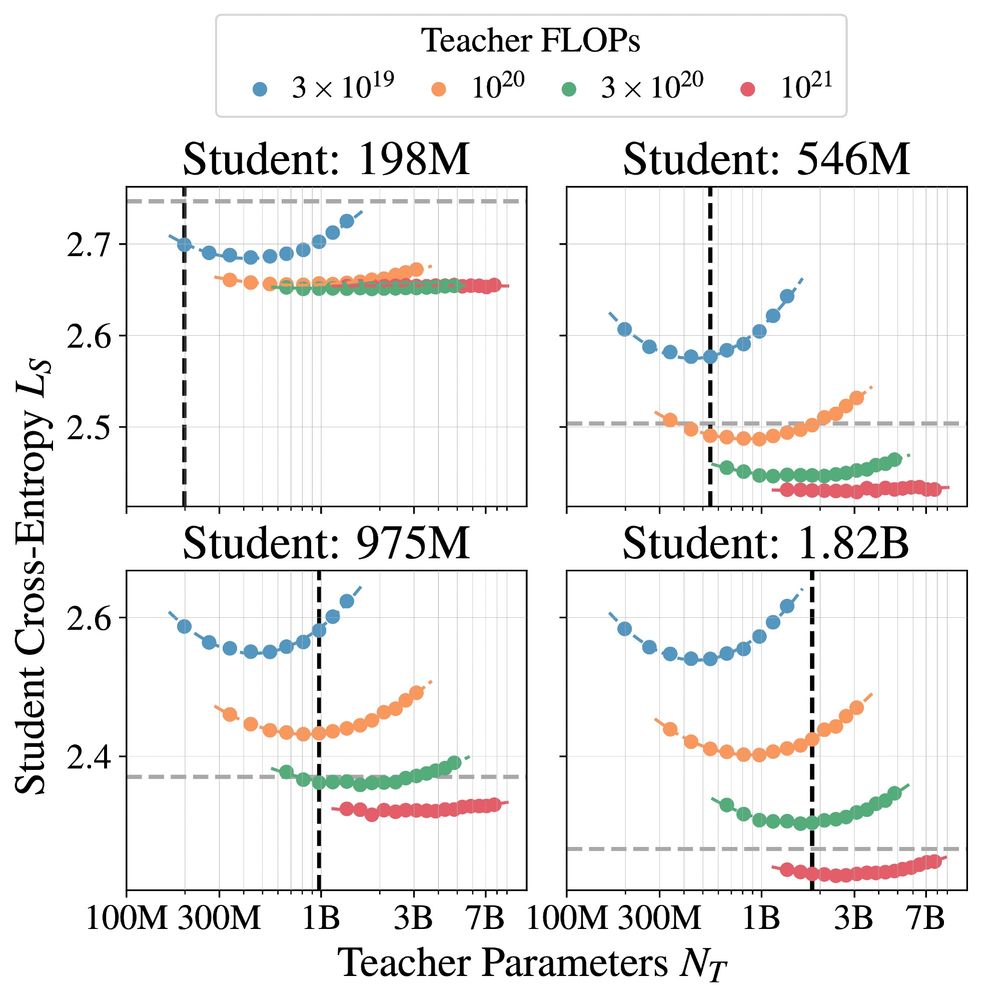
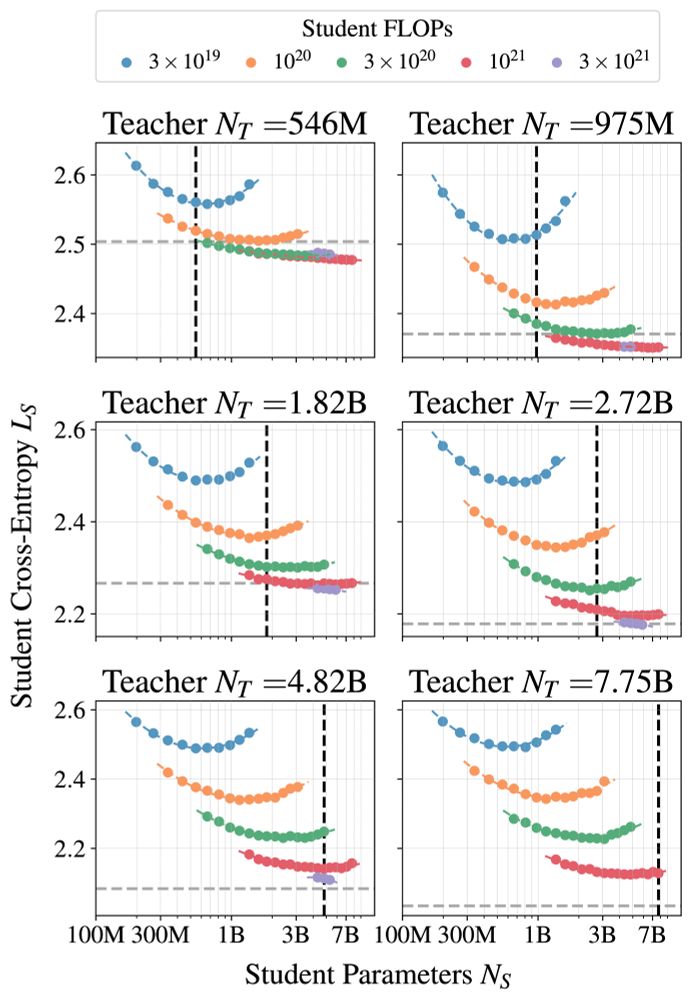
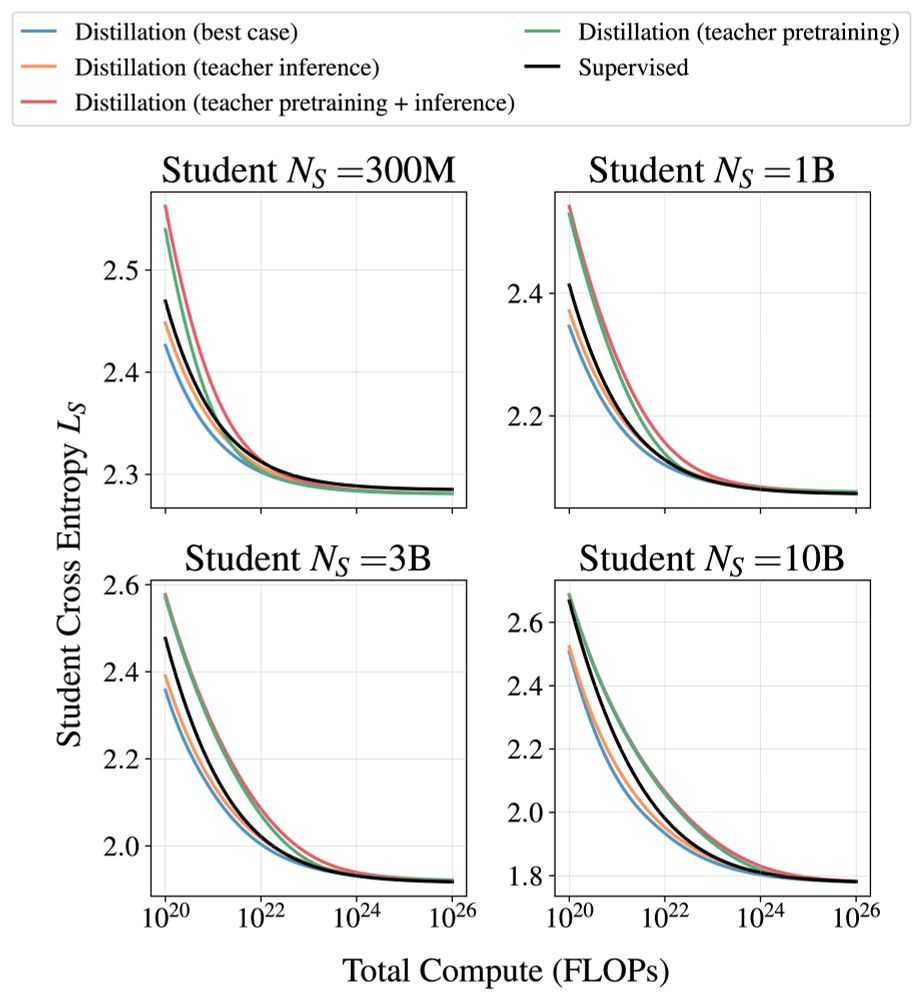
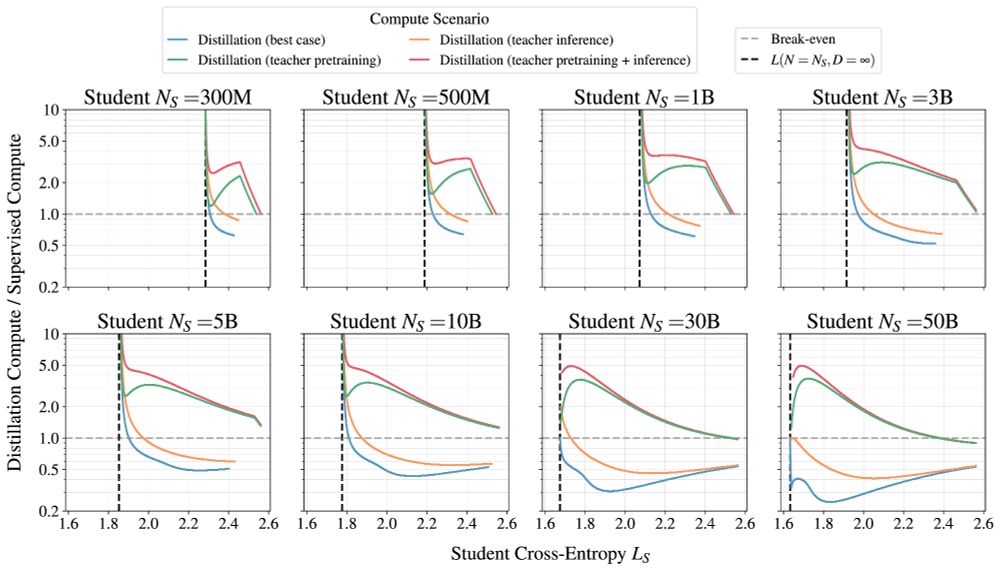
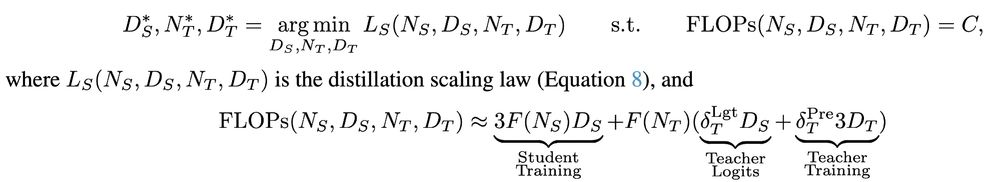Dan Busbridge
@dbusbridge.bsky.social
