




Erfan Mirzaei
@erfunmirzaei.bsky.social
Researcher @PontilGroup.bsky.social| Ph.D. Student @ellis.eu, @Polytechnique, and @UniGenova.
Interested in (deep) learning theory and others.
Interested in (deep) learning theory and others.
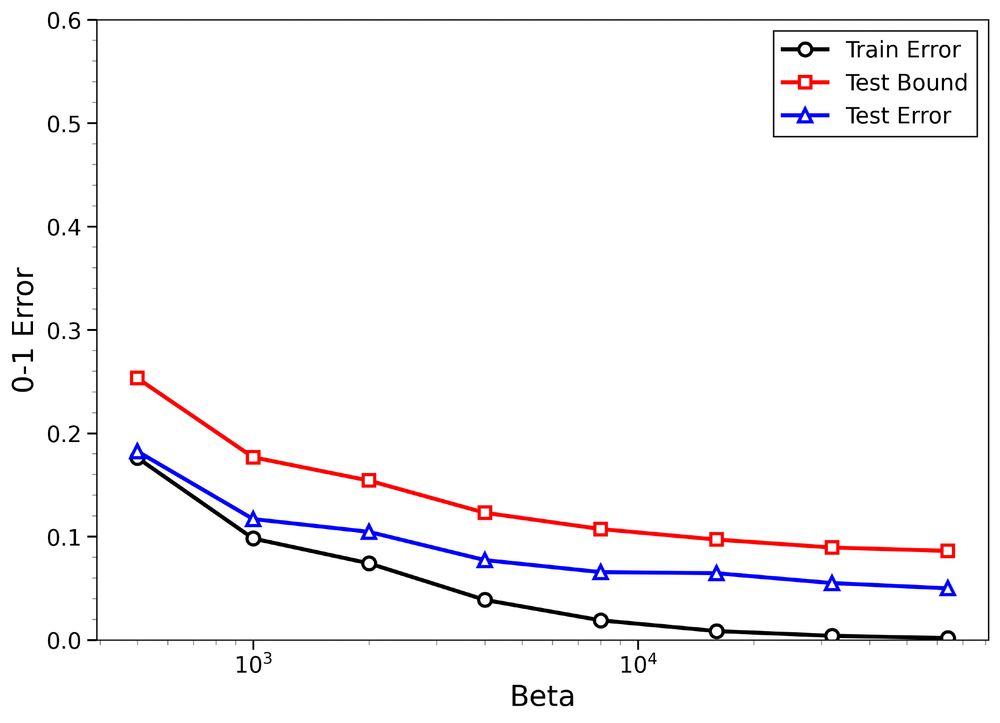
Empirical results on MNIST and CIFAR-10 show:
1) Non-trivial upper bounds on test error for both true and random labels
2) Meaningful distinction between structure-rich and structure-poor datasets
The figures: Binary classification with FCNNs using SGLD using 8k MNIST images
1) Non-trivial upper bounds on test error for both true and random labels
2) Meaningful distinction between structure-rich and structure-poor datasets
The figures: Binary classification with FCNNs using SGLD using 8k MNIST images

November 14, 2025 at 2:11 PM
Empirical results on MNIST and CIFAR-10 show:
1) Non-trivial upper bounds on test error for both true and random labels
2) Meaningful distinction between structure-rich and structure-poor datasets
The figures: Binary classification with FCNNs using SGLD using 8k MNIST images
1) Non-trivial upper bounds on test error for both true and random labels
2) Meaningful distinction between structure-rich and structure-poor datasets
The figures: Binary classification with FCNNs using SGLD using 8k MNIST images
To probe this question, we turn to randomized predictors rather than deterministic ones.
Here, predictors are sampled from a prescribed probability distribution, allowing us to apply PAC-Bayesian theory to study their generalization properties.
Here, predictors are sampled from a prescribed probability distribution, allowing us to apply PAC-Bayesian theory to study their generalization properties.

November 14, 2025 at 2:11 PM
To probe this question, we turn to randomized predictors rather than deterministic ones.
Here, predictors are sampled from a prescribed probability distribution, allowing us to apply PAC-Bayesian theory to study their generalization properties.
Here, predictors are sampled from a prescribed probability distribution, allowing us to apply PAC-Bayesian theory to study their generalization properties.
In the figure below from the famous paper, the same model achieves nearly zero training error on both random and true labels. Therefore, the key to generalization must lie within the structure of the data itself.
arxiv.org/abs/1611.03530
arxiv.org/abs/1611.03530

November 14, 2025 at 2:11 PM
In the figure below from the famous paper, the same model achieves nearly zero training error on both random and true labels. Therefore, the key to generalization must lie within the structure of the data itself.
arxiv.org/abs/1611.03530
arxiv.org/abs/1611.03530
🚨 Poster at #AISTATS2025 tomorrow!
📍Poster Session 1 #125
We present a new empirical Bernstein inequality for Hilbert space-valued random processes—relevant for dependent, even non-stationary data.
w/ Andreas Maurer, @vladimir-slk.bsky.social & M. Pontil
📄 Paper: openreview.net/forum?id=a0E...
📍Poster Session 1 #125
We present a new empirical Bernstein inequality for Hilbert space-valued random processes—relevant for dependent, even non-stationary data.
w/ Andreas Maurer, @vladimir-slk.bsky.social & M. Pontil
📄 Paper: openreview.net/forum?id=a0E...

May 2, 2025 at 6:35 PM
🚨 Poster at #AISTATS2025 tomorrow!
📍Poster Session 1 #125
We present a new empirical Bernstein inequality for Hilbert space-valued random processes—relevant for dependent, even non-stationary data.
w/ Andreas Maurer, @vladimir-slk.bsky.social & M. Pontil
📄 Paper: openreview.net/forum?id=a0E...
📍Poster Session 1 #125
We present a new empirical Bernstein inequality for Hilbert space-valued random processes—relevant for dependent, even non-stationary data.
w/ Andreas Maurer, @vladimir-slk.bsky.social & M. Pontil
📄 Paper: openreview.net/forum?id=a0E...