
William Merrill
@lambdaviking.bsky.social
490 followers
130 following
19 posts
Will irl - PhD student @ NYU on the academic job market!
Using complexity theory and formal languages to understand the power and limits of LLMs
https://lambdaviking.com/ https://github.com/viking-sudo-rm
Posts
Media
Videos
Starter Packs
Pinned

William Merrill
@lambdaviking.bsky.social
· Nov 26

Reposted by William Merrill


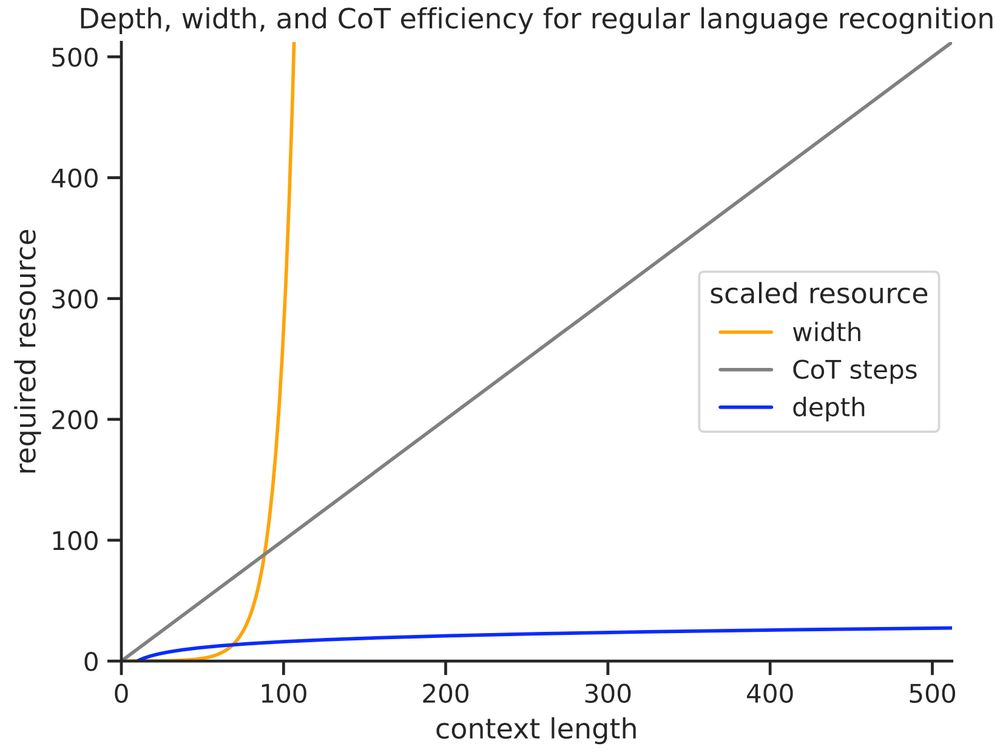
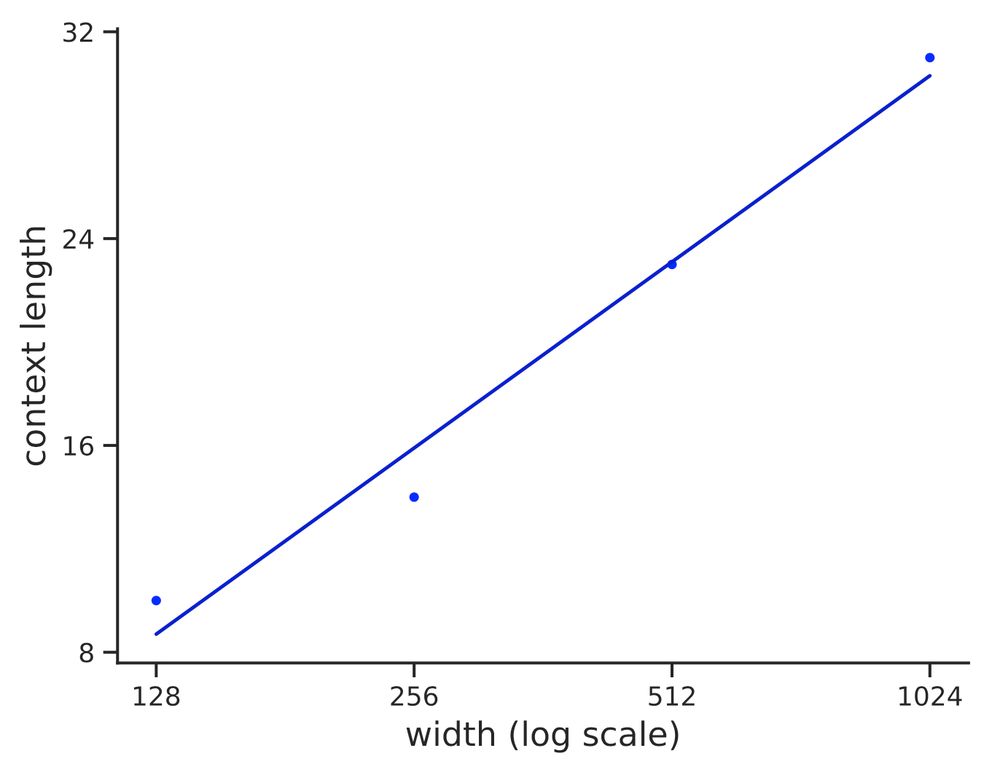
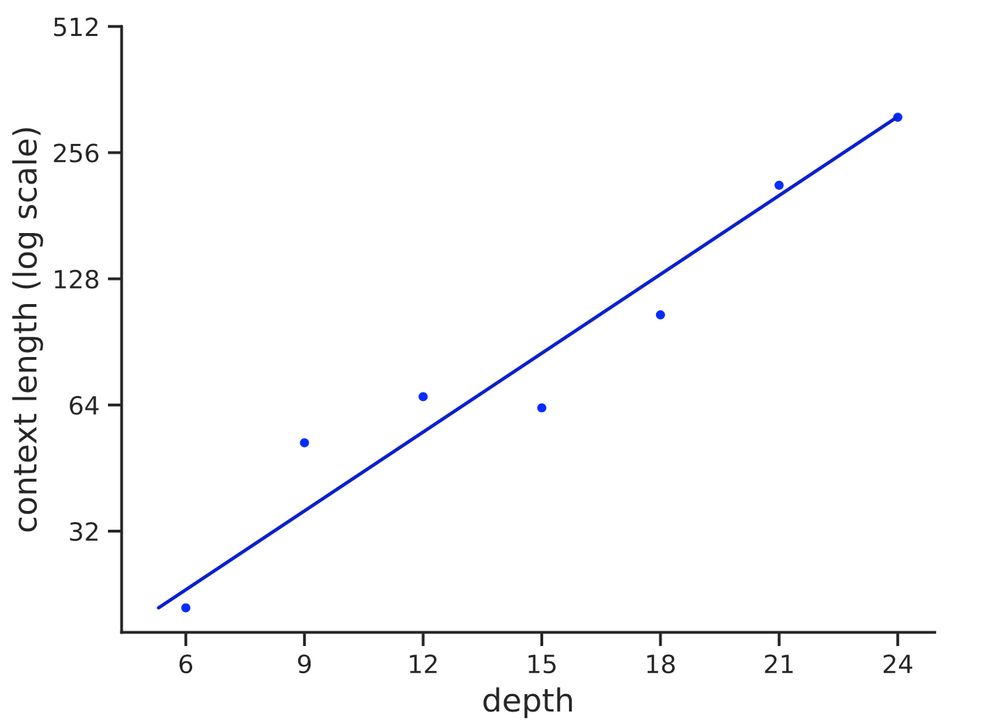
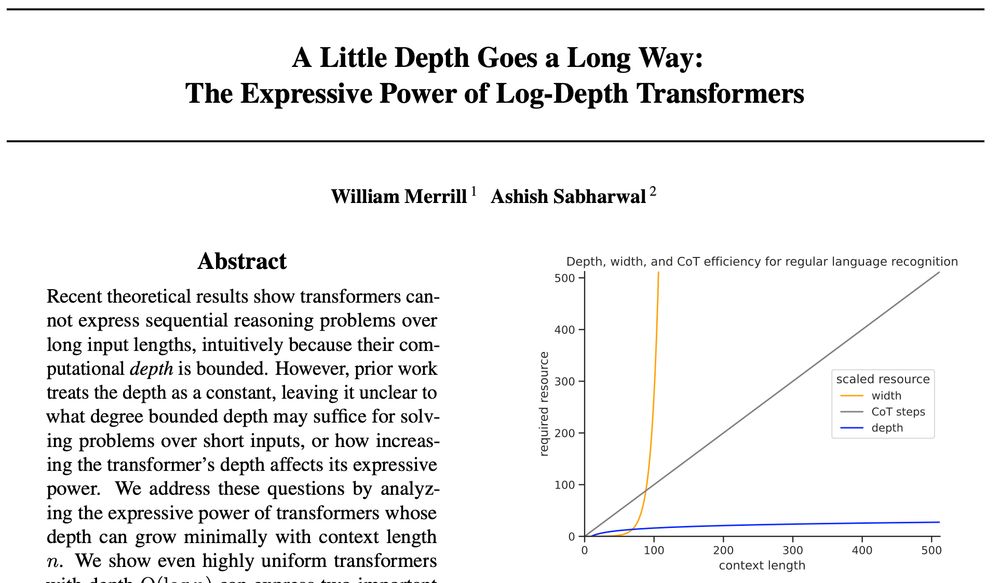
Reposted by William Merrill