34 followers
61 following
21 posts
Machine Learning Research @ Apple (opinions are my own)
Posts
Media
Videos
Starter Packs


Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
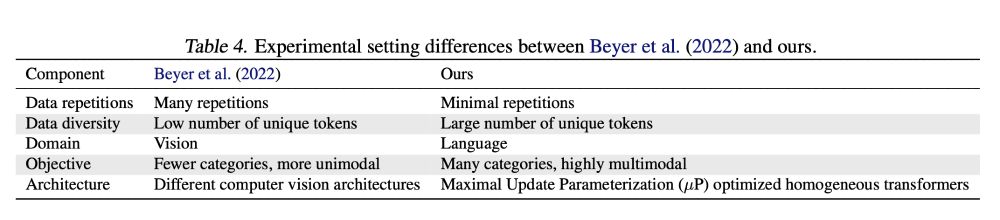
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13
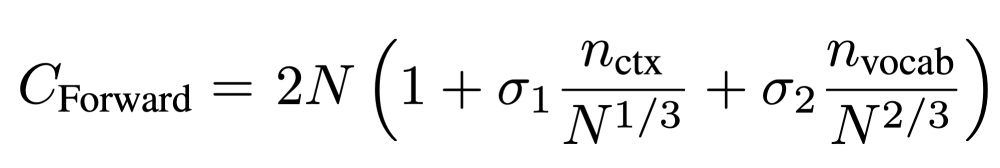
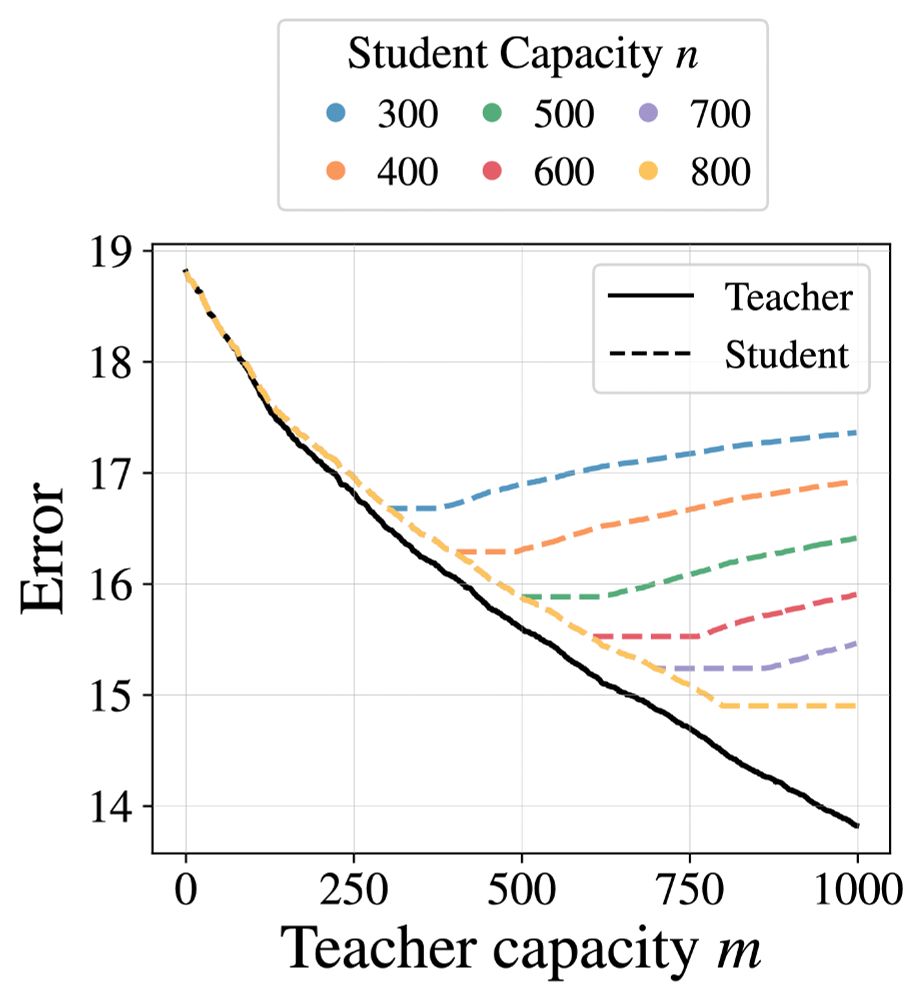
