


Derek Lewis
@dlewis.io
CTO & Data Scientist at Silex Data Solutions & CODEHR.ai. Opinions expressed are my own.
Writing emulators is a good way to learn about hardware, which is something that I haven't spent much time on previously. Just finished up a basic Chip8 emulator in Python that can do instruction decoding and B/W screen drawing. TBDs still include keyboard input & sound. github.com/derekelewis/...
GitHub - derekelewis/Chip8
Contribute to derekelewis/Chip8 development by creating an account on GitHub.
github.com
November 11, 2025 at 10:57 PM
Writing emulators is a good way to learn about hardware, which is something that I haven't spent much time on previously. Just finished up a basic Chip8 emulator in Python that can do instruction decoding and B/W screen drawing. TBDs still include keyboard input & sound. github.com/derekelewis/...
Having a hard time seeing the difference between Tinted and Clear for Liquid Glass with macOS 26.1 in Safari.
November 3, 2025 at 10:54 PM
Having a hard time seeing the difference between Tinted and Clear for Liquid Glass with macOS 26.1 in Safari.
You probably wouldn't know it from this top output, but I have a FSDP training run going on the DGX Spark cluster. No wasted CPU time spent processing interrupts or copying between buffers. RDMA networking is a wonderful thing.

October 31, 2025 at 10:45 PM
You probably wouldn't know it from this top output, but I have a FSDP training run going on the DGX Spark cluster. No wasted CPU time spent processing interrupts or copying between buffers. RDMA networking is a wonderful thing.
2x performance by adding the 2nd DGX Spark w/ the 200GbE interconnect to a distributed training run with Karpathy's nanochat. Brings base training down from 10 days to 5 days. Token throughput is 4x compared to single node run, but only because grad accumulated steps changed from 8 to 4.

October 31, 2025 at 8:48 PM
2x performance by adding the 2nd DGX Spark w/ the 200GbE interconnect to a distributed training run with Karpathy's nanochat. Brings base training down from 10 days to 5 days. Token throughput is 4x compared to single node run, but only because grad accumulated steps changed from 8 to 4.
200GbE network is up and running between the DGX Sparks. Having a high throughput cluster on a desk that consumes less than 400W of power under full load is awesome. NCCL benchmarks show near line-speed for AllGather.


October 31, 2025 at 4:32 PM
200GbE network is up and running between the DGX Sparks. Having a high throughput cluster on a desk that consumes less than 400W of power under full load is awesome. NCCL benchmarks show near line-speed for AllGather.
Waiting for a 200GbE interconnect cable to come in to connect my NVIDIA DGX Sparks. Did some NCCL connectivity and validation testing with the 10GbE ports in the meantime:

October 30, 2025 at 10:37 PM
Waiting for a 200GbE interconnect cable to come in to connect my NVIDIA DGX Sparks. Did some NCCL connectivity and validation testing with the 10GbE ports in the meantime:
NVIDIA DGX Spark #2 is up and running.

October 30, 2025 at 7:20 PM
NVIDIA DGX Spark #2 is up and running.
Womp womp - looks like NVIDIA NIM images aren't updated to CUDA 13.1, yet. That means no NIM on the DGX Spark for the time being except for a few custom images they have done. Unfortunate, because I really wanted to see mxfp4 & trt-llm w/ gpt-oss-120b.


October 29, 2025 at 5:40 PM
Womp womp - looks like NVIDIA NIM images aren't updated to CUDA 13.1, yet. That means no NIM on the DGX Spark for the time being except for a few custom images they have done. Unfortunate, because I really wanted to see mxfp4 & trt-llm w/ gpt-oss-120b.
Long context llama.cpp testing with the NVIDIA DGX Spark & gpt-oss-120b.

October 28, 2025 at 7:03 PM
Long context llama.cpp testing with the NVIDIA DGX Spark & gpt-oss-120b.
For anyone that is curious @karpathy.bsky.social's nanochat takes around 10 days for base training on a NVIDIA DGX Spark (~1600 tok/s). Will benchmark again when I get the 2nd DGX to see how linear the scaling is.
October 27, 2025 at 12:00 PM
For anyone that is curious @karpathy.bsky.social's nanochat takes around 10 days for base training on a NVIDIA DGX Spark (~1600 tok/s). Will benchmark again when I get the 2nd DGX to see how linear the scaling is.
NVIDIA DGX Spark is up and running. Setup process was seamless. Now for some fine-tuning and CUDA development.

