



洪 民憙 (Hong Minhee)
@hongminhee.hackers.pub.ap.brid.gy
Hi, I'm who's behind Fedify, Hollo, BotKit, and this website, Hackers' Pub! My main account is at @hongminhee.
Fedify, Hollo, BotKit, 그리고 보고 계신 이 […]
🌉 bridged from https://hackers.pub/@hongminhee on the fediverse by https://fed.brid.gy/
Fedify, Hollo, BotKit, 그리고 보고 계신 이 […]
🌉 bridged from https://hackers.pub/@hongminhee on the fediverse by https://fed.brid.gy/
Reposted by 洪 民憙 (Hong Minhee)

`System.IO.readFile` 쓰지 마세요.
`System.IO.readFile` 쓰지 마세요.
`System.IO.readFile` 쓰지 마세요.
첫째, `System.IO.readFile` 은 `String` 을 반환합니다. 이건 심각한 문제입니다. `String` 을 쓰지 마세요. 외부 세계와 I/O 를 할 때에는 `ByteString` 을 써야 합니다. 유니코드 문자열을 다룰 때에는 `Text` 를 쓸 수 있습니다. `String` 은 시간적으로도 공간적으로 비효율적입니다. 이건 어쩔 수 없습니다 […]
`System.IO.readFile` 쓰지 마세요.
`System.IO.readFile` 쓰지 마세요.
첫째, `System.IO.readFile` 은 `String` 을 반환합니다. 이건 심각한 문제입니다. `String` 을 쓰지 마세요. 외부 세계와 I/O 를 할 때에는 `ByteString` 을 써야 합니다. 유니코드 문자열을 다룰 때에는 `Text` 를 쓸 수 있습니다. `String` 은 시간적으로도 공간적으로 비효율적입니다. 이건 어쩔 수 없습니다 […]
November 16, 2025 at 2:48 PM
`System.IO.readFile` 쓰지 마세요.
`System.IO.readFile` 쓰지 마세요.
`System.IO.readFile` 쓰지 마세요.
첫째, `System.IO.readFile` 은 `String` 을 반환합니다. 이건 심각한 문제입니다. `String` 을 쓰지 마세요. 외부 세계와 I/O 를 할 때에는 `ByteString` 을 써야 합니다. 유니코드 문자열을 다룰 때에는 `Text` 를 쓸 수 있습니다. `String` 은 시간적으로도 공간적으로 비효율적입니다. 이건 어쩔 수 없습니다 […]
`System.IO.readFile` 쓰지 마세요.
`System.IO.readFile` 쓰지 마세요.
첫째, `System.IO.readFile` 은 `String` 을 반환합니다. 이건 심각한 문제입니다. `String` 을 쓰지 마세요. 외부 세계와 I/O 를 할 때에는 `ByteString` 을 써야 합니다. 유니코드 문자열을 다룰 때에는 `Text` 를 쓸 수 있습니다. `String` 은 시간적으로도 공간적으로 비효율적입니다. 이건 어쩔 수 없습니다 […]
Reposted by 洪 民憙 (Hong Minhee)

Interesting design question for #optique (a type-safe #cli parser for #typescript): how should it handle unrecognized options in wrapper/proxy tools? Proposed three modes but wondering if the complexity is worth it. Thoughts?
https://github.com/dahlia/optique/issues/35
https://github.com/dahlia/optique/issues/35

feature or docs request: "extra options" parser · Issue #35 · dahlia/optique
First of all, thank you for this excellent project. I'm still getting familiar with it, but it's been a fun time so far. I'm writing a wrapper around another tool. The wrapper has some extra option...
github.com
November 14, 2025 at 5:11 PM
Interesting design question for #optique (a type-safe #cli parser for #typescript): how should it handle unrecognized options in wrapper/proxy tools? Proposed three modes but wondering if the complexity is worth it. Thoughts?
https://github.com/dahlia/optique/issues/35
https://github.com/dahlia/optique/issues/35
Reposted by 洪 民憙 (Hong Minhee)

