



Alexander Kolesnikov
@kolesnikov.ch
When trained on 'small' data, such as ImageNet-1k, overfitting occurs.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.


December 20, 2024 at 2:39 PM
When trained on 'small' data, such as ImageNet-1k, overfitting occurs.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
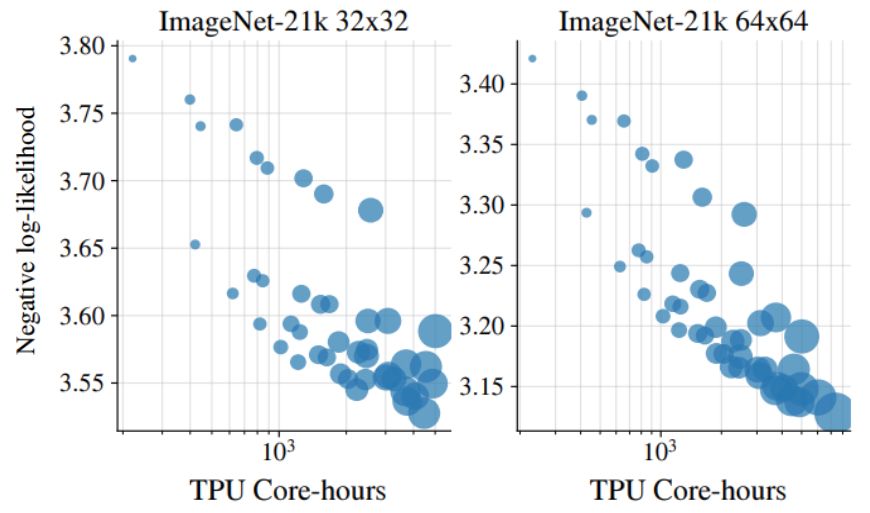
We observe robust performance improvements with compute scaling, showing behavior similar to classical scaling laws.
These are the results of varying the Jet model size when training on ImageNet-21k images:
These are the results of varying the Jet model size when training on ImageNet-21k images:
December 20, 2024 at 2:39 PM
We observe robust performance improvements with compute scaling, showing behavior similar to classical scaling laws.
These are the results of varying the Jet model size when training on ImageNet-21k images:
These are the results of varying the Jet model size when training on ImageNet-21k images:
Our main contribution is a very straightforward design: Jet is just repeated affine coupling layers with ViT inside. We show that many standard components are not needed with our simple design:
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise

December 20, 2024 at 2:39 PM
Our main contribution is a very straightforward design: Jet is just repeated affine coupling layers with ViT inside. We show that many standard components are not needed with our simple design:
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
With some delay, JetFormer's *prequel* paper is finally out on arXiv: a radically simple ViT-based normalizing flow (NF) model that achieves SOTA results in its class.
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️

