



Philipp Schmid
@philschmid.bsky.social
Tech Lead and LLMs at @huggingface 👨🏻💻 🤗 AWS ML Hero 🦸🏻 | Cloud & ML enthusiast | 📍Nuremberg | 🇩🇪 https://philschmid.de
Pinned
Philipp Schmid
@philschmid.bsky.social
· Nov 19

Philschmid
Personal Blog of Philipp Schmid Technical Lead and LLM at Hugging Face. Learn how to use the latest AI and Cloud Technologies from fine-tuning LLMs with RLHF to deploying them in production.
www.philschmid.de
Hello, my name is Philipp. I am a Technical Lead at @huggingface.bsky.social, leading our partnerships with AWS, Google, Azure, or NVIDIA. 🧑🏻💻
I post about the AI News, Open Models, Interesting AI Paper Summaries, blog posts, and guides!
My is blog at www.philschmid.de
Make sure to follow! 🤗
I post about the AI News, Open Models, Interesting AI Paper Summaries, blog posts, and guides!
My is blog at www.philschmid.de
Make sure to follow! 🤗
How we implemented test-time computing for open models to solve complex math problems like OpenAI o1. 👀 Test-time compute methods use dynamic inference strategies to have LLMs “think longer” on harder problems, e.g. difficult math problems.

December 17, 2024 at 7:30 AM
How we implemented test-time computing for open models to solve complex math problems like OpenAI o1. 👀 Test-time compute methods use dynamic inference strategies to have LLMs “think longer” on harder problems, e.g. difficult math problems.
What is better than an LLM as a Judge? Right, an Agent as a Judge! Meta created an Agent-as-a-Judge to evaluate code agents to enable intermediate feedback alongside DevAI a new benchmark of 55 realistic development tasks.
Paper: huggingface.co/papers/2410....
Paper: huggingface.co/papers/2410....

Paper page - Agent-as-a-Judge: Evaluate Agents with Agents
Join the discussion on this paper page
huggingface.co
December 10, 2024 at 9:53 AM
What is better than an LLM as a Judge? Right, an Agent as a Judge! Meta created an Agent-as-a-Judge to evaluate code agents to enable intermediate feedback alongside DevAI a new benchmark of 55 realistic development tasks.
Paper: huggingface.co/papers/2410....
Paper: huggingface.co/papers/2410....
A big day for AI and sad day for the EU. OpenAI releases Sora, their text-to-video model, with a dedicated UI Studio! Sora will be free for all ChatGPT Pro and Plus subscribers without additional cost. Sora will be available to later today, except if you live in the EU or UK. 🤯
December 9, 2024 at 6:41 PM
A big day for AI and sad day for the EU. OpenAI releases Sora, their text-to-video model, with a dedicated UI Studio! Sora will be free for all ChatGPT Pro and Plus subscribers without additional cost. Sora will be available to later today, except if you live in the EU or UK. 🤯
First open-weights for OpenAI-o1-like reasoning model! QwQ from the Qwen team is a 32B model that beats OpenAI O1 mini and competes w/ O1 preview and is available under Apache 2.0 on Hugging Face! 🤯

November 28, 2024 at 8:01 AM
First open-weights for OpenAI-o1-like reasoning model! QwQ from the Qwen team is a 32B model that beats OpenAI O1 mini and competes w/ O1 preview and is available under Apache 2.0 on Hugging Face! 🤯
SmolLM can now see! 👀 Meet SmolVLM - a tiny 2B but powerful vision language model that runs on your device! Built on top of SmolLM and released under Apache 2.0. 🚀

November 26, 2024 at 4:31 PM
SmolLM can now see! 👀 Meet SmolVLM - a tiny 2B but powerful vision language model that runs on your device! Built on top of SmolLM and released under Apache 2.0. 🚀
How far can we push LLM optimizations? Turns out, pretty far! A new study achieves 98% accuracy recovery on key benchmarks while removing 50% of Llama 3.1 8B's parameters using pruning. Pruning strategically to remove unnecessary connections in a neural network to make it smaller and faster. 👀

November 26, 2024 at 8:24 AM
How far can we push LLM optimizations? Turns out, pretty far! A new study achieves 98% accuracy recovery on key benchmarks while removing 50% of Llama 3.1 8B's parameters using pruning. Pruning strategically to remove unnecessary connections in a neural network to make it smaller and faster. 👀
TIL: @huggingface.bsky.social Transformers has native Tensor Parallelism support for better inference on multiple GPUs! This will enable many benefits and optimizations in the future.🚀
For now, it supports Llama. Which one would you want to see next?
For now, it supports Llama. Which one would you want to see next?

November 25, 2024 at 3:50 PM
TIL: @huggingface.bsky.social Transformers has native Tensor Parallelism support for better inference on multiple GPUs! This will enable many benefits and optimizations in the future.🚀
For now, it supports Llama. Which one would you want to see next?
For now, it supports Llama. Which one would you want to see next?
Created a visual for how function calling works. Wdyt? 🤔

November 25, 2024 at 11:34 AM
Created a visual for how function calling works. Wdyt? 🤔
Does Structured Outputs hurt LLM performance? 🤔 The paper "Let Me Speak Freely" paper claimed that it does, but new experiments by @dottxtai.bsky.social (team behind outlines) show it doesn’t if you do it correctly! 👀

November 25, 2024 at 7:25 AM
Does Structured Outputs hurt LLM performance? 🤔 The paper "Let Me Speak Freely" paper claimed that it does, but new experiments by @dottxtai.bsky.social (team behind outlines) show it doesn’t if you do it correctly! 👀
What is the latest in open-source post-training? Allen AI released Tülu last week, which includes models, all of the data, training recipes, code, infrastructure, and evaluation framework. Here are my insights! 👀

November 24, 2024 at 10:09 AM
What is the latest in open-source post-training? Allen AI released Tülu last week, which includes models, all of the data, training recipes, code, infrastructure, and evaluation framework. Here are my insights! 👀
Open Source Post Training is going strong! In last 2 weeks, we got data or recipes released for OpenCoder, SmolLM-2, Orca Agent Instruct, and Tülu 3. Read it, learn, and iterate:

November 23, 2024 at 7:45 AM
Open Source Post Training is going strong! In last 2 weeks, we got data or recipes released for OpenCoder, SmolLM-2, Orca Agent Instruct, and Tülu 3. Read it, learn, and iterate:
# 2024-11-22
SQLite is all you need! Big sqlite-vec update! 🚀 sqlite-vec is a plugin to support Vector Search in SQLite or LibSQL databases. v0.1.6 now allows storing non-vector data in vec0 virtual tables, enabling metadata conditioning and filtering! 🤯
SQLite is all you need! Big sqlite-vec update! 🚀 sqlite-vec is a plugin to support Vector Search in SQLite or LibSQL databases. v0.1.6 now allows storing non-vector data in vec0 virtual tables, enabling metadata conditioning and filtering! 🤯

November 22, 2024 at 4:37 PM
# 2024-11-22
SQLite is all you need! Big sqlite-vec update! 🚀 sqlite-vec is a plugin to support Vector Search in SQLite or LibSQL databases. v0.1.6 now allows storing non-vector data in vec0 virtual tables, enabling metadata conditioning and filtering! 🤯
SQLite is all you need! Big sqlite-vec update! 🚀 sqlite-vec is a plugin to support Vector Search in SQLite or LibSQL databases. v0.1.6 now allows storing non-vector data in vec0 virtual tables, enabling metadata conditioning and filtering! 🤯
Add your BSKY 🦋 to your @huggingface.bsky.social profile!
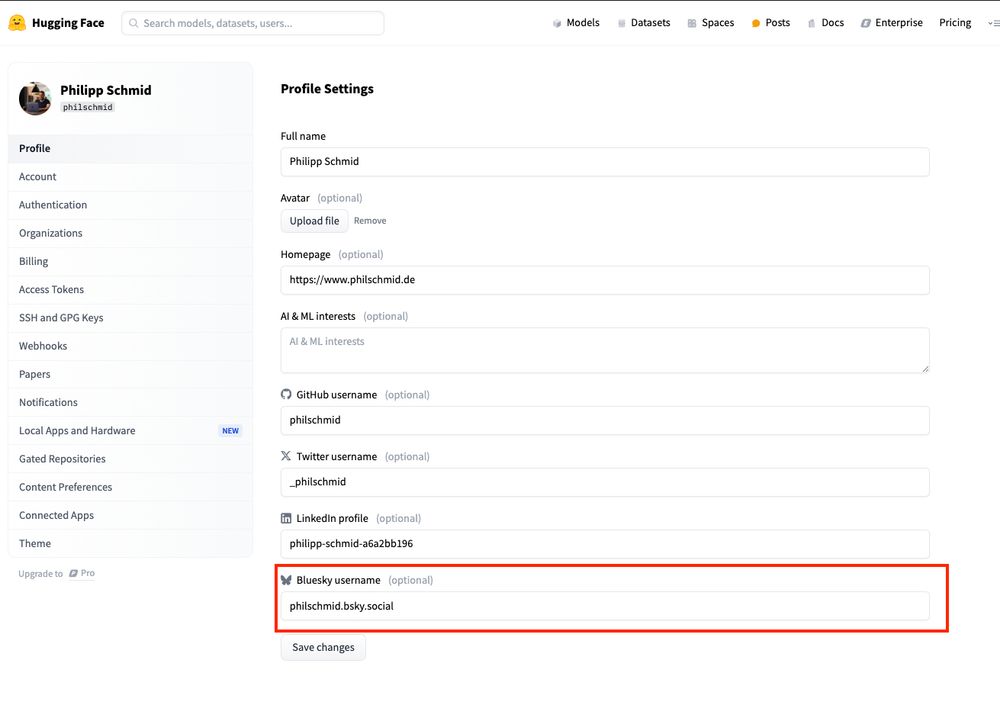
November 22, 2024 at 4:06 PM
Add your BSKY 🦋 to your @huggingface.bsky.social profile!
New small hybrid model from NVIDIA has been announced! Hymba is a 1.5B hybrid Mamba x Attention Model that outperforms other small LLMs like Meta 3.2 or SmolLM v2 being trained on only 1.5T Tokens. 🤯

November 22, 2024 at 5:42 AM
New small hybrid model from NVIDIA has been announced! Hymba is a 1.5B hybrid Mamba x Attention Model that outperforms other small LLMs like Meta 3.2 or SmolLM v2 being trained on only 1.5T Tokens. 🤯
🚀 Biggest open text dataset release of the year!
SmolTalk: a 1M sample synthetic dataset used to train SmolLM v2 is here! Available under Apache 2.0, it combines newly generated datasets + publicly available ones.
Here’s what you need to know 🧵👇
SmolTalk: a 1M sample synthetic dataset used to train SmolLM v2 is here! Available under Apache 2.0, it combines newly generated datasets + publicly available ones.
Here’s what you need to know 🧵👇

November 21, 2024 at 2:06 PM
🚀 Biggest open text dataset release of the year!
SmolTalk: a 1M sample synthetic dataset used to train SmolLM v2 is here! Available under Apache 2.0, it combines newly generated datasets + publicly available ones.
Here’s what you need to know 🧵👇
SmolTalk: a 1M sample synthetic dataset used to train SmolLM v2 is here! Available under Apache 2.0, it combines newly generated datasets + publicly available ones.
Here’s what you need to know 🧵👇
With the preview of deepseek R1 and results equal to OpenAI o1-preview, you might want to take look at "Stream of Search".
R1, "thoughts" are streamed, no MCTS is used during inference. They must have baked the "search" and "backtracking" directly into the model. huggingface.co/papers/2404....
R1, "thoughts" are streamed, no MCTS is used during inference. They must have baked the "search" and "backtracking" directly into the model. huggingface.co/papers/2404....

Paper page - Stream of Search (SoS): Learning to Search in Language
Join the discussion on this paper page
huggingface.co
November 21, 2024 at 7:23 AM
With the preview of deepseek R1 and results equal to OpenAI o1-preview, you might want to take look at "Stream of Search".
R1, "thoughts" are streamed, no MCTS is used during inference. They must have baked the "search" and "backtracking" directly into the model. huggingface.co/papers/2404....
R1, "thoughts" are streamed, no MCTS is used during inference. They must have baked the "search" and "backtracking" directly into the model. huggingface.co/papers/2404....
Mindblowing! 🤯 New reasoning model preview from Deepseek that matches OpenAI o1! 🐳 DeepSeek-R1-Lite-Preview is now live to test! 🧠
> o1-preview-level performance on AIME & MATH benchmarks.
> Access to CoT and transparent thought process in real-time.
> Open-source models & API coming soon!
> o1-preview-level performance on AIME & MATH benchmarks.
> Access to CoT and transparent thought process in real-time.
> Open-source models & API coming soon!
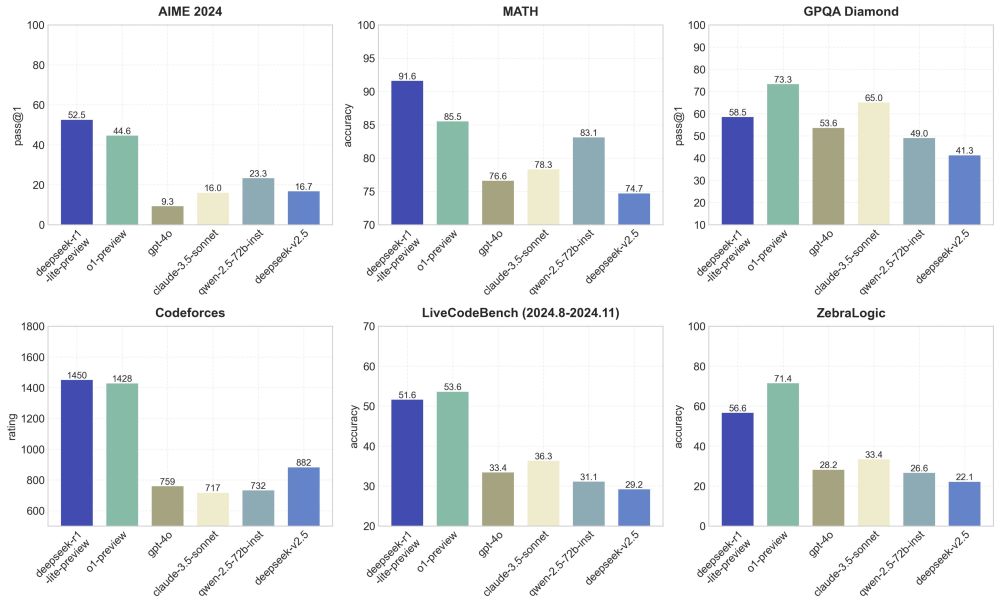
November 20, 2024 at 12:04 PM
Mindblowing! 🤯 New reasoning model preview from Deepseek that matches OpenAI o1! 🐳 DeepSeek-R1-Lite-Preview is now live to test! 🧠
> o1-preview-level performance on AIME & MATH benchmarks.
> Access to CoT and transparent thought process in real-time.
> Open-source models & API coming soon!
> o1-preview-level performance on AIME & MATH benchmarks.
> Access to CoT and transparent thought process in real-time.
> Open-source models & API coming soon!
Sage Attention the next Flash Attention? 🤔
> 3x speed up over Flash Attention2, maintaining 99% performance
> INT4/8 for Q and K matrices, and FP8/16 for P and V + smoothing methods for Q and V
> Drop-in replacement of torch scaled_dot_product_attention
> SageAttention 2 code to be released soon
> 3x speed up over Flash Attention2, maintaining 99% performance
> INT4/8 for Q and K matrices, and FP8/16 for P and V + smoothing methods for Q and V
> Drop-in replacement of torch scaled_dot_product_attention
> SageAttention 2 code to be released soon

November 20, 2024 at 8:11 AM
Sage Attention the next Flash Attention? 🤔
> 3x speed up over Flash Attention2, maintaining 99% performance
> INT4/8 for Q and K matrices, and FP8/16 for P and V + smoothing methods for Q and V
> Drop-in replacement of torch scaled_dot_product_attention
> SageAttention 2 code to be released soon
> 3x speed up over Flash Attention2, maintaining 99% performance
> INT4/8 for Q and K matrices, and FP8/16 for P and V + smoothing methods for Q and V
> Drop-in replacement of torch scaled_dot_product_attention
> SageAttention 2 code to be released soon
The Microsoft Ignite conference starts today. Here is a summary of all the new AI announcements around Azure, OpenAI, Github and more! 👀
November 19, 2024 at 4:50 PM
The Microsoft Ignite conference starts today. Here is a summary of all the new AI announcements around Azure, OpenAI, Github and more! 👀
Hello, my name is Philipp. I am a Technical Lead at @huggingface.bsky.social, leading our partnerships with AWS, Google, Azure, or NVIDIA. 🧑🏻💻
I post about the AI News, Open Models, Interesting AI Paper Summaries, blog posts, and guides!
My is blog at www.philschmid.de
Make sure to follow! 🤗
I post about the AI News, Open Models, Interesting AI Paper Summaries, blog posts, and guides!
My is blog at www.philschmid.de
Make sure to follow! 🤗
Philschmid
Personal Blog of Philipp Schmid Technical Lead and LLM at Hugging Face. Learn how to use the latest AI and Cloud Technologies from fine-tuning LLMs with RLHF to deploying them in production.
www.philschmid.de
November 19, 2024 at 1:12 PM
Hello, my name is Philipp. I am a Technical Lead at @huggingface.bsky.social, leading our partnerships with AWS, Google, Azure, or NVIDIA. 🧑🏻💻
I post about the AI News, Open Models, Interesting AI Paper Summaries, blog posts, and guides!
My is blog at www.philschmid.de
Make sure to follow! 🤗
I post about the AI News, Open Models, Interesting AI Paper Summaries, blog posts, and guides!
My is blog at www.philschmid.de
Make sure to follow! 🤗