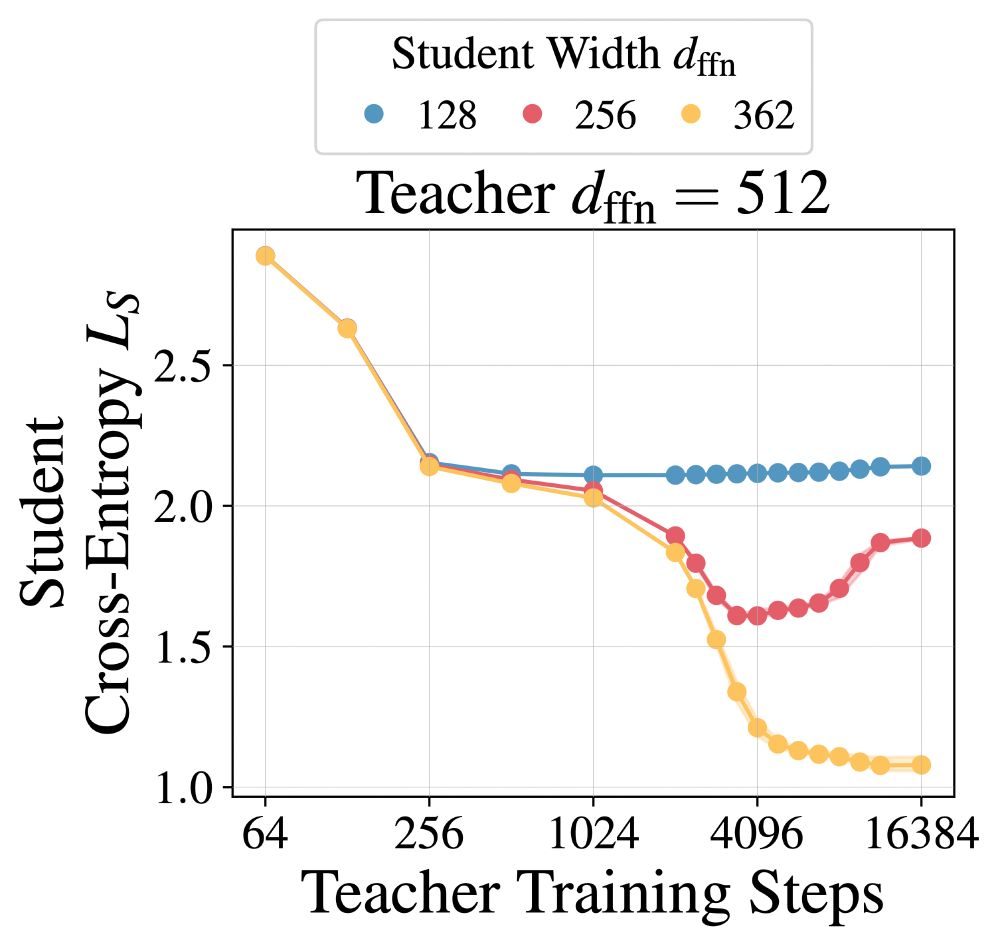
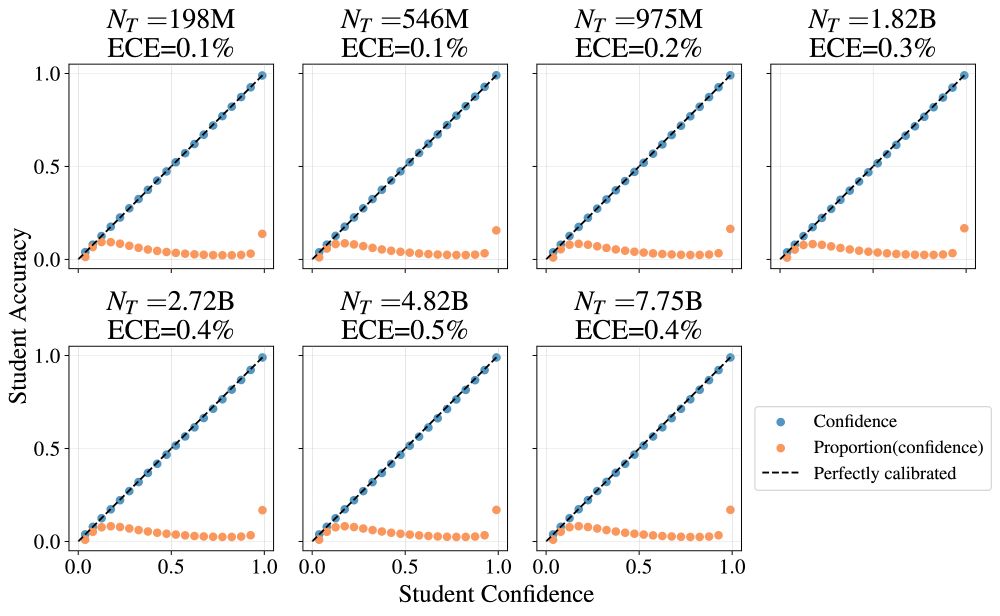
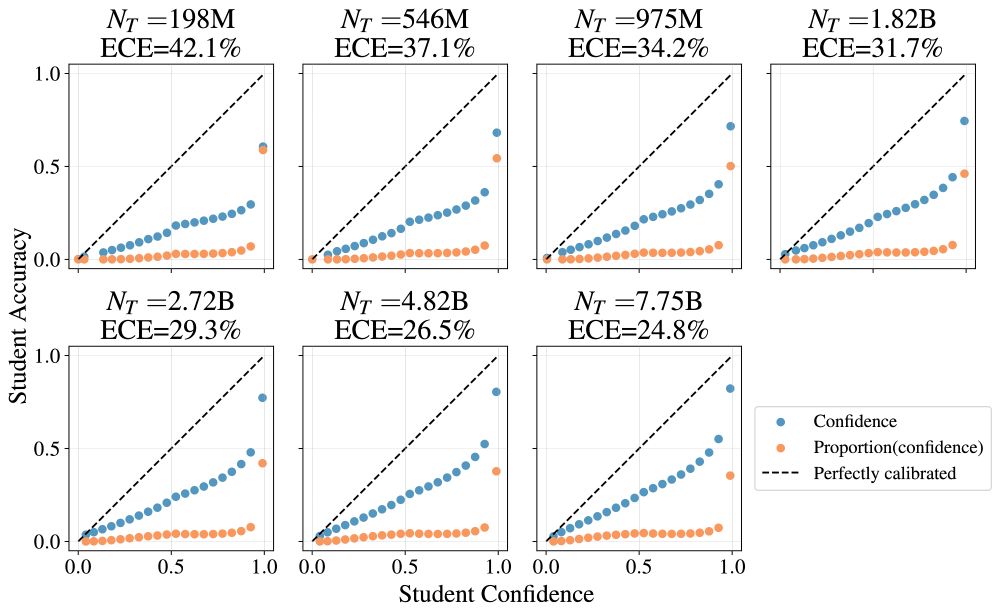