October 27, 2025 at 2:11 AM
NVIDIA DGX Spark is up and running. Setup process was seamless. Now for some fine-tuning and CUDA development.
Tried to make the switch to Chrome again from Safari. Passwords integration in Safari is the issue, and the Chrome plugin isn't great. Was a 1Password customer for years, but family is now fully on Passwords.
October 19, 2025 at 3:36 PM
Tried to make the switch to Chrome again from Safari. Passwords integration in Safari is the issue, and the Chrome plugin isn't great. Was a 1Password customer for years, but family is now fully on Passwords.
Made the plunge and ordered a DGX Spark. Less interested in the inferencing performance and more interested in having the full Nvidia DGX stack on my desk for development.

October 17, 2025 at 9:10 PM
Made the plunge and ordered a DGX Spark. Less interested in the inferencing performance and more interested in having the full Nvidia DGX stack on my desk for development.
Somehow just discovered @netnewswire.com and using it as my RSS reader going forward. There's something to be said for an app that is just an app and not a service.
October 12, 2025 at 12:32 AM
Somehow just discovered @netnewswire.com and using it as my RSS reader going forward. There's something to be said for an app that is just an app and not a service.
Experimenting to see if I can use scheduled tasks in ChatGPT & Gemini to replace my RSS reader agent that scrapes blogs, summarizes, and publishes via webhook.
October 4, 2025 at 6:12 PM
Experimenting to see if I can use scheduled tasks in ChatGPT & Gemini to replace my RSS reader agent that scrapes blogs, summarizes, and publishes via webhook.
Native containers in macOS 26 are lightweight & functional. No more Docker or Podman VMs required.
July 9, 2025 at 9:55 PM
Native containers in macOS 26 are lightweight & functional. No more Docker or Podman VMs required.
Worked with a customer on LLM infra sizing—here’s a deep dive on llama-3.3-70b-instruct inference using NVIDIA NIM.
H100 (SXM5) delivered up to 14× more throughput vs A100 (PCIe) with far lower latency.
Full benchmarks + thoughts:
dlewis.io/evaluating-l...
H100 (SXM5) delivered up to 14× more throughput vs A100 (PCIe) with far lower latency.
Full benchmarks + thoughts:
dlewis.io/evaluating-l...
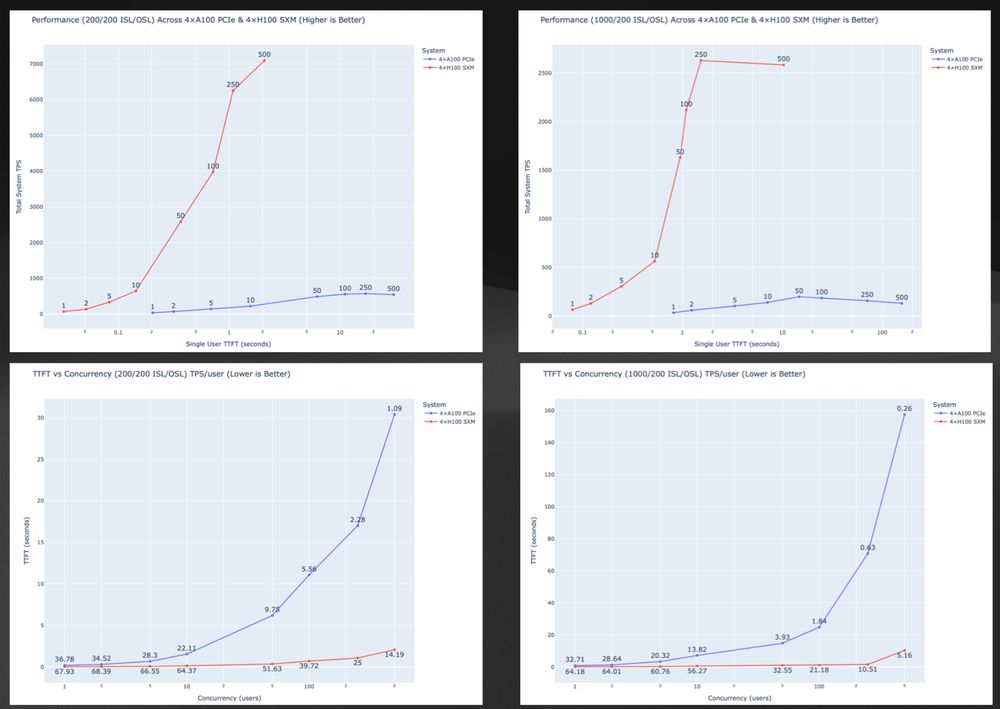
Evaluating Llama‑3.3‑70B Inference on NVIDIA H100 and A100 GPUs
Large‑scale language models quickly expose the limits of yesterday’s hardware. To understand how much practical head‑room Hopper offers over Ampere in a production‑style setting, I profiled llama-3.3-...
dlewis.io
April 17, 2025 at 6:27 PM
Worked with a customer on LLM infra sizing—here’s a deep dive on llama-3.3-70b-instruct inference using NVIDIA NIM.
H100 (SXM5) delivered up to 14× more throughput vs A100 (PCIe) with far lower latency.
Full benchmarks + thoughts:
dlewis.io/evaluating-l...
H100 (SXM5) delivered up to 14× more throughput vs A100 (PCIe) with far lower latency.
Full benchmarks + thoughts:
dlewis.io/evaluating-l...
Had to remind myself today that bfloat16 on Apple Silicon in PyTorch with AMP provides a minimal performance increase for model training or inferencing. It is very beneficial on NVIDIA GPUs because of Tensor Cores, which PyTorch uses for bfloat16 matmuls.
April 16, 2025 at 10:26 PM
Had to remind myself today that bfloat16 on Apple Silicon in PyTorch with AMP provides a minimal performance increase for model training or inferencing. It is very beneficial on NVIDIA GPUs because of Tensor Cores, which PyTorch uses for bfloat16 matmuls.
Wanted to share some of my recent experiences debugging a real-world problem with LLMs. Problem complexity is an issue for some models. Reasoning models fare better. dlewis.io/recent-exper...
