
Jackson Petty
@jacksonpetty.org
200 followers
240 following
340 posts
the passionate shepherd, to his love • ἀρετῇ • מנא הני מילי
Posts
Media
Videos
Starter Packs
Pinned





Jackson Petty
@jacksonpetty.org
· Jul 4
Reposted by Jackson Petty

Tal Linzen
@tallinzen.bsky.social
· Jun 21
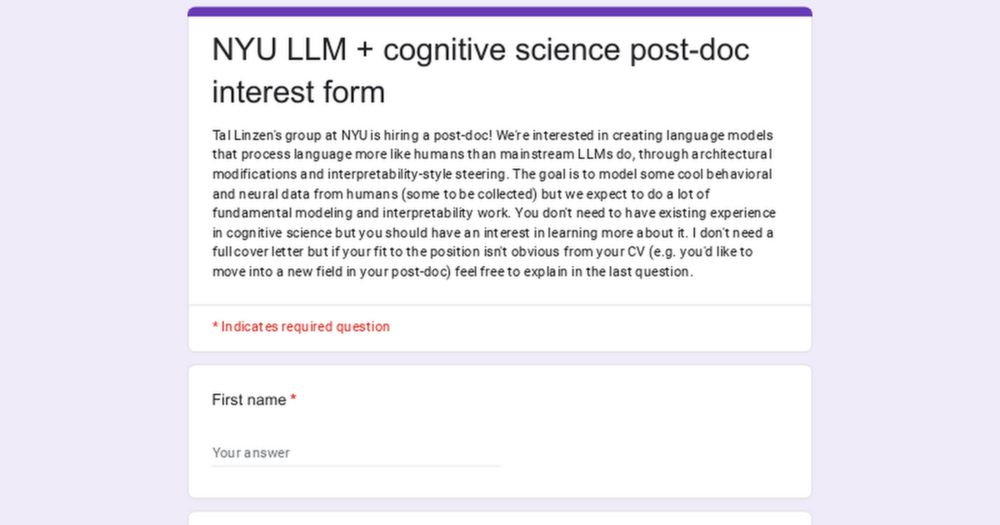
NYU LLM + cognitive science post-doc interest form
Tal Linzen's group at NYU is hiring a post-doc! We're interested in creating language models that process language more like humans than mainstream LLMs do, through architectural modifications and int...
docs.google.com
Jackson Petty
@jacksonpetty.org
· Jun 22
Jackson Petty
@jacksonpetty.org
· Jun 9
Jackson Petty
@jacksonpetty.org
· Jun 9
Jackson Petty
@jacksonpetty.org
· Jun 9
Jackson Petty
@jacksonpetty.org
· Jun 9
Jackson Petty
@jacksonpetty.org
· Jun 9






Jackson Petty
@jacksonpetty.org
· Jun 9
Jackson Petty
@jacksonpetty.org
· Jun 9
Jackson Petty
@jacksonpetty.org
· Jun 9

Jackson Petty
@jacksonpetty.org
· Jun 9

Jackson Petty
@jacksonpetty.org
· May 23
Jackson Petty
@jacksonpetty.org
· May 11