



Marcelo Sandoval-Castañeda
@mudtriangle.com
computer vision phd student @ tti-chicago
part-time @ adobe research
www.mudtriangle.com
he/him
part-time @ adobe research
www.mudtriangle.com
he/him
Reposted by Marcelo Sandoval-Castañeda

💫 I am recruiting exceptional PhD students & postdocs for my lab @tticconnect.bsky.social this year!
Application details: www.ttic.edu/studentappli...
Application details: www.ttic.edu/studentappli...

November 6, 2025 at 12:19 AM
💫 I am recruiting exceptional PhD students & postdocs for my lab @tticconnect.bsky.social this year!
Application details: www.ttic.edu/studentappli...
Application details: www.ttic.edu/studentappli...
Reposted by Marcelo Sandoval-Castañeda

I will be recruiting a few students for Fall 2026. In particular, I will strongly consider a PhD applicant with training in applied/computational mechanics and computer vision/machine learning. If you or someone you know has this background, please contact me.
I’m thrilled to share that I will be joining Johns Hopkins University’s Department of Computer Science (@jhucompsci.bsky.social, @hopkinsdsai.bsky.social) as an Assistant Professor this fall.

October 6, 2025 at 6:39 PM
I will be recruiting a few students for Fall 2026. In particular, I will strongly consider a PhD applicant with training in applied/computational mechanics and computer vision/machine learning. If you or someone you know has this background, please contact me.
Reposted by Marcelo Sandoval-Castañeda
🧠How “old” is your model?
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
KiVA Challenge @ ICCV 2025
kiva-challenge.github.io
July 15, 2025 at 7:19 PM
🧠How “old” is your model?
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Reposted by Marcelo Sandoval-Castañeda
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io

March 29, 2025 at 7:36 PM
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Reposted by Marcelo Sandoval-Castañeda

Ceding techno optimism to the right is a generational scale mistake
January 26, 2025 at 2:33 PM
Ceding techno optimism to the right is a generational scale mistake
Reposted by Marcelo Sandoval-Castañeda

Last night I found out that the NSF math postdoctoral fellowship I applied for is being deleted because it does not comply with Trump’s executive orders on DEI in the federal government. I’m going to answer some FAQs and share some thoughts about this ordeal in this thread 1/n
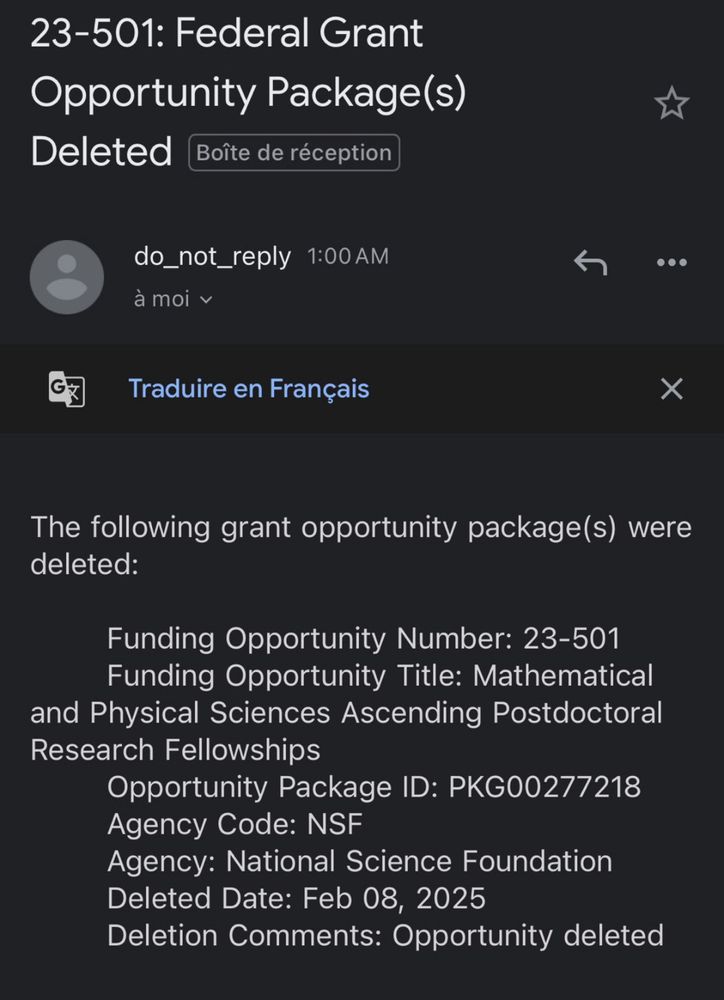
February 8, 2025 at 6:42 PM
Last night I found out that the NSF math postdoctoral fellowship I applied for is being deleted because it does not comply with Trump’s executive orders on DEI in the federal government. I’m going to answer some FAQs and share some thoughts about this ordeal in this thread 1/n
Reposted by Marcelo Sandoval-Castañeda

A dataset of 1 million or 2 million Bluesky posts is completely irrelevant to training large language models.
The primary usecase for the datasets that people are losing their shit over isn't ChatGPT, it's social science research and developing systems that improve Bluesky.
The primary usecase for the datasets that people are losing their shit over isn't ChatGPT, it's social science research and developing systems that improve Bluesky.

Did you know that 99% of email today is spam? Your inbox isn’t 99% spam because AI is used to filter it.
The same 99% will happen here too, but if AI researchers continue to get perma-banned for making available the datasets needed to filter it, it’s going to make this platform unusable.
The same 99% will happen here too, but if AI researchers continue to get perma-banned for making available the datasets needed to filter it, it’s going to make this platform unusable.
November 28, 2024 at 6:57 PM
A dataset of 1 million or 2 million Bluesky posts is completely irrelevant to training large language models.
The primary usecase for the datasets that people are losing their shit over isn't ChatGPT, it's social science research and developing systems that improve Bluesky.
The primary usecase for the datasets that people are losing their shit over isn't ChatGPT, it's social science research and developing systems that improve Bluesky.