



Kaivalya Apte
@thegeeknarrator.bsky.social
Podcaster, Youtuber @TheGeekNarrator
(https://youtube.com/@thegeeknarrator?si=yN0zWNDAScJKv_QZ), Staff Platform Engineer @Personio
(https://youtube.com/@thegeeknarrator?si=yN0zWNDAScJKv_QZ), Staff Platform Engineer @Personio
What is State Machine thinking and how do I use it (practically)?
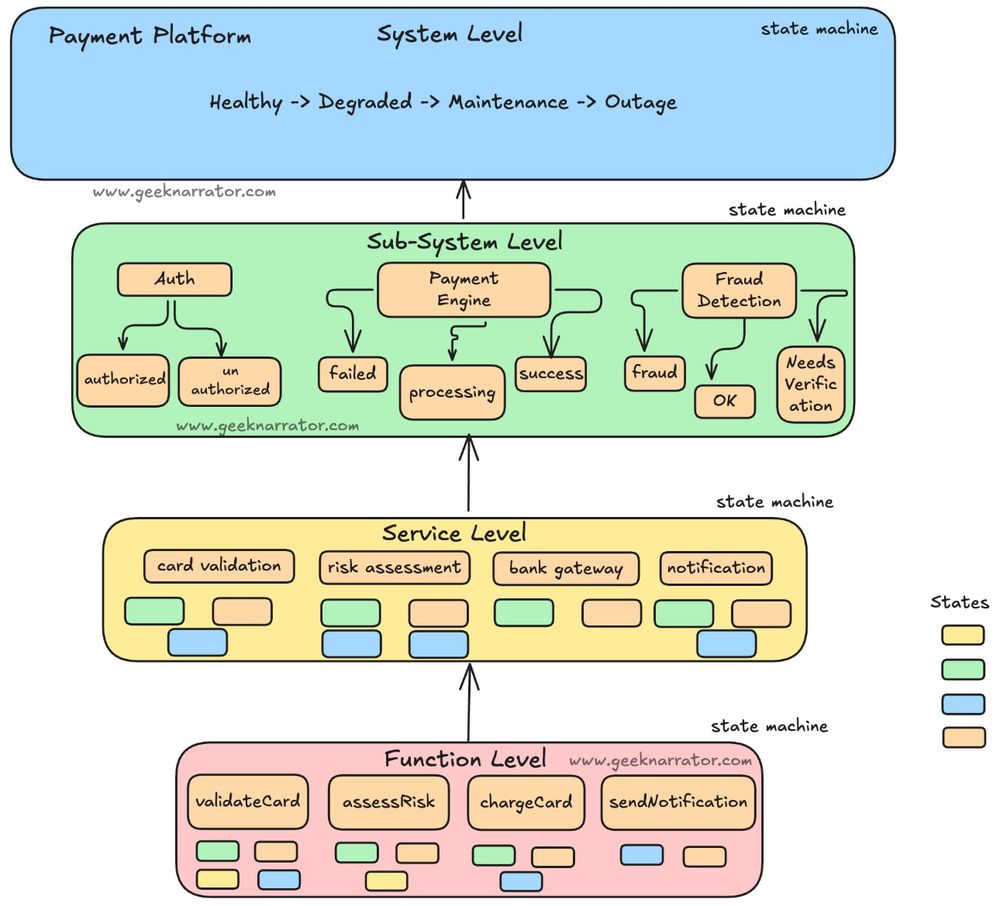
State machine thinking is one of the best ways to build reliable software. The idea is to break down complex systems into discrete states and explicit transitions between them.
State machine thinking is one of the best ways to build reliable software. The idea is to break down complex systems into discrete states and explicit transitions between them.
June 15, 2025 at 8:33 AM
What is State Machine thinking and how do I use it (practically)?
State machine thinking is one of the best ways to build reliable software. The idea is to break down complex systems into discrete states and explicit transitions between them.
State machine thinking is one of the best ways to build reliable software. The idea is to break down complex systems into discrete states and explicit transitions between them.
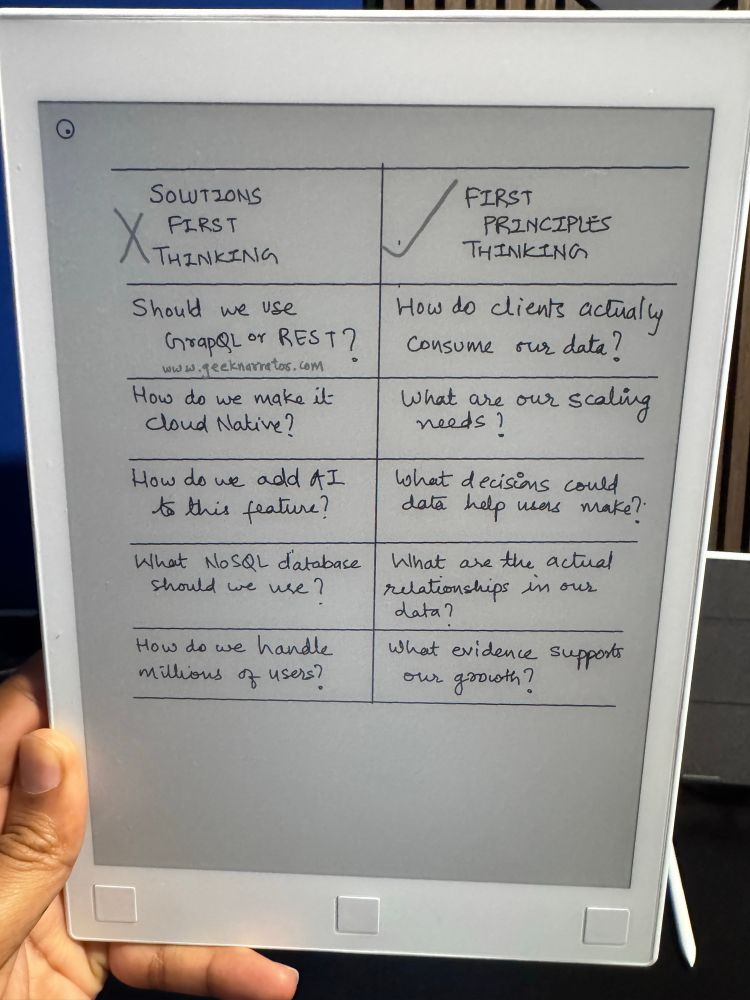
What is First principles thinking and how do I use it (practically) ?👇
First-principles thinking is one of the best ways to tackle complex problems.
The idea is to break down complex problems into primitive elements and then reassemble the problem from scratch.
First-principles thinking is one of the best ways to tackle complex problems.
The idea is to break down complex problems into primitive elements and then reassemble the problem from scratch.
June 14, 2025 at 11:59 AM
What is First principles thinking and how do I use it (practically) ?👇
First-principles thinking is one of the best ways to tackle complex problems.
The idea is to break down complex problems into primitive elements and then reassemble the problem from scratch.
First-principles thinking is one of the best ways to tackle complex problems.
The idea is to break down complex problems into primitive elements and then reassemble the problem from scratch.
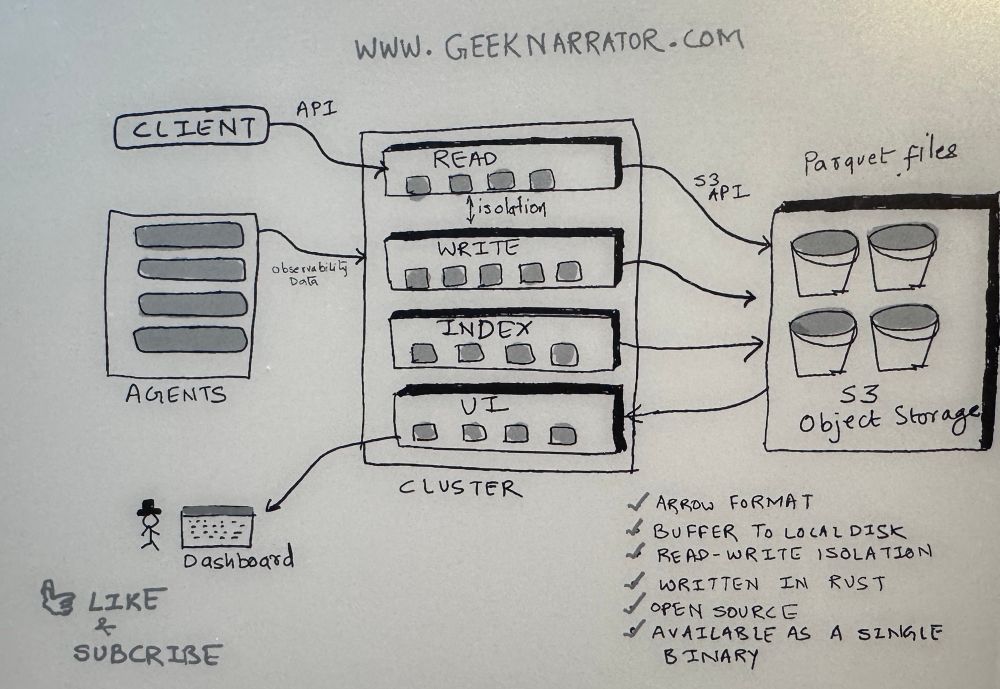
Here is a sketch of how a solid observability platform built on top of object storage would look like this 👇
And guess what, Parseable is built exactly like that. All the good stuff that makes a system fast, reliable and highly scalable.
New episode 🚀
youtu.be/MugLlrf5E_g
And guess what, Parseable is built exactly like that. All the good stuff that makes a system fast, reliable and highly scalable.
New episode 🚀
youtu.be/MugLlrf5E_g
June 11, 2025 at 4:02 PM
Here is a sketch of how a solid observability platform built on top of object storage would look like this 👇
And guess what, Parseable is built exactly like that. All the good stuff that makes a system fast, reliable and highly scalable.
New episode 🚀
youtu.be/MugLlrf5E_g
And guess what, Parseable is built exactly like that. All the good stuff that makes a system fast, reliable and highly scalable.
New episode 🚀
youtu.be/MugLlrf5E_g
Diskless Kafka?
But why?
Why is it important for Kafka ecosystem ?
How does it compare with existing revolutionary technologies?
Blogged a comparison between Diskless Kafka, WarpStream and Confluent Freight. www.geeknarrator.com/blog/diskles...
But why?
Why is it important for Kafka ecosystem ?
How does it compare with existing revolutionary technologies?
Blogged a comparison between Diskless Kafka, WarpStream and Confluent Freight. www.geeknarrator.com/blog/diskles...

June 9, 2025 at 7:20 PM
Diskless Kafka?
But why?
Why is it important for Kafka ecosystem ?
How does it compare with existing revolutionary technologies?
Blogged a comparison between Diskless Kafka, WarpStream and Confluent Freight. www.geeknarrator.com/blog/diskles...
But why?
Why is it important for Kafka ecosystem ?
How does it compare with existing revolutionary technologies?
Blogged a comparison between Diskless Kafka, WarpStream and Confluent Freight. www.geeknarrator.com/blog/diskles...
DUPLICATE events and painfully SLOW joins are a real and painful problems in the world of stream processing and realtime analytics.
But why there hasn't been a simple, easy and fast solution for these problems that just works with the hassle?
But why there hasn't been a simple, easy and fast solution for these problems that just works with the hassle?

May 8, 2025 at 8:18 AM
DUPLICATE events and painfully SLOW joins are a real and painful problems in the world of stream processing and realtime analytics.
But why there hasn't been a simple, easy and fast solution for these problems that just works with the hassle?
But why there hasn't been a simple, easy and fast solution for these problems that just works with the hassle?
BLOGGED 🎉 - Diskless Kafka KIP-1150
Wrote a detailed blog on why I think diskless Kafka is going to be HUGE.
Do check it out here:
www.geeknarrator.com/blog/diskless-kafka-kip-1150
Thanks Aiven for sponsoring the blog.
Wrote a detailed blog on why I think diskless Kafka is going to be HUGE.
Do check it out here:
www.geeknarrator.com/blog/diskless-kafka-kip-1150
Thanks Aiven for sponsoring the blog.

May 3, 2025 at 1:31 PM
BLOGGED 🎉 - Diskless Kafka KIP-1150
Wrote a detailed blog on why I think diskless Kafka is going to be HUGE.
Do check it out here:
www.geeknarrator.com/blog/diskless-kafka-kip-1150
Thanks Aiven for sponsoring the blog.
Wrote a detailed blog on why I think diskless Kafka is going to be HUGE.
Do check it out here:
www.geeknarrator.com/blog/diskless-kafka-kip-1150
Thanks Aiven for sponsoring the blog.
Watch this episode to learn about amazing performance optimisation techniques. Link below👇 Redpanda - High Performance Streaming Platform for Data Intensive Applications @RedpandaData
youtu.be/lAlqa9H5FQY
youtu.be/lAlqa9H5FQY

March 1, 2025 at 3:58 PM
Watch this episode to learn about amazing performance optimisation techniques. Link below👇 Redpanda - High Performance Streaming Platform for Data Intensive Applications @RedpandaData
youtu.be/lAlqa9H5FQY
youtu.be/lAlqa9H5FQY
The JVM internals series - #5 is out..
This episode lays out a good foundation for us to go into the internals of each of the amazing GCs and their tradeoffs.
Become a member to access the upcoming internals episode.. Meanwhile watch this video (free access until tomorrow). youtu.be/p1Yamdly0QE
This episode lays out a good foundation for us to go into the internals of each of the amazing GCs and their tradeoffs.
Become a member to access the upcoming internals episode.. Meanwhile watch this video (free access until tomorrow). youtu.be/p1Yamdly0QE

February 2, 2025 at 12:47 PM
The JVM internals series - #5 is out..
This episode lays out a good foundation for us to go into the internals of each of the amazing GCs and their tradeoffs.
Become a member to access the upcoming internals episode.. Meanwhile watch this video (free access until tomorrow). youtu.be/p1Yamdly0QE
This episode lays out a good foundation for us to go into the internals of each of the amazing GCs and their tradeoffs.
Become a member to access the upcoming internals episode.. Meanwhile watch this video (free access until tomorrow). youtu.be/p1Yamdly0QE
New episode "Patterns of Distributed Systems" is up now..
Experience based, Actionable insights is what you can expect from this episode.
Enjoy: youtu.be/HnyKJq8oR0M
Image taken from: martinfowler.com/articles/pat...
Experience based, Actionable insights is what you can expect from this episode.
Enjoy: youtu.be/HnyKJq8oR0M
Image taken from: martinfowler.com/articles/pat...

January 30, 2025 at 5:51 PM
New episode "Patterns of Distributed Systems" is up now..
Experience based, Actionable insights is what you can expect from this episode.
Enjoy: youtu.be/HnyKJq8oR0M
Image taken from: martinfowler.com/articles/pat...
Experience based, Actionable insights is what you can expect from this episode.
Enjoy: youtu.be/HnyKJq8oR0M
Image taken from: martinfowler.com/articles/pat...
What happens when you create a "new" Object in Java?
What