Recent Experiences Debugging with LLMs
I’m frequently asked by clients what my thoughts are on LLMs and coding. Personal experience has informed me that LLMs cannot solve problems of a certain complexity for a number of reasons. One of the...
dlewis.io
April 16, 2025 at 8:17 PM
Wanted to share some of my recent experiences debugging a real-world problem with LLMs. Problem complexity is an issue for some models. Reasoning models fare better. dlewis.io/recent-exper...
While fixing a KV Cache generation bug today in the MLX GPT-2 implementation that I submitted last year, I discovered that the gpt2 (128M) model is much more dependent on positional encodings than the larger gpt2-xl (1.5B). Guess that explains why linear positional encoding layers were dropped.
April 14, 2025 at 2:04 AM
While fixing a KV Cache generation bug today in the MLX GPT-2 implementation that I submitted last year, I discovered that the gpt2 (128M) model is much more dependent on positional encodings than the larger gpt2-xl (1.5B). Guess that explains why linear positional encoding layers were dropped.
Qwen2.5 models are exceptionally strong at tool calling for their size. Definitely stronger than the Llama 3.1/3.2 models.
March 18, 2025 at 2:21 AM
Qwen2.5 models are exceptionally strong at tool calling for their size. Definitely stronger than the Llama 3.1/3.2 models.
We’re excited to announce the open sourcing of our AI Foundry Starter Template at Silex Data! This production-ready starter kit empowers you to build and deploy AI apps with LangChainAI/LangGraph, featuring streaming chat, robust Keycloak authentication, Kong's multi-model gateway, and OpenShift.
March 12, 2025 at 7:36 PM
We’re excited to announce the open sourcing of our AI Foundry Starter Template at Silex Data! This production-ready starter kit empowers you to build and deploy AI apps with LangChainAI/LangGraph, featuring streaming chat, robust Keycloak authentication, Kong's multi-model gateway, and OpenShift.
Recently, I wanted to experiment with some algorithmic trading. Building the Interactive Brokers C++ API client library on macOS & Linux/aarch64 had a few more barriers than I anticipated. Wrote up a brief blog post with the steps. dlewis.io/ibkr-cpp-api/
Building the IBKR C++ API Client Library
Recently, I wanted to use the C++ API client library that Interactive Brokers provides and experiment with some algorithmitic trading and monitoring of my positions. I had hoped there would be some pr...
dlewis.io
February 11, 2025 at 11:16 PM
Recently, I wanted to experiment with some algorithmic trading. Building the Interactive Brokers C++ API client library on macOS & Linux/aarch64 had a few more barriers than I anticipated. Wrote up a brief blog post with the steps. dlewis.io/ibkr-cpp-api/
Reposted by Derek Lewis

EXCLUSIVE: Microsoft and OpenAI are investigating whether a group linked to China's DeepSeek obtained OpenAI's data.

Microsoft Probing If DeepSeek-Linked Group Improperly Obtained OpenAI Data
Microsoft Corp. and OpenAI are investigating whether data output from OpenAI’s technology was obtained in an unauthorized manner by a group linked to Chinese artificial intelligence startup DeepSeek, ...
www.bloomberg.com
January 29, 2025 at 3:17 AM
EXCLUSIVE: Microsoft and OpenAI are investigating whether a group linked to China's DeepSeek obtained OpenAI's data.
Would be nice to see the training code (not just inference code) from DeepSeek for the R1 models. One can hope...
January 27, 2025 at 2:01 PM
Would be nice to see the training code (not just inference code) from DeepSeek for the R1 models. One can hope...