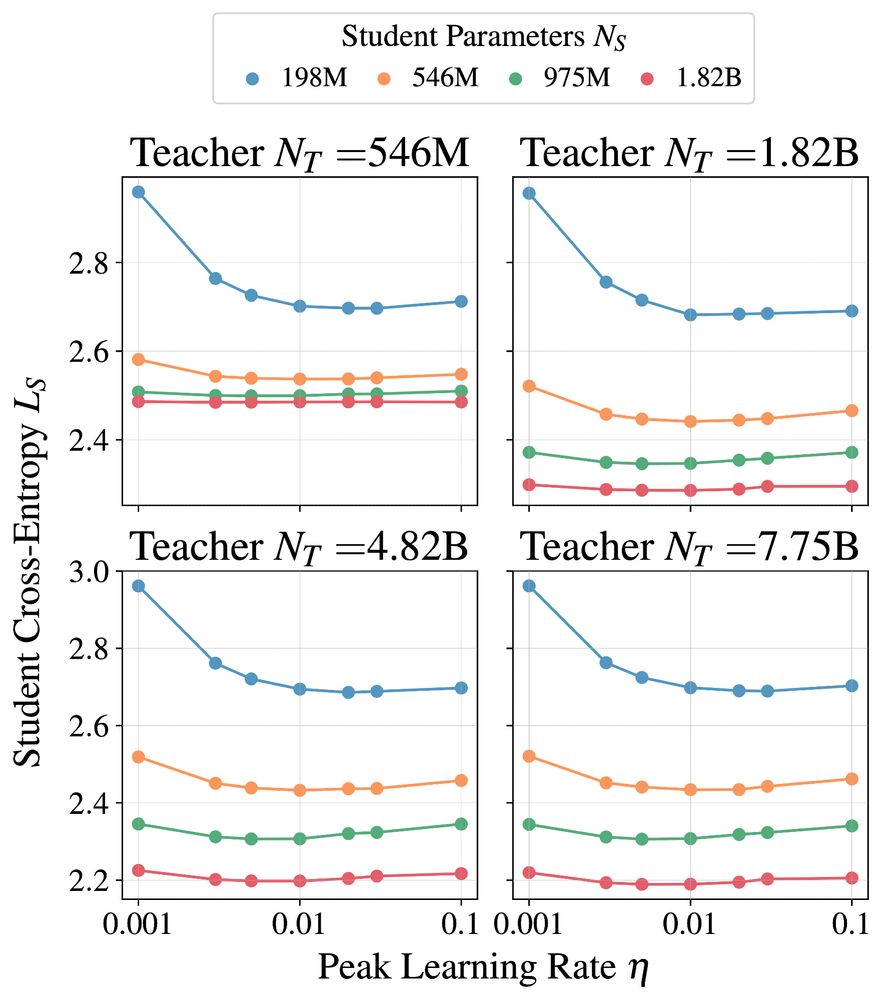
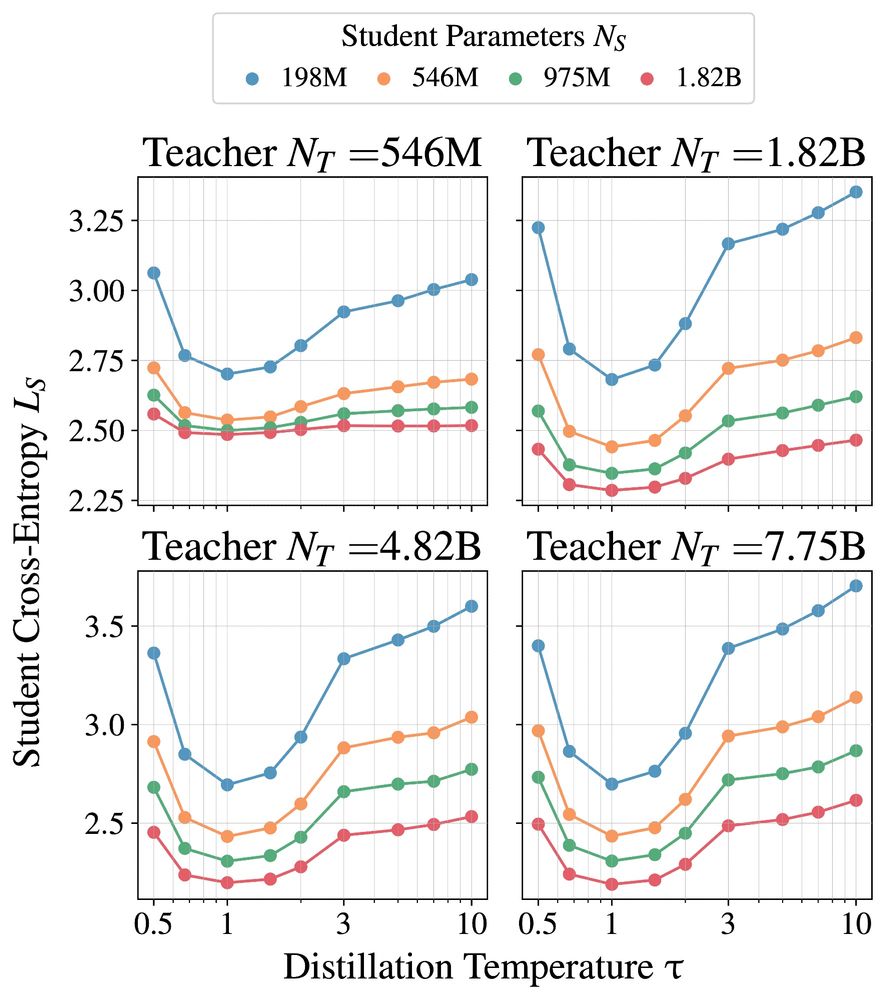
Dan Busbridge
@dbusbridge.bsky.social
· Feb 13