RSS 피드가 있다면,
1. `@birb` 피드 주소를 알려준다
2. RSS 앵무새가 피드로 `_at_어쩌고.저쩌고_at_rss-parrot.net` 계정을 만들어 알려준다
3. 팔로우
:blob__sunglasses: :blob__sunglasses: :blob__sunglasses:
https://rss-parrot.net/
1. `@birb` 피드 주소를 알려준다
2. RSS 앵무새가 피드로 `_at_어쩌고.저쩌고_at_rss-parrot.net` 계정을 만들어 알려준다
3. 팔로우
:blob__sunglasses: :blob__sunglasses: :blob__sunglasses:
https://rss-parrot.net/
RSS Parrot
Home of RSS Parrot, a free Fediverse service that lets you turn Mastodon into an RSS or Atom feed reader.
rss-parrot.net
November 14, 2025 at 3:10 AM
RSS 피드가 있다면,
1. `@birb` 피드 주소를 알려준다
2. RSS 앵무새가 피드로 `_at_어쩌고.저쩌고_at_rss-parrot.net` 계정을 만들어 알려준다
3. 팔로우
:blob__sunglasses: :blob__sunglasses: :blob__sunglasses:
https://rss-parrot.net/
1. `@birb` 피드 주소를 알려준다
2. RSS 앵무새가 피드로 `_at_어쩌고.저쩌고_at_rss-parrot.net` 계정을 만들어 알려준다
3. 팔로우
:blob__sunglasses: :blob__sunglasses: :blob__sunglasses:
https://rss-parrot.net/
Reposted by 洪 民憙 (Hong Minhee)

Vim에서 Quickfix List라는 걸 처음 알게 되었다.
기존 코딩 흐름은
G 코딩 코딩 Vim을 닫는다. Vim을 닫는다. 코딩->Vim을 닫는다. cabal build cabal build Vim을 닫는다.->cabal build 에러 확인 에러 확인 cabal build->에러 확인 Vim을 연다. Vim을 연다. 에러 확인->Vim을 연다. 에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다. Vim을 연다.->에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다 […]
기존 코딩 흐름은
G 코딩 코딩 Vim을 닫는다. Vim을 닫는다. 코딩->Vim을 닫는다. cabal build cabal build Vim을 닫는다.->cabal build 에러 확인 에러 확인 cabal build->에러 확인 Vim을 연다. Vim을 연다. 에러 확인->Vim을 연다. 에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다. Vim을 연다.->에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다 […]
Original post on hackers.pub
hackers.pub
November 14, 2025 at 4:48 AM
Vim에서 Quickfix List라는 걸 처음 알게 되었다.
기존 코딩 흐름은
G 코딩 코딩 Vim을 닫는다. Vim을 닫는다. 코딩->Vim을 닫는다. cabal build cabal build Vim을 닫는다.->cabal build 에러 확인 에러 확인 cabal build->에러 확인 Vim을 연다. Vim을 연다. 에러 확인->Vim을 연다. 에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다. Vim을 연다.->에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다 […]
기존 코딩 흐름은
G 코딩 코딩 Vim을 닫는다. Vim을 닫는다. 코딩->Vim을 닫는다. cabal build cabal build Vim을 닫는다.->cabal build 에러 확인 에러 확인 cabal build->에러 확인 Vim을 연다. Vim을 연다. 에러 확인->Vim을 연다. 에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다. Vim을 연다.->에러가 발생한 행(row)으로 간다. 에러가 발생한 행(row)으로 간다 […]
Reposted by 洪 民憙 (Hong Minhee)

out of context svelte

November 13, 2025 at 6:11 PM
out of context svelte
Reposted by 洪 民憙 (Hong Minhee)

vimrc2025 행사에서 뿌릴 스티커 도착함.