December 20, 2024 at 2:39 PM
With some delay, JetFormer's *prequel* paper is finally out on arXiv: a radically simple ViT-based normalizing flow (NF) model that achieves SOTA results in its class.
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
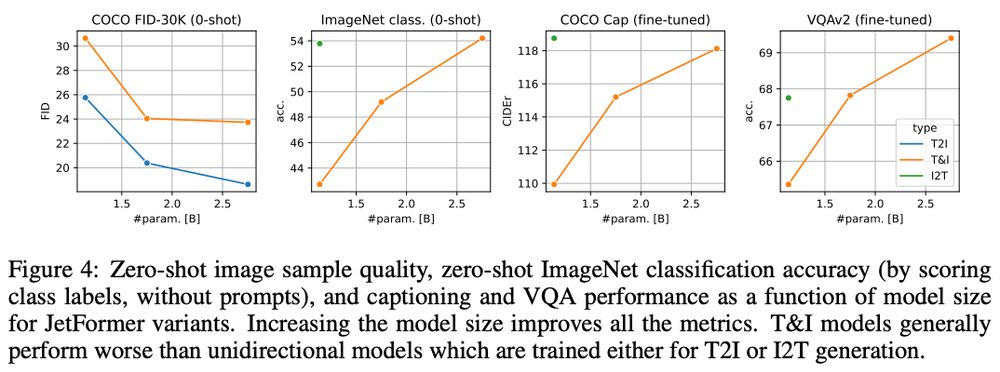
We evaluate JetFormer potential to model large-scale multimodal image+text data and do image-to-text, text-to-image and VQA tasks, and get rather encouraging results.
December 2, 2024 at 5:19 PM
We evaluate JetFormer potential to model large-scale multimodal image+text data and do image-to-text, text-to-image and VQA tasks, and get rather encouraging results.
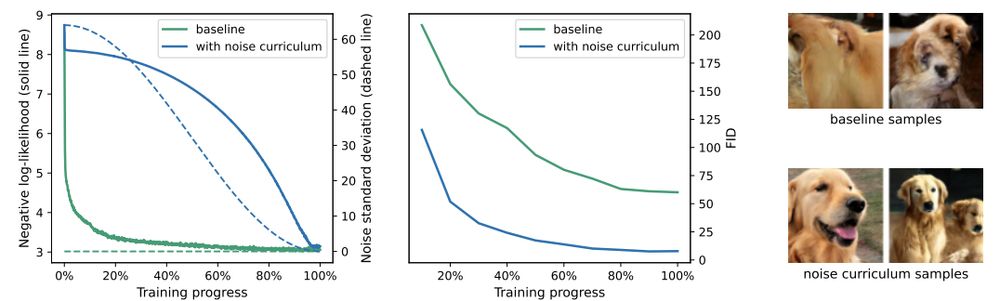
We also present novel data augmentation: "noise curriculum". It helps a pure NLL model to focus on high-level image details.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
December 2, 2024 at 5:19 PM
We also present novel data augmentation: "noise curriculum". It helps a pure NLL model to focus on high-level image details.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
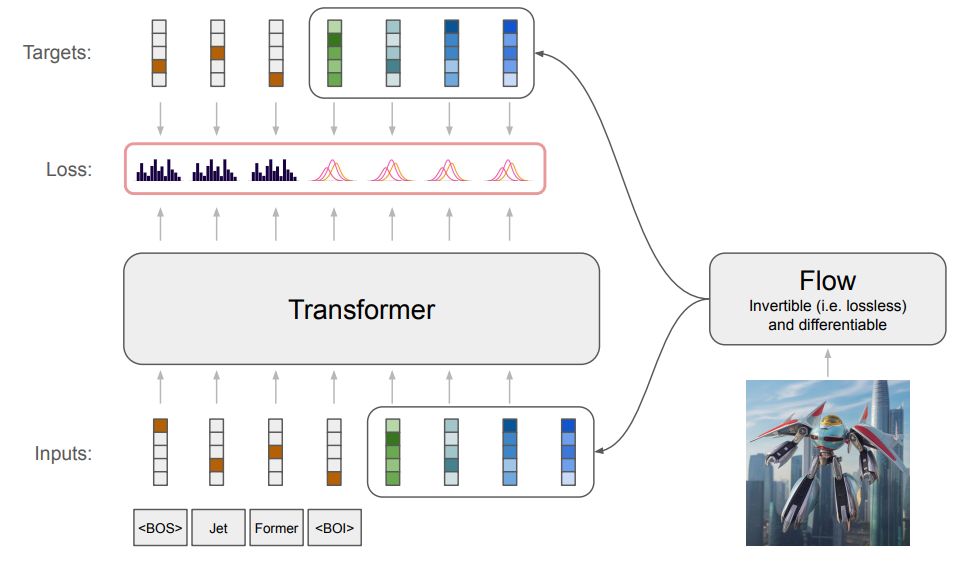
JetFormer is just an autoregressive transformer, trained end-to-end in one go, with no pretrained image encoders/quantizers.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
December 2, 2024 at 5:19 PM
JetFormer is just an autoregressive transformer, trained end-to-end in one go, with no pretrained image encoders/quantizers.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
I always dreamed of a model that simultaneously
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵

December 2, 2024 at 5:19 PM
I always dreamed of a model that simultaneously
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