




Julia Kruk
@juliakruk.bsky.social
NLP, CSS & Multimodality💫 Graduate Researcher @Stanford NLP | Research Affiliate @Georgia Tech | Data Scientist @Bombora
📍New York, NY
👩💻 https://j-kruk.github.io/
📍New York, NY
👩💻 https://j-kruk.github.io/
Come chat with us at NeurIPS 2024 🎉
📍 West Ballroom A-D #5211
⏰ Wednesday Dec 11th, 11 a.m. — 2 p.m. PST.
📍 West Ballroom A-D #5211
⏰ Wednesday Dec 11th, 11 a.m. — 2 p.m. PST.
December 5, 2024 at 1:02 AM
Come chat with us at NeurIPS 2024 🎉
📍 West Ballroom A-D #5211
⏰ Wednesday Dec 11th, 11 a.m. — 2 p.m. PST.
📍 West Ballroom A-D #5211
⏰ Wednesday Dec 11th, 11 a.m. — 2 p.m. PST.
🥳 This work was an amazing collaboration between @gtresearchnews.bsky.social and @stanfordnlp.bsky.social.
🙏 Huge thank you to @judyh.bsky.social,
@polochau.bsky.social, and @diyiyang.bsky.social for their guidance!
🙏 Huge thank you to @judyh.bsky.social,
@polochau.bsky.social, and @diyiyang.bsky.social for their guidance!
December 5, 2024 at 1:02 AM
🥳 This work was an amazing collaboration between @gtresearchnews.bsky.social and @stanfordnlp.bsky.social.
🙏 Huge thank you to @judyh.bsky.social,
@polochau.bsky.social, and @diyiyang.bsky.social for their guidance!
🙏 Huge thank you to @judyh.bsky.social,
@polochau.bsky.social, and @diyiyang.bsky.social for their guidance!
In addition to the Semi-Truths dataset, we release our pipeline to enable the community to create custom evaluation sets for their unique use cases! Please interact with our work on:
🤗HF: huggingface.co/semi-truths
👾Github: github.com/J-Kruk/SemiT...
🤗HF: huggingface.co/semi-truths
👾Github: github.com/J-Kruk/SemiT...

semi-truths (Semi Truths)
User profile of Semi Truths on Hugging Face
huggingface.co
December 5, 2024 at 1:02 AM
In addition to the Semi-Truths dataset, we release our pipeline to enable the community to create custom evaluation sets for their unique use cases! Please interact with our work on:
🤗HF: huggingface.co/semi-truths
👾Github: github.com/J-Kruk/SemiT...
🤗HF: huggingface.co/semi-truths
👾Github: github.com/J-Kruk/SemiT...
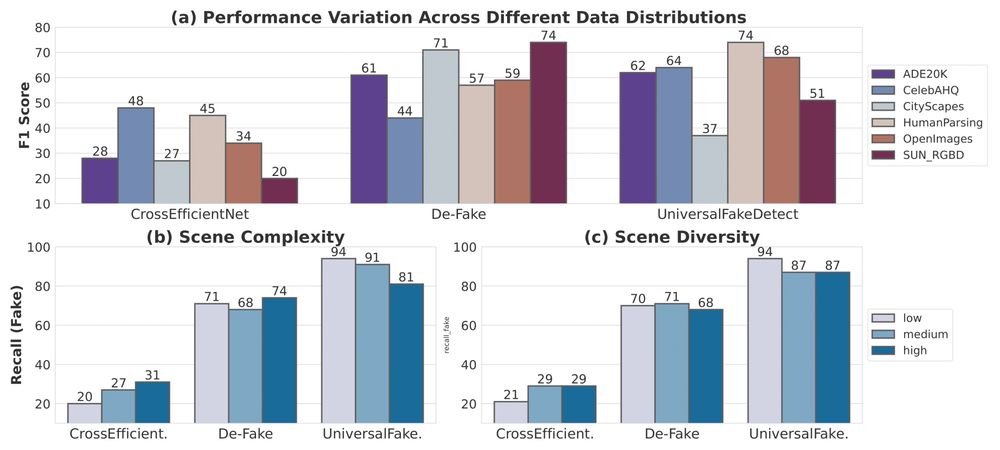
Every image is enriched with attributes quantifying the magnitude of change achieved. Evaluating performance on these attributes provides insights into detector biases.
💡 UniversalFakeDetector suffers >35 point performance drop on different scenes, and >5 points on magnitude of change.
💡 UniversalFakeDetector suffers >35 point performance drop on different scenes, and >5 points on magnitude of change.
December 5, 2024 at 1:02 AM
Every image is enriched with attributes quantifying the magnitude of change achieved. Evaluating performance on these attributes provides insights into detector biases.
💡 UniversalFakeDetector suffers >35 point performance drop on different scenes, and >5 points on magnitude of change.
💡 UniversalFakeDetector suffers >35 point performance drop on different scenes, and >5 points on magnitude of change.
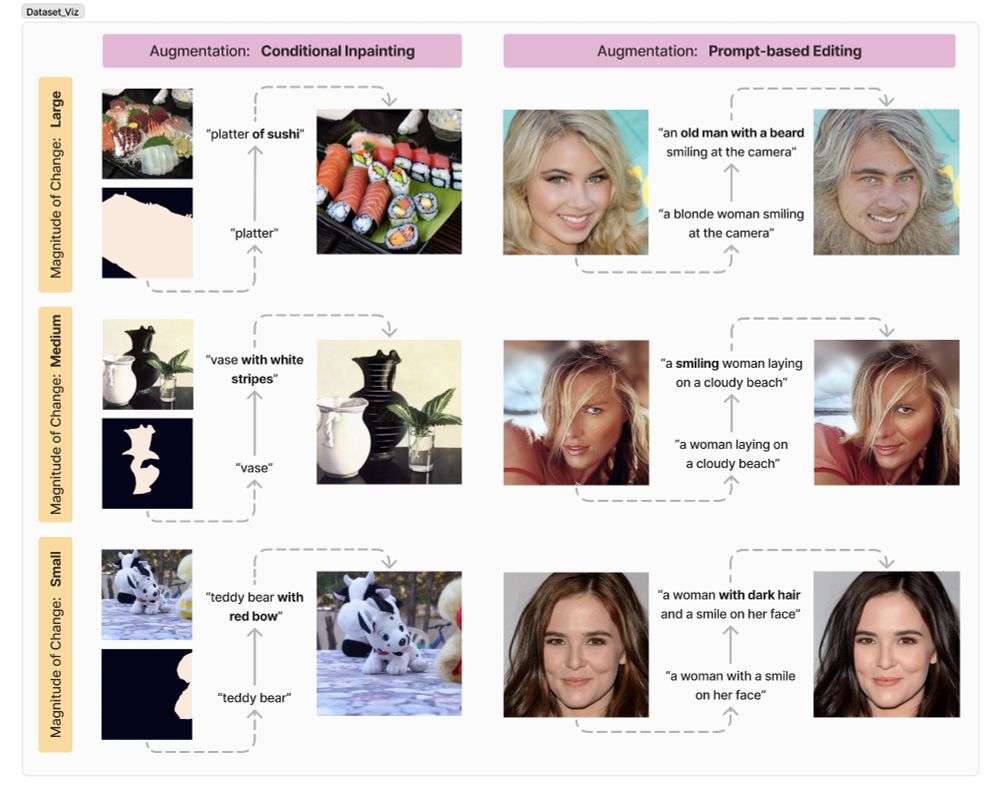
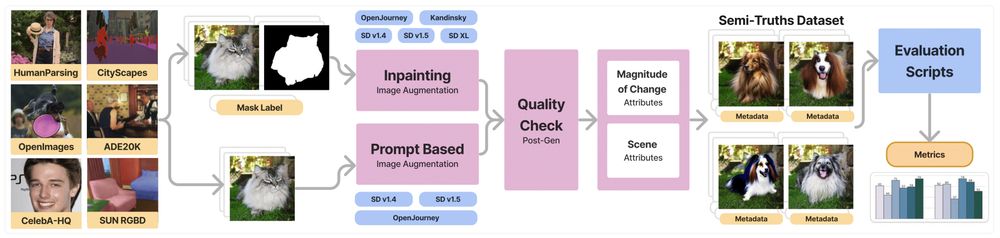
🔧 To control what is changed in an image and how, we use semantic segmentation datasets that provide real images, entity masks, and entity labels.
We perturb entity & image captions with LLMs, then apply different diffusion models and augmentation techniques to alter images.
We perturb entity & image captions with LLMs, then apply different diffusion models and augmentation techniques to alter images.
December 5, 2024 at 1:02 AM
🔧 To control what is changed in an image and how, we use semantic segmentation datasets that provide real images, entity masks, and entity labels.
We perturb entity & image captions with LLMs, then apply different diffusion models and augmentation techniques to alter images.
We perturb entity & image captions with LLMs, then apply different diffusion models and augmentation techniques to alter images.
🚀 We present Semi-Truths, a dataset for the targeted evaluation and training of AI-Augmented Image Detectors.
It includes a wide array of scenes & subjects, as well as various magnitudes of image augmentation. We define “magnitude” by size of the augmented region and the semantic change achieved.
It includes a wide array of scenes & subjects, as well as various magnitudes of image augmentation. We define “magnitude” by size of the augmented region and the semantic change achieved.
December 5, 2024 at 1:02 AM
🚀 We present Semi-Truths, a dataset for the targeted evaluation and training of AI-Augmented Image Detectors.
It includes a wide array of scenes & subjects, as well as various magnitudes of image augmentation. We define “magnitude” by size of the augmented region and the semantic change achieved.
It includes a wide array of scenes & subjects, as well as various magnitudes of image augmentation. We define “magnitude” by size of the augmented region and the semantic change achieved.
An attacker may keep most of the original image, and only change a localized region to drastically change the narrative!
🔍 One such case is known as “Sleepy Joe”, where a video of Joe Biden was changed only in the facial region to make it appear as though he fell asleep at a podium.
🔍 One such case is known as “Sleepy Joe”, where a video of Joe Biden was changed only in the facial region to make it appear as though he fell asleep at a podium.

December 5, 2024 at 1:02 AM
An attacker may keep most of the original image, and only change a localized region to drastically change the narrative!
🔍 One such case is known as “Sleepy Joe”, where a video of Joe Biden was changed only in the facial region to make it appear as though he fell asleep at a podium.
🔍 One such case is known as “Sleepy Joe”, where a video of Joe Biden was changed only in the facial region to make it appear as though he fell asleep at a podium.
Detecting AI-Generated images that can be used to spread misinformation is an impactful area of research in Computer Vision.
🤔 However, the majority of the SOTA systems are trained exclusively on end-to-end fully generated images, or on data from very constrained distributions.
🤔 However, the majority of the SOTA systems are trained exclusively on end-to-end fully generated images, or on data from very constrained distributions.
December 5, 2024 at 1:02 AM
Detecting AI-Generated images that can be used to spread misinformation is an impactful area of research in Computer Vision.
🤔 However, the majority of the SOTA systems are trained exclusively on end-to-end fully generated images, or on data from very constrained distributions.
🤔 However, the majority of the SOTA systems are trained exclusively on end-to-end fully generated images, or on data from very constrained distributions.
Hi!! Would love to be added, thanks
November 25, 2024 at 2:15 AM
Hi!! Would love to be added, thanks
If there’s still room, would love to be added! Thanks for creating this
November 23, 2024 at 5:09 AM
If there’s still room, would love to be added! Thanks for creating this
Hi! I would love to be added! Thanks
November 23, 2024 at 5:04 AM
Hi! I would love to be added! Thanks
Hi! Would love to be added - thanks so much
November 22, 2024 at 9:57 PM
Hi! Would love to be added - thanks so much
This is such a great resource - thanks so much for creating this!
November 22, 2024 at 9:55 PM
This is such a great resource - thanks so much for creating this!