November 13, 2025 at 4:27 AM
vimrc2025 행사에서 뿌릴 스티커 도착함.
버그를 제보하는 걸 굳이 다 대응해야 하느냐는 식의 댓글들이 달려 있던데, 문제는 그냥 버그 제보가 아니라 보안 취약점 제보라는 게 아닐까… 보안 취약점은 일단 공개되면 하루빨리 대응해야 하기 때문에, 메인테이너들의 관리 부담이 되는 것.
RE: https://sns.lemondouble.com/notes/af0aeogtur
RE: https://sns.lemondouble.com/notes/af0aeogtur
sns.lemondouble.com
November 13, 2025 at 3:16 AM
버그를 제보하는 걸 굳이 다 대응해야 하느냐는 식의 댓글들이 달려 있던데, 문제는 그냥 버그 제보가 아니라 보안 취약점 제보라는 게 아닐까… 보안 취약점은 일단 공개되면 하루빨리 대응해야 하기 때문에, 메인테이너들의 관리 부담이 되는 것.
RE: https://sns.lemondouble.com/notes/af0aeogtur
RE: https://sns.lemondouble.com/notes/af0aeogtur
Reposted by 洪 民憙 (Hong Minhee)
하스켈에서 다음과 같은 에러를 만날 경우에
withFile: resource busy (file is locked)
`readFile` 대신 `readFile'`을 써보셔요!
* `readFile`은 lazy 버전이고
* `readFile'`은 strict 버전입니다!
`System.IO` 모듈 문서에 다음과 같은 설명이 있습니다.
> 경고: `readFile` 연산은 파일의 전체 내용을 모두 소비할 때까지 그 파일에 대해 부분적으로 닫힌(semi-closed) 핸들을 유지한다. 따라서 이전에 […]
withFile: resource busy (file is locked)
`readFile` 대신 `readFile'`을 써보셔요!
* `readFile`은 lazy 버전이고
* `readFile'`은 strict 버전입니다!
`System.IO` 모듈 문서에 다음과 같은 설명이 있습니다.
> 경고: `readFile` 연산은 파일의 전체 내용을 모두 소비할 때까지 그 파일에 대해 부분적으로 닫힌(semi-closed) 핸들을 유지한다. 따라서 이전에 […]
Original post on hackers.pub
hackers.pub
November 13, 2025 at 1:23 AM
하스켈에서 다음과 같은 에러를 만날 경우에
withFile: resource busy (file is locked)
`readFile` 대신 `readFile'`을 써보셔요!
* `readFile`은 lazy 버전이고
* `readFile'`은 strict 버전입니다!
`System.IO` 모듈 문서에 다음과 같은 설명이 있습니다.
> 경고: `readFile` 연산은 파일의 전체 내용을 모두 소비할 때까지 그 파일에 대해 부분적으로 닫힌(semi-closed) 핸들을 유지한다. 따라서 이전에 […]
withFile: resource busy (file is locked)
`readFile` 대신 `readFile'`을 써보셔요!
* `readFile`은 lazy 버전이고
* `readFile'`은 strict 버전입니다!
`System.IO` 모듈 문서에 다음과 같은 설명이 있습니다.
> 경고: `readFile` 연산은 파일의 전체 내용을 모두 소비할 때까지 그 파일에 대해 부분적으로 닫힌(semi-closed) 핸들을 유지한다. 따라서 이전에 […]
Reposted by 洪 民憙 (Hong Minhee)
Just released LogTape 1.2.0. You can now access nested properties directly in templates (e.g., `{user.profile.email}`), and the fingers crossed sink got context isolation for better HTTP request tracing.

LogTape 1.2.0: Nested property access and context isolation · dahlia logtape · Discussion #97
LogTape is a logging library for JavaScript and TypeScript that works across Deno, Node.js, Bun, and browsers. It's built around structured logging with zero dependencies and flexible configuration...
github.com
November 11, 2025 at 2:19 PM
Just released LogTape 1.2.0. You can now access nested properties directly in templates (e.g., `{user.profile.email}`), and the fingers crossed sink got context isolation for better HTTP request tracing.
Reposted by 洪 民憙 (Hong Minhee)
12月(월) 6日(일) 서울에서 開催(개최)되는 liftIO 2025에서 〈Optique: TypeScript에서 CLI 파서 컴비네이터를 만들어 보았다〉(假題(가제))라는 主題(주제)로 發表(발표)를 하게 되었습니다. 아직 liftIO 2025 티켓은 팔고 있으니, 函數型(함수형) 프로그래밍에 關心(관심) 있으신 분들의 많은 參與(참여) 바랍니다!

liftIO 2025 - 이벤터스
2021년부터 매년 말에 개최되고 있는 liftIO는 함수형 프로그래밍 언어를 사용하는 생생한 경험담과 인사이트를 제공하는 개발 컨퍼런스입니다.
event-us.kr
November 11, 2025 at 4:42 AM
12月(월) 6日(일) 서울에서 開催(개최)되는 liftIO 2025에서 〈Optique: TypeScript에서 CLI 파서 컴비네이터를 만들어 보았다〉(假題(가제))라는 主題(주제)로 發表(발표)를 하게 되었습니다. 아직 liftIO 2025 티켓은 팔고 있으니, 函數型(함수형) 프로그래밍에 關心(관심) 있으신 분들의 많은 參與(참여) 바랍니다!
Reposted by 洪 民憙 (Hong Minhee)
liftIO에서 `liftIO`를 설명하면 재밌을 것 같은데 그러려면 모나드 트랜스포머를 설명해야 하고 그러려면 모나드를 설명해야 하고...
November 11, 2025 at 3:50 AM
liftIO에서 `liftIO`를 설명하면 재밌을 것 같은데 그러려면 모나드 트랜스포머를 설명해야 하고 그러려면 모나드를 설명해야 하고...
Reposted by 洪 民憙 (Hong Minhee)
[Mon Nov 10 14:09:39 2025] Out of memory: Killed process 29426 (syncthing) total-vm:2418416kB, anon-rss:784kB, file-rss:3584kB, shmem-rss:0kB, UID:1000 pgtables:516kB oom_score_adj:200
1GB 짜리 SBC 에서 싱크싱을 systemd 유저 서비스로 띄워 두고 매일 몇 GB 정도 싱크를 하게 했더니 하루에 한 번씩 OOM 킬 당한다. 스와프 2GB 줘 봤지만 소용이 없다 […]
Original post on hackers.pub
hackers.pub
November 10, 2025 at 7:51 AM
[Mon Nov 10 14:09:39 2025] Out of memory: Killed process 29426 (syncthing) total-vm:2418416kB, anon-rss:784kB, file-rss:3584kB, shmem-rss:0kB, UID:1000 pgtables:516kB oom_score_adj:200
1GB 짜리 SBC 에서 싱크싱을 systemd 유저 서비스로 띄워 두고 매일 몇 GB 정도 싱크를 하게 했더니 하루에 한 번씩 OOM 킬 당한다. 스와프 2GB 줘 봤지만 소용이 없다 […]
Reposted by 洪 民憙 (Hong Minhee)
마크다운은 토씨랑 상성이 진짜 안맞아서 불편하다... `*이것을 찾으셨나요?*에`라고 쓰면 "*이것을 찾으셨나요?*에"가 되고 `<em>` 태그를 써야 제대로 적용이 된다
November 9, 2025 at 1:32 PM
마크다운은 토씨랑 상성이 진짜 안맞아서 불편하다... `*이것을 찾으셨나요?*에`라고 쓰면 "*이것을 찾으셨나요?*에"가 되고 `<em>` 태그를 써야 제대로 적용이 된다
Reposted by 洪 民憙 (Hong Minhee)
러스트 문서가 시전하는 _이것을 찾으셨나요?_ 에 큰 호감을 느끼고 있다

November 9, 2025 at 1:30 PM
러스트 문서가 시전하는 _이것을 찾으셨나요?_ 에 큰 호감을 느끼고 있다
Reposted by 洪 民憙 (Hong Minhee)
리눅스 랩탑(amdgpu, rocm)에서 ollama 써서 아주 잠깐 로컬 LLM 시도해 본 소감: 생각보다 잘 되는데, 한편으로 왜 OpenAI 의 적자가 저렇게 터무니없는 규모라는 것인지도 이해했다. 어디가 병목인지는 알겠는데 그래서 그에 대한 대응책은 GPU 를 증설하기 시작해서 그냥 많이 증설했습니다. 를 하고 있다는 것이군 진짜로… 이게 인류의 갈 길이라니… 사이버펑크보다 현실이 더 사이버펑크다
November 9, 2025 at 5:16 AM
리눅스 랩탑(amdgpu, rocm)에서 ollama 써서 아주 잠깐 로컬 LLM 시도해 본 소감: 생각보다 잘 되는데, 한편으로 왜 OpenAI 의 적자가 저렇게 터무니없는 규모라는 것인지도 이해했다. 어디가 병목인지는 알겠는데 그래서 그에 대한 대응책은 GPU 를 증설하기 시작해서 그냥 많이 증설했습니다. 를 하고 있다는 것이군 진짜로… 이게 인류의 갈 길이라니… 사이버펑크보다 현실이 더 사이버펑크다
Reposted by 洪 民憙 (Hong Minhee)
오늘 백준에서 2문제를 풀었는데 둘다 롱롱죽겠지를 당했다 (`long long`을 써야 되는데 `int`를 썼다는 뜻)
November 8, 2025 at 6:43 AM
오늘 백준에서 2문제를 풀었는데 둘다 롱롱죽겠지를 당했다 (`long long`을 써야 되는데 `int`를 썼다는 뜻)
Reposted by 洪 民憙 (Hong Minhee)
방금 10명 정도 가입하신듯...!!
November 8, 2025 at 2:20 AM
방금 10명 정도 가입하신듯...!!
Reposted by 洪 民憙 (Hong Minhee)
Sharing the slides from my talk, _Embracing yak shaving_ , which I presented today at the @fossforall Conference 2025! Thanks to everyone who came to listen!
November 8, 2025 at 2:22 AM
Sharing the slides from my talk, _Embracing yak shaving_ , which I presented today at the @fossforall Conference 2025! Thanks to everyone who came to listen!
Reposted by 洪 民憙 (Hong Minhee)
오늘 @fossforall 컨퍼런스 2025에서 發表(발표)한 〈야크 셰이빙: 새로운 오픈 소스의 원동력〉의 슬라이드를 共有(공유)합니다! 들어주신 분들 모두 感謝(감사)합니다!

야크 셰이빙: 새로운 오픈 소스의 원동력
야크 셰이빙: 새로운 오픈 소스의 원동력 불편함에서 시작된 2년간의 여정 洪民憙 (홍민희) hongminhee.org 커뮤니티와 기여 문화 Scan for English slides! →
docs.google.com
November 8, 2025 at 2:18 AM
오늘 @fossforall 컨퍼런스 2025에서 發表(발표)한 〈야크 셰이빙: 새로운 오픈 소스의 원동력〉의 슬라이드를 共有(공유)합니다! 들어주신 분들 모두 感謝(감사)합니다!
Reposted by 洪 民憙 (Hong Minhee)

님들 고스트(아마 Pro?)로 블로깅하면 연합우주 연동되는 거 알고 있음? 고스트에서 포스트 퍼블리시할 때마다 연합우주에도 포스트 만들어주고 해당 연합우주 계정으로 다른 계정 포스팅에 댓글도 달아줄 수 있음… 어떻게 돌아가는지 참고 → https://hackers.pub/@[email protected]
정진명의 굳이 써서 남기는 생각
hackers.pub
November 7, 2025 at 12:34 PM
님들 고스트(아마 Pro?)로 블로깅하면 연합우주 연동되는 거 알고 있음? 고스트에서 포스트 퍼블리시할 때마다 연합우주에도 포스트 만들어주고 해당 연합우주 계정으로 다른 계정 포스팅에 댓글도 달아줄 수 있음… 어떻게 돌아가는지 참고 → https://hackers.pub/@[email protected]
Reposted by 洪 民憙 (Hong Minhee)

Yarn 컨트리뷰터가 되었다 ㅎㅎ https://github.com/yarnpkg/berry/releases/tag/%40yarnpkg%2Fcli%2F4.11.0
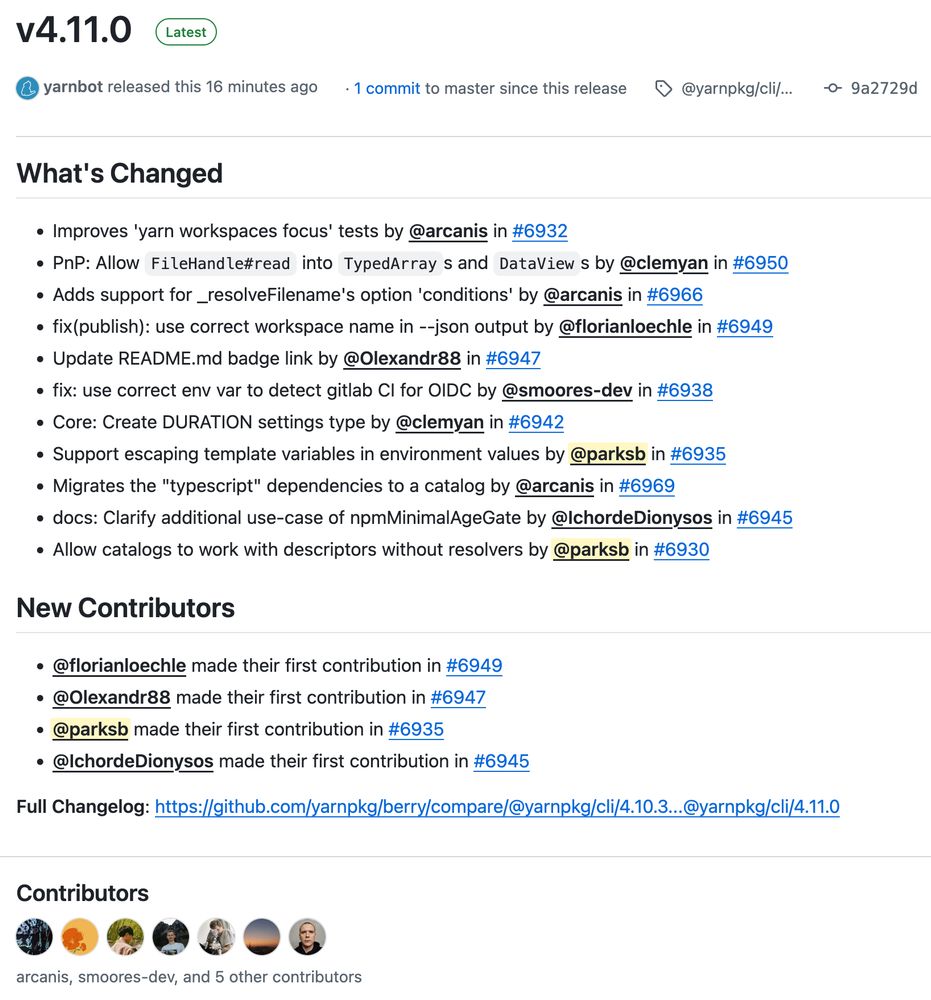
November 7, 2025 at 2:12 PM
Yarn 컨트리뷰터가 되었다 ㅎㅎ https://github.com/yarnpkg/berry/releases/tag/%40yarnpkg%2Fcli%2F4.11.0
Reposted by 洪 民憙 (Hong Minhee)
Just opened an issue for a major new task for #fedify: building an #interoperability smoke test suite.
To ensure Fedify-built servers federate correctly with the wider #fediverse, we're planning to run automated E2E tests in #ci against live instances of Mastodon, Misskey, and more. This is […]
To ensure Fedify-built servers federate correctly with the wider #fediverse, we're planning to run automated E2E tests in #ci against live instances of Mastodon, Misskey, and more. This is […]
Original post on hollo.social
hollo.social
November 7, 2025 at 11:20 AM
Just opened an issue for a major new task for #fedify: building an #interoperability smoke test suite.
To ensure Fedify-built servers federate correctly with the wider #fediverse, we're planning to run automated E2E tests in #ci against live instances of Mastodon, Misskey, and more. This is […]
To ensure Fedify-built servers federate correctly with the wider #fediverse, we're planning to run automated E2E tests in #ci against live instances of Mastodon, Misskey, and more. This is […]
Reposted by 洪 民憙 (Hong Minhee)

While cleaning a storage room, our staff found this tape containing #unix v4 from Bell Labs, circa 1973
Apparently no other complete copies are known to exist: https://gunkies.org/wiki/UNIX_Fourth_Edition
We have arranged to deliver it to the Computer History Museum
#retrocomputing
Apparently no other complete copies are known to exist: https://gunkies.org/wiki/UNIX_Fourth_Edition
We have arranged to deliver it to the Computer History Museum
#retrocomputing

November 6, 2025 at 8:50 PM
While cleaning a storage room, our staff found this tape containing #unix v4 from Bell Labs, circa 1973
Apparently no other complete copies are known to exist: https://gunkies.org/wiki/UNIX_Fourth_Edition
We have arranged to deliver it to the Computer History Museum
#retrocomputing
Apparently no other complete copies are known to exist: https://gunkies.org/wiki/UNIX_Fourth_Edition
We have arranged to deliver it to the Computer History Museum
#retrocomputing
좀 다른 얘기인데 JavaScript에도 어서 Python의 `sorted()` 함수처럼 cmp 함수 대신 `key` 함수를 받고 `reverse` 옵션을 제공해야 한다고 봅니다.
RE: https://hackers.pub/@disjukr/2025/abab-asc-123-abc
RE: https://hackers.pub/@disjukr/2025/abab-asc-123-abc
hackers.pub
November 7, 2025 at 6:13 AM
좀 다른 얘기인데 JavaScript에도 어서 Python의 `sorted()` 함수처럼 cmp 함수 대신 `key` 함수를 받고 `reverse` 옵션을 제공해야 한다고 봅니다.
RE: https://hackers.pub/@disjukr/2025/abab-asc-123-abc
RE: https://hackers.pub/@disjukr/2025/abab-asc-123-abc