




Thaddée Tyl
@espadrine.bsky.social
Self-replicating organisms. shields.io, Captain Train, Qonto. They.
It might disappoint, but it should not.
We got too used to no longer seeing the GPT base model.
Let’s compare to the DeepSeek base model.
The jump from base to reasoning is tremendous!
Large 3 starts off slightly higher than DeepSeek base. I’m eager to see Magistral Large!
We got too used to no longer seeing the GPT base model.
Let’s compare to the DeepSeek base model.
The jump from base to reasoning is tremendous!
Large 3 starts off slightly higher than DeepSeek base. I’m eager to see Magistral Large!

December 3, 2025 at 10:40 AM
It might disappoint, but it should not.
We got too used to no longer seeing the GPT base model.
Let’s compare to the DeepSeek base model.
The jump from base to reasoning is tremendous!
Large 3 starts off slightly higher than DeepSeek base. I’m eager to see Magistral Large!
We got too used to no longer seeing the GPT base model.
Let’s compare to the DeepSeek base model.
The jump from base to reasoning is tremendous!
Large 3 starts off slightly higher than DeepSeek base. I’m eager to see Magistral Large!
I see the story of Mistral Large 3 as one of a major technical shift. To reduce inference costs further, they trained a large MoE from scratch, after years of building on existing weights.
Large 3 improves reasoning compared to Large 2, but is overtaken by… reasoning models.
Large 3 improves reasoning compared to Large 2, but is overtaken by… reasoning models.

December 3, 2025 at 10:40 AM
I see the story of Mistral Large 3 as one of a major technical shift. To reduce inference costs further, they trained a large MoE from scratch, after years of building on existing weights.
Large 3 improves reasoning compared to Large 2, but is overtaken by… reasoning models.
Large 3 improves reasoning compared to Large 2, but is overtaken by… reasoning models.
It, along with its Ministral sisters, is also the best model of its size class on math, coding and agentic tool use!

December 3, 2025 at 10:40 AM
It, along with its Ministral sisters, is also the best model of its size class on math, coding and agentic tool use!
The path of the Mistral 7B is nice to see!
The OG one topped open models of that size. For the first time, a local model felt usable on consumer hardware.
Not only is the latest Ministral 8B on the Pareto frontier for knowledge vs. cost (and for search, math, agentic uses)…
The OG one topped open models of that size. For the first time, a local model felt usable on consumer hardware.
Not only is the latest Ministral 8B on the Pareto frontier for knowledge vs. cost (and for search, math, agentic uses)…

December 3, 2025 at 10:40 AM
The path of the Mistral 7B is nice to see!
The OG one topped open models of that size. For the first time, a local model felt usable on consumer hardware.
Not only is the latest Ministral 8B on the Pareto frontier for knowledge vs. cost (and for search, math, agentic uses)…
The OG one topped open models of that size. For the first time, a local model felt usable on consumer hardware.
Not only is the latest Ministral 8B on the Pareto frontier for knowledge vs. cost (and for search, math, agentic uses)…
Big jump in math as well! Grok 4.1 Fast is quite strong too on this front, but it now has a powerful challenger on this price range.

December 1, 2025 at 6:28 PM
Big jump in math as well! Grok 4.1 Fast is quite strong too on this front, but it now has a powerful challenger on this price range.
DeepSeek released V3.2 (and V3.2 Speciale, a math-oriented model).
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.

December 1, 2025 at 6:28 PM
DeepSeek released V3.2 (and V3.2 Speciale, a math-oriented model).
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.
Expectedly, the same can be said in classic, RAG-and-search customer support chatbots, a use-case for our agentic leaderboard.

November 18, 2025 at 5:37 PM
Expectedly, the same can be said in classic, RAG-and-search customer support chatbots, a use-case for our agentic leaderboard.
In agentic coding, though, Claude still pulls ahead it seems, but by a short margin now.

November 18, 2025 at 5:37 PM
In agentic coding, though, Claude still pulls ahead it seems, but by a short margin now.
The code it writes is quite good, getting 76.2 on SWE-bench Verified, compared to GPT-5 Codex's 74.5 (a model which is dedicated to code).

November 18, 2025 at 5:37 PM
The code it writes is quite good, getting 76.2 on SWE-bench Verified, compared to GPT-5 Codex's 74.5 (a model which is dedicated to code).
It is pretty good at math, but honestly on-par with GPT-5. It has an AIME2025 of 95 for instance, compared to GPT-5's 94.

November 18, 2025 at 5:37 PM
It is pretty good at math, but honestly on-par with GPT-5. It has an AIME2025 of 95 for instance, compared to GPT-5's 94.
Where it shines most is in reasoning.
It jumps ahead of the pack, which had caught up Gemini 2.5.
It jumps ahead of the pack, which had caught up Gemini 2.5.

November 18, 2025 at 5:37 PM
Where it shines most is in reasoning.
It jumps ahead of the pack, which had caught up Gemini 2.5.
It jumps ahead of the pack, which had caught up Gemini 2.5.
So, how is Gemini 3 on this new leaderboard?
Its intrinsic knowledge is unmatched, surpassing 2.5 and GPT-5.1.
bsky.app/profile/espa...
Its intrinsic knowledge is unmatched, surpassing 2.5 and GPT-5.1.
bsky.app/profile/espa...

November 18, 2025 at 5:37 PM
So, how is Gemini 3 on this new leaderboard?
Its intrinsic knowledge is unmatched, surpassing 2.5 and GPT-5.1.
bsky.app/profile/espa...
Its intrinsic knowledge is unmatched, surpassing 2.5 and GPT-5.1.
bsky.app/profile/espa...
Unveiling a new LLM leaderboard: metabench.organisons.com
Why?
Company C1 releases model M1 and discloses benchmarks B1.
Company C2 releases M2, showing off benchmarks B2 which are distinct.
Comparing those models is hard since they don't share benchmarks!
Why?
Company C1 releases model M1 and discloses benchmarks B1.
Company C2 releases M2, showing off benchmarks B2 which are distinct.
Comparing those models is hard since they don't share benchmarks!

November 18, 2025 at 5:21 PM
Unveiling a new LLM leaderboard: metabench.organisons.com
Why?
Company C1 releases model M1 and discloses benchmarks B1.
Company C2 releases M2, showing off benchmarks B2 which are distinct.
Comparing those models is hard since they don't share benchmarks!
Why?
Company C1 releases model M1 and discloses benchmarks B1.
Company C2 releases M2, showing off benchmarks B2 which are distinct.
Comparing those models is hard since they don't share benchmarks!
Isn’t there a better way to handle screens than asking a *language model* to guess the number of pixels to the left and top of a UI widget?
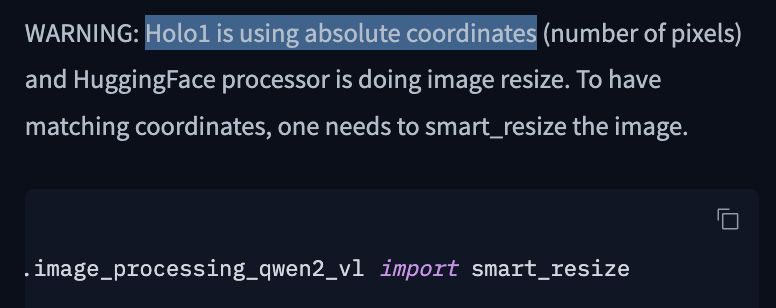
June 10, 2025 at 12:51 PM
Isn’t there a better way to handle screens than asking a *language model* to guess the number of pixels to the left and top of a UI widget?
This diffusion has shenanigans. The number of tokens between two unchanged sequences can increase or decrease.
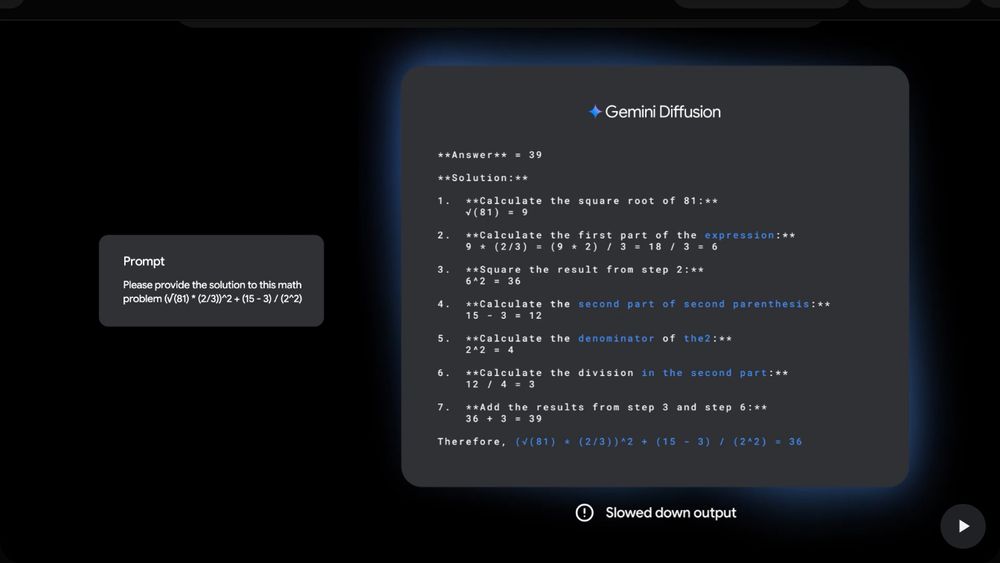
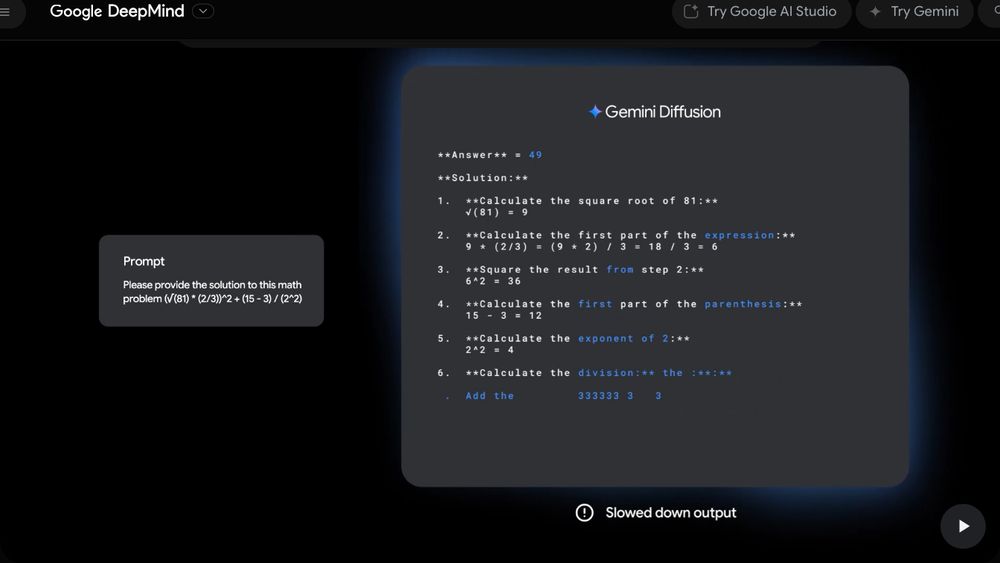
May 21, 2025 at 12:51 PM
This diffusion has shenanigans. The number of tokens between two unchanged sequences can increase or decrease.
We can get GNSS spacial positioning all the way to the moon, given the right receiver!
Greatly simplifies space travel.
I still believe we should set up a separate GNSS on every planet.
ntrs.nasa.gov/api/citation...
Greatly simplifies space travel.
I still believe we should set up a separate GNSS on every planet.
ntrs.nasa.gov/api/citation...
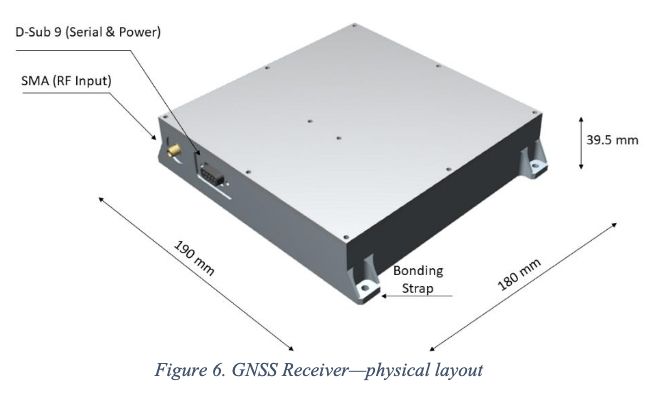
March 5, 2025 at 2:30 PM
We can get GNSS spacial positioning all the way to the moon, given the right receiver!
Greatly simplifies space travel.
I still believe we should set up a separate GNSS on every planet.
ntrs.nasa.gov/api/citation...
Greatly simplifies space travel.
I still believe we should set up a separate GNSS on every planet.
ntrs.nasa.gov/api/citation...
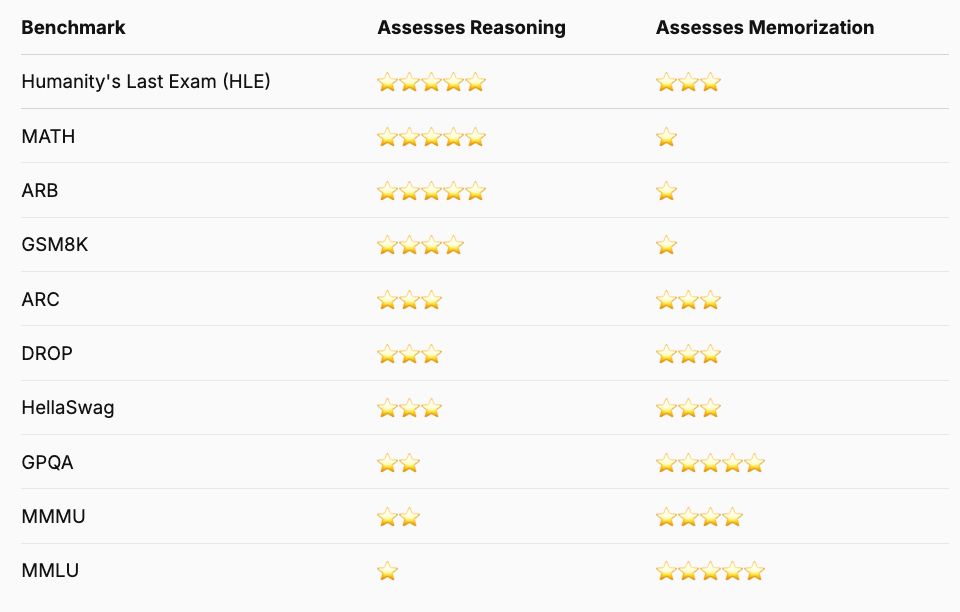
LLMs get better at tool use and search.
Model memorization is thus less useful than reasoning.
Yet a lot of benchmarks still focus on the former.
Model memorization is thus less useful than reasoning.
Yet a lot of benchmarks still focus on the former.
February 26, 2025 at 9:28 AM
LLMs get better at tool use and search.
Model memorization is thus less useful than reasoning.
Yet a lot of benchmarks still focus on the former.
Model memorization is thus less useful than reasoning.
Yet a lot of benchmarks still focus on the former.
Surprisingly, bigger Llama 3 models are worse at learning from relevant context, and giving a good answer, than smaller ones.
Unsurprisingly, base models evaluate the probability of a good answer better than instruct models, which will give a low probability to speech that doesn't match their style
Unsurprisingly, base models evaluate the probability of a good answer better than instruct models, which will give a low probability to speech that doesn't match their style

February 17, 2025 at 10:11 PM
Surprisingly, bigger Llama 3 models are worse at learning from relevant context, and giving a good answer, than smaller ones.
Unsurprisingly, base models evaluate the probability of a good answer better than instruct models, which will give a low probability to speech that doesn't match their style
Unsurprisingly, base models evaluate the probability of a good answer better than instruct models, which will give a low probability to speech that doesn't match their style
Do they have a reason to fear they won’t get paid?

February 7, 2025 at 6:03 PM
Do they have a reason to fear they won’t get paid?
Bittersweet to see the latest Codestral so close to the open-weights version, yet to see both are so close to Claude.

February 6, 2025 at 10:28 AM
Bittersweet to see the latest Codestral so close to the open-weights version, yet to see both are so close to Claude.
The issue with this kind of login form: when I come back, I have no idea which one I picked, and I won’t try them all until I find something I made before.

October 25, 2024 at 8:10 AM
The issue with this kind of login form: when I come back, I have no idea which one I picked, and I won’t try them all until I find something I made before.
But I wonder if there is a better way to write this CSS.
It is brittle because it depends on #browser being a sibling after #navigator-toolbox.
Do you have suggestions?
It is brittle because it depends on #browser being a sibling after #navigator-toolbox.
Do you have suggestions?

August 21, 2024 at 2:42 PM
But I wonder if there is a better way to write this CSS.
It is brittle because it depends on #browser being a sibling after #navigator-toolbox.
Do you have suggestions?
It is brittle because it depends on #browser being a sibling after #navigator-toolbox.
Do you have suggestions?
I want to make Firefox’ UI very minimal, only summoned through Ctrl+L.
Here is my solution so far.
(Requires adding the CSS file in a chrome/ folder in the root dir in about:profiles, then about:config > toolkit.legacyUserProfileCustomizations.stylesheets > true.)
Here is my solution so far.
(Requires adding the CSS file in a chrome/ folder in the root dir in about:profiles, then about:config > toolkit.legacyUserProfileCustomizations.stylesheets > true.)

August 21, 2024 at 2:41 PM
I want to make Firefox’ UI very minimal, only summoned through Ctrl+L.
Here is my solution so far.
(Requires adding the CSS file in a chrome/ folder in the root dir in about:profiles, then about:config > toolkit.legacyUserProfileCustomizations.stylesheets > true.)
Here is my solution so far.
(Requires adding the CSS file in a chrome/ folder in the root dir in about:profiles, then about:config > toolkit.legacyUserProfileCustomizations.stylesheets > true.)
“Large” language models is a moving target.
The first GPT had a hundred million parameters, and called itself large already.
GPT-4 has almost two trillion.
The first GPT had a hundred million parameters, and called itself large already.
GPT-4 has almost two trillion.

March 23, 2024 at 10:30 AM
“Large” language models is a moving target.
The first GPT had a hundred million parameters, and called itself large already.
GPT-4 has almost two trillion.
The first GPT had a hundred million parameters, and called itself large already.
GPT-4 has almost two trillion.
It is a bit odd that its performance on benchmarks in languages it targets have decreased compared to the raw Mistral model.

March 7, 2024 at 10:10 PM
It is a bit odd that its performance on benchmarks in languages it targets have decreased compared to the raw Mistral model.