Reposted by William Merrill

Shane Steinert-Threlkeld
@shane.st
· Feb 11
North American Summer School on Logic, Language and Information (NASSLLI '25) @ UW
Official website for the North American Summer School for Logic, Language and Information, taking place June 23-27 at the Univeristy of Washington, Seattle.
nasslli25.shane.st
Reposted by William Merrill

William Merrill
@lambdaviking.bsky.social
· Nov 30
William Merrill
@lambdaviking.bsky.social
· Nov 29
William Merrill
@lambdaviking.bsky.social
· Nov 29
William Merrill
@lambdaviking.bsky.social
· Nov 29

Reposted by William Merrill

Luca Soldaini 🎀
@soldaini.net
· Nov 28
Reposted by William Merrill
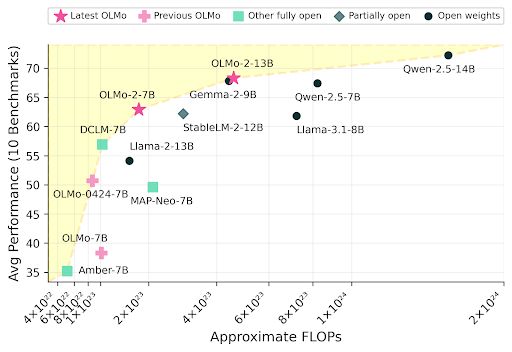
William Merrill
@lambdaviking.bsky.social
· Nov 26
William Merrill
@lambdaviking.bsky.social
· Nov 20