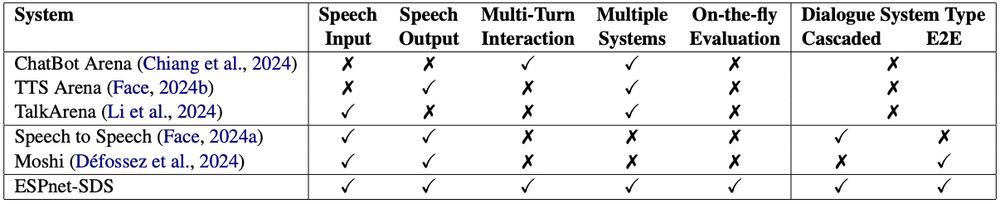
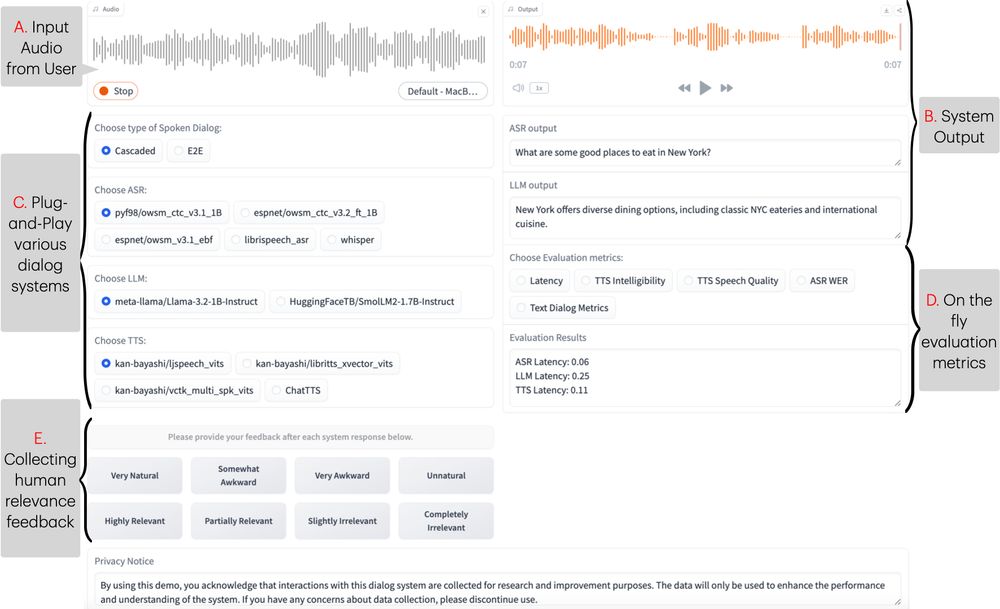
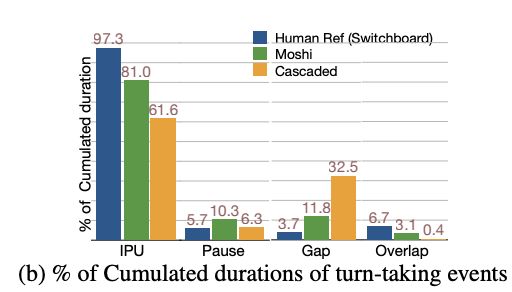
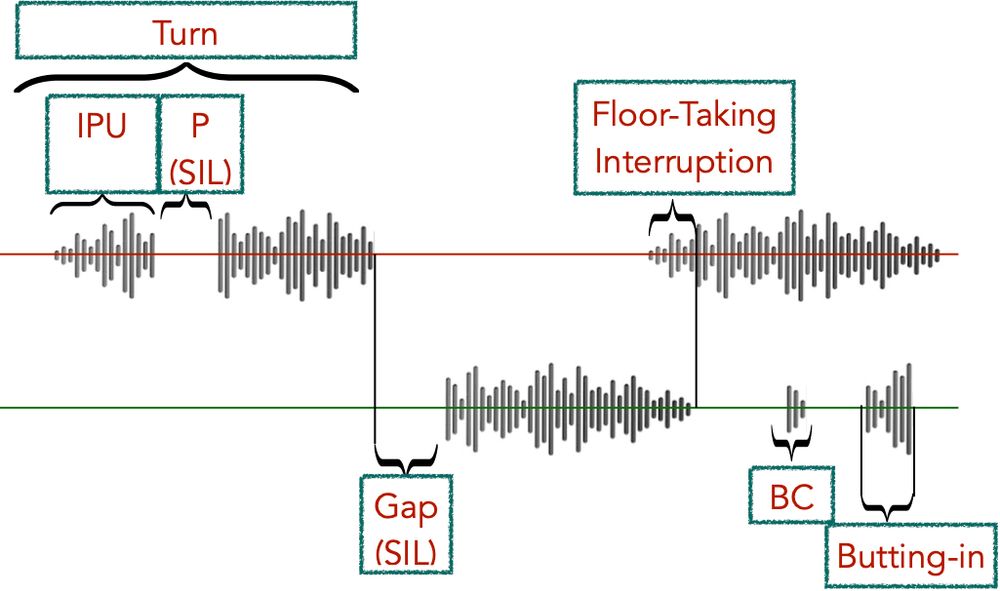
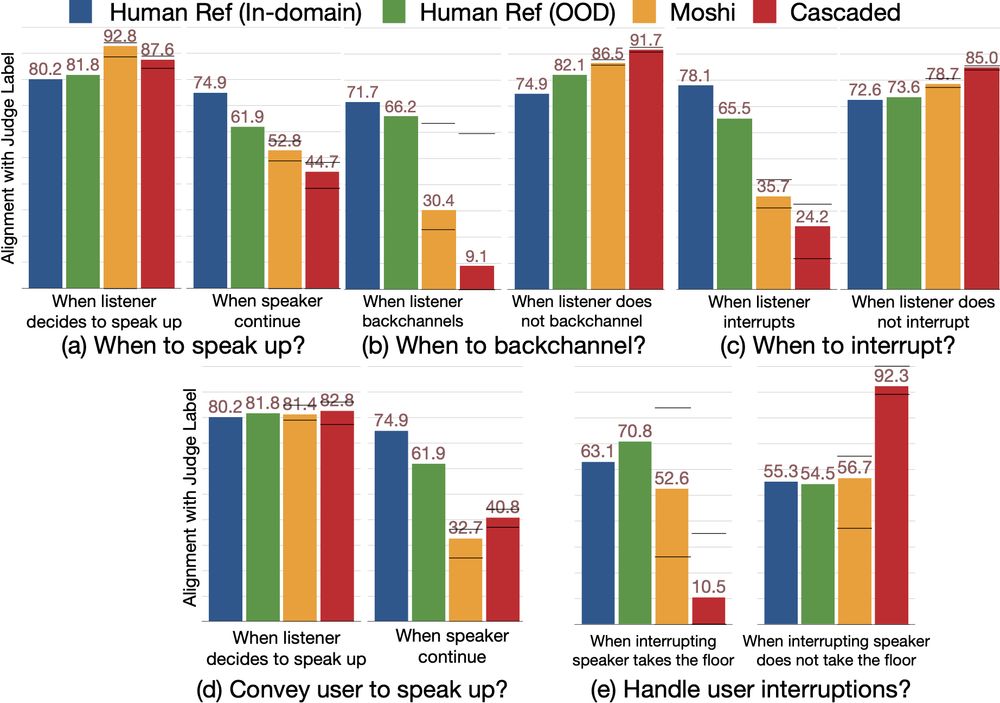
We compare E2E (Moshi
us.moshi.chat) & cascaded (
github.com/huggingface/...) dialogue systems through user study with global corpus level statistics!
Moshi: small gaps, some overlap—but less than natural dialogue
Cascaded: higher latency, minimal overlap.
(4/9)