

Edoardo Ponti
@edoardo-ponti.bsky.social
1.3K followers
78 following
27 posts
Assistant professor in Natural Language Processing at the University of Edinburgh and visiting professor at NVIDIA | A Kleene star shines on the hour of our meeting.
Posts
Media
Videos
Starter Packs
Reposted by Edoardo Ponti








Reposted by Edoardo Ponti

Edoardo Ponti
@edoardo-ponti.bsky.social
· Apr 25

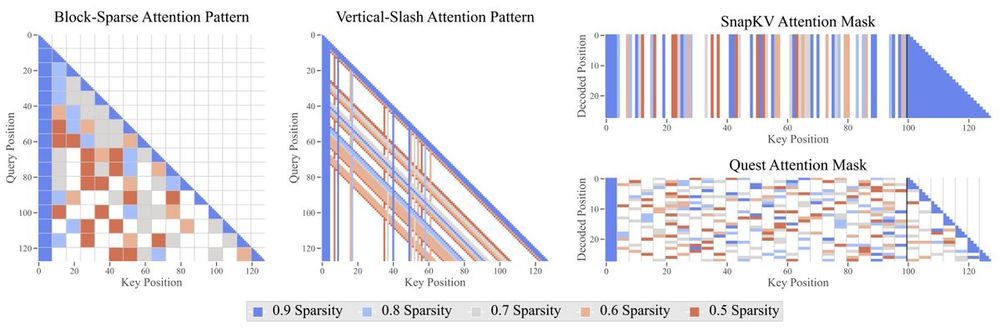
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its viability, its efficiency-accuracy trade-offs, and systematic scaling studies remain unexp...
arxiv.org




Reposted by Edoardo Ponti

Reposted by Edoardo Ponti

Edoardo Ponti
@edoardo-ponti.bsky.social
· Jan 31
Edoardo Ponti
@edoardo-ponti.bsky.social
· Jan 31

Dynamic Memory Compression | NVIDIA Technical Blog
Despite the success of large language models (LLMs) as general-purpose AI tools, their high demand for computational resources make their deployment challenging in many real-world scenarios.
developer.nvidia.com


Edoardo Ponti
@edoardo-ponti.bsky.social
· Dec 20
Edoardo Ponti
@edoardo-ponti.bsky.social
· Dec 20
Edoardo Ponti
@edoardo-ponti.bsky.social
· Dec 20


Edoardo Ponti
@edoardo-ponti.bsky.social
· Dec 12
Edoardo Ponti
@edoardo-ponti.bsky.social
· Dec 12