Pierre Chambon
@pierrechambon.bsky.social
24 followers
66 following
27 posts
PhD at FAIR (Meta) and INRIA
Former researcher at Stanford University
Posts
Media
Videos
Starter Packs

Pierre Chambon
@pierrechambon.bsky.social
· Apr 16

Pierre Chambon
@pierrechambon.bsky.social
· Apr 10
Pierre Chambon
@pierrechambon.bsky.social
· Apr 10
Pierre Chambon
@pierrechambon.bsky.social
· Apr 10

Pierre Chambon
@pierrechambon.bsky.social
· Mar 27

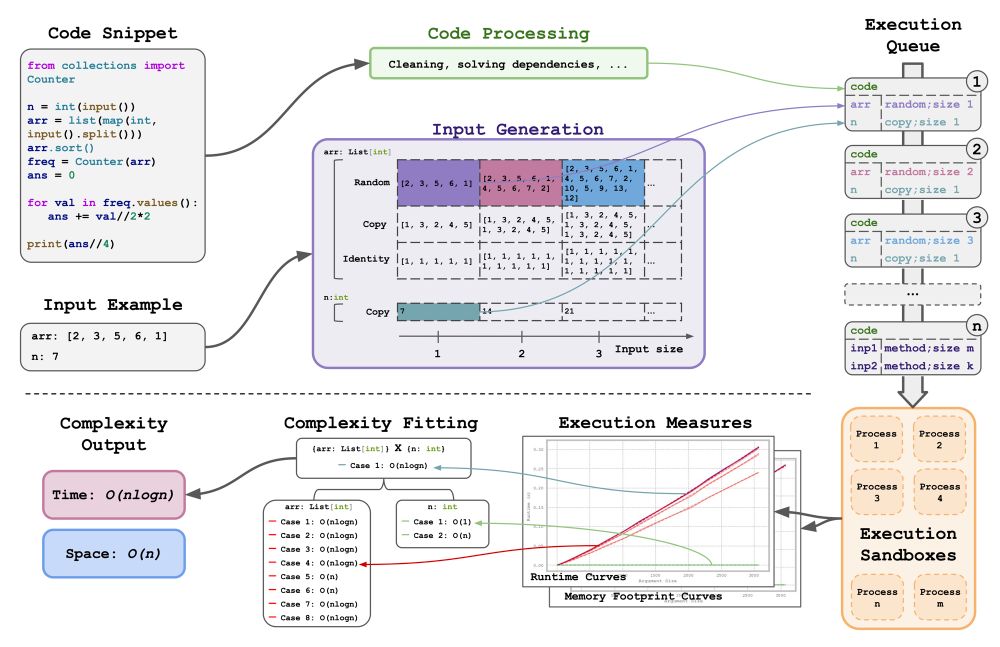
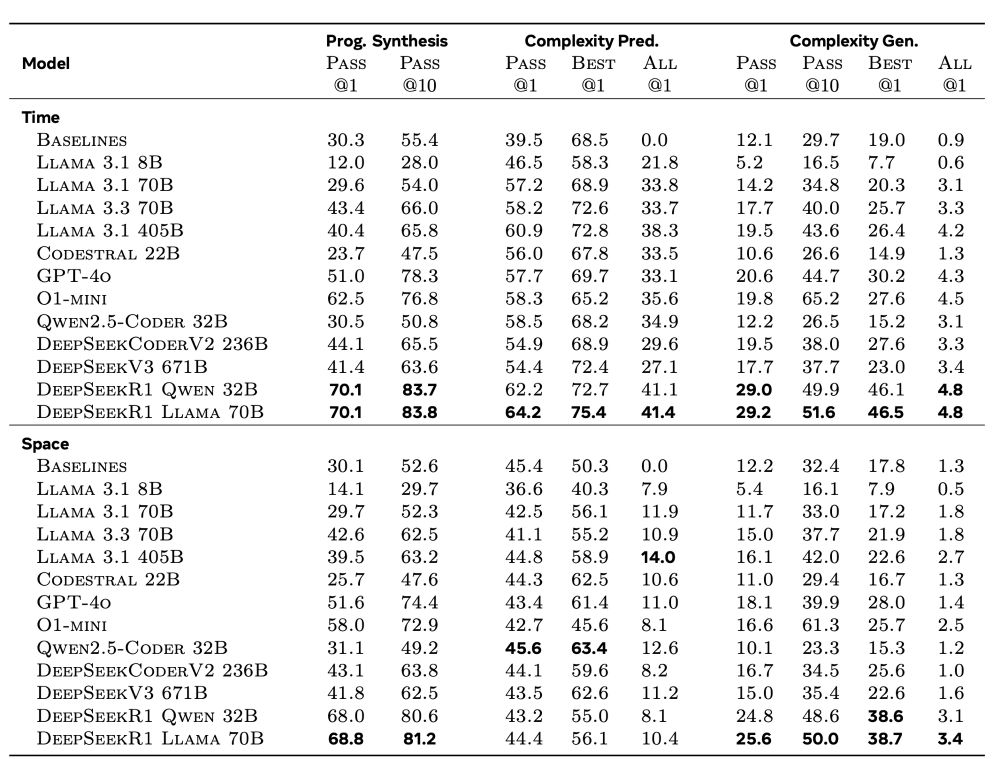
BigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. ...
arxiv.org
Pierre Chambon
@pierrechambon.bsky.social
· Mar 27
Pierre Chambon
@pierrechambon.bsky.social
· Mar 27
Pierre Chambon
@pierrechambon.bsky.social
· Mar 27

Pierre Chambon
@pierrechambon.bsky.social
· Mar 27

GitHub - facebookresearch/BigOBench: BigOBench assesses the capacity of Large Language Models (LLMs) to comprehend time-space computational complexity of input or generated code.
BigOBench assesses the capacity of Large Language Models (LLMs) to comprehend time-space computational complexity of input or generated code. - facebookresearch/BigOBench
github.com
Pierre Chambon
@pierrechambon.bsky.social
· Mar 20
BigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. ...
arxiv.org
Pierre Chambon
@pierrechambon.bsky.social
· Mar 20

Pierre Chambon
@pierrechambon.bsky.social
· Mar 20

Pierre Chambon
@pierrechambon.bsky.social
· Mar 20