





Various new posts from the last couple months:




November 8, 2025 at 11:57 AM
Various new posts from the last couple months:

GPT-5 numbers:
* HCAST/RE-Bench 50%: +25% rel, to 2h17m, SOTA
* HCAST/RE-Bench 80%: +25% rel, to 25mins, SOTA
* (Tier 1-3) FrontierMath: +5% abs, SOTA
* SWE-Bench Verified: same as Claude 4.1
* <1% improvement on other coding benchmarks
* Aider: +3% abs, SOTA
* Cost/perf: seems much worse
* HCAST/RE-Bench 50%: +25% rel, to 2h17m, SOTA
* HCAST/RE-Bench 80%: +25% rel, to 25mins, SOTA
* (Tier 1-3) FrontierMath: +5% abs, SOTA
* SWE-Bench Verified: same as Claude 4.1
* <1% improvement on other coding benchmarks
* Aider: +3% abs, SOTA
* Cost/perf: seems much worse

August 8, 2025 at 2:06 PM
GPT-5 numbers:
* HCAST/RE-Bench 50%: +25% rel, to 2h17m, SOTA
* HCAST/RE-Bench 80%: +25% rel, to 25mins, SOTA
* (Tier 1-3) FrontierMath: +5% abs, SOTA
* SWE-Bench Verified: same as Claude 4.1
* <1% improvement on other coding benchmarks
* Aider: +3% abs, SOTA
* Cost/perf: seems much worse
* HCAST/RE-Bench 50%: +25% rel, to 2h17m, SOTA
* HCAST/RE-Bench 80%: +25% rel, to 25mins, SOTA
* (Tier 1-3) FrontierMath: +5% abs, SOTA
* SWE-Bench Verified: same as Claude 4.1
* <1% improvement on other coding benchmarks
* Aider: +3% abs, SOTA
* Cost/perf: seems much worse

New paper out, with one Arb author:
www.pnas.org/doi/10.1073/...
LLMs consistently prefer LLM text. This maybe implies future AIs discriminating against humans as a class.
www.pnas.org/doi/10.1073/...
LLMs consistently prefer LLM text. This maybe implies future AIs discriminating against humans as a class.

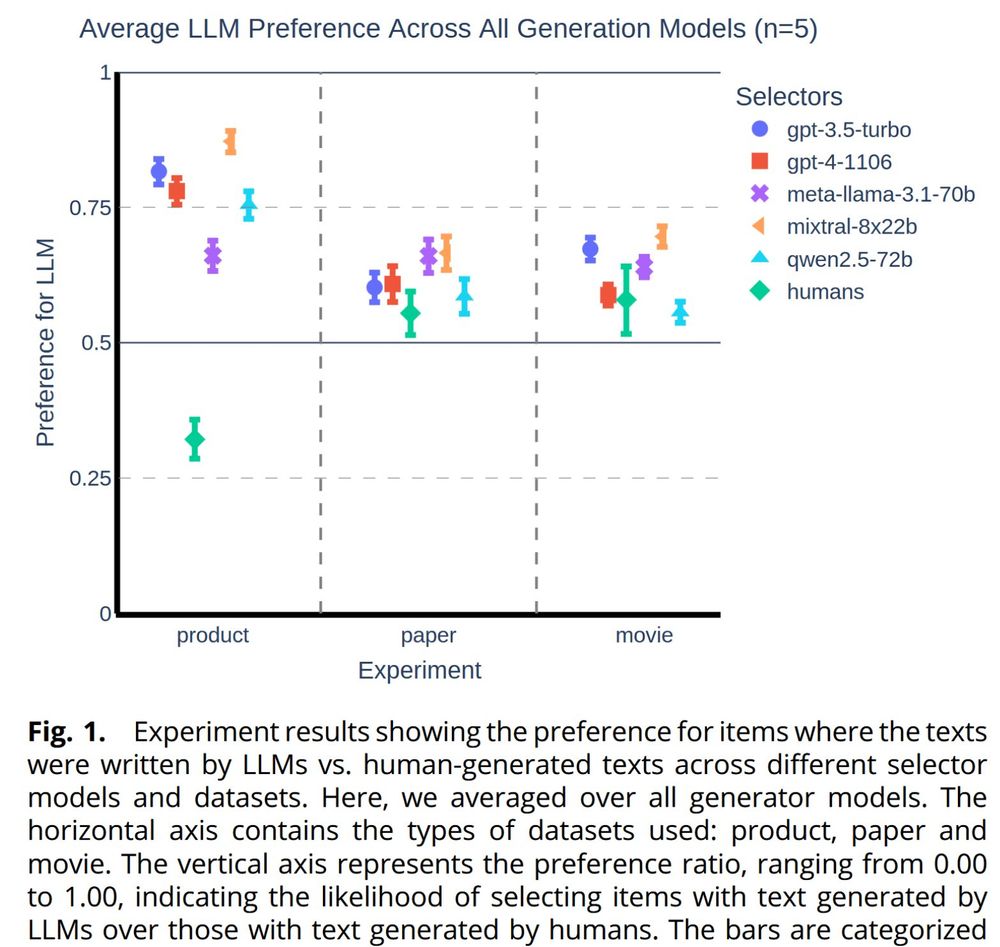
July 30, 2025 at 5:59 PM
New paper out, with one Arb author:
www.pnas.org/doi/10.1073/...
LLMs consistently prefer LLM text. This maybe implies future AIs discriminating against humans as a class.
www.pnas.org/doi/10.1073/...
LLMs consistently prefer LLM text. This maybe implies future AIs discriminating against humans as a class.
new tagline for the ol' firm

July 30, 2025 at 5:56 PM
new tagline for the ol' firm




We've reviewed as much of the year's AI safety work as possible. 11000 words but it's not really for reading.
www.lesswrong.com/posts/fAW6RX...
www.lesswrong.com/posts/fAW6RX...

December 29, 2024 at 12:26 PM
We've reviewed as much of the year's AI safety work as possible. 11000 words but it's not really for reading.
www.lesswrong.com/posts/fAW6RX...
www.lesswrong.com/posts/fAW6RX...

Claude has been giving me some some really odd code lately

December 9, 2024 at 9:55 AM
Claude has been giving me some some really odd code lately

things you see before the end

November 21, 2024 at 11:30 PM
things you see before the end


I rejected the one AI-generated paper I was given to review, but didn't notice it was generated.


November 20, 2024 at 5:02 AM
I rejected the one AI-generated paper I was given to review, but didn't notice it was generated.
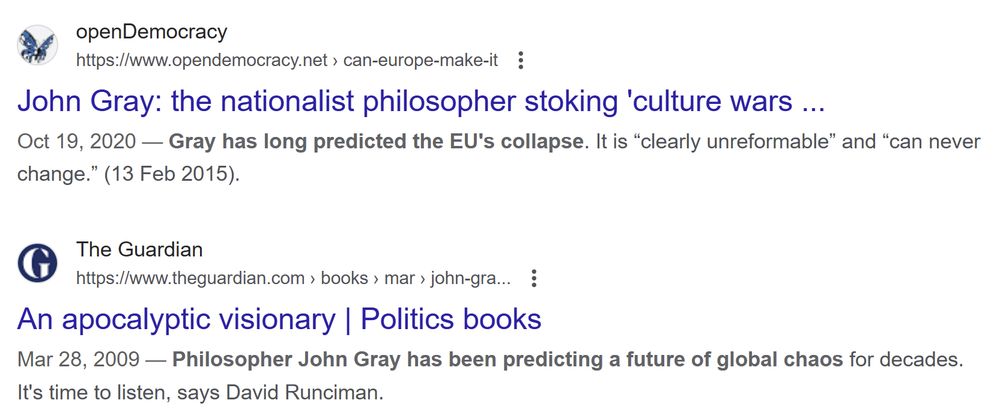
Deeply fishy. Where's the probabilities John? Where's the dates?


November 19, 2024 at 3:38 PM
Deeply fishy. Where's the probabilities John? Where's the dates?

friend tells me she can't make it through Witcher 3 because of the gore and corpses and hurting animals
my gf:
my gf:

November 17, 2024 at 2:07 PM
friend tells me she can't make it through Witcher 3 because of the gore and corpses and hurting animals
my gf:
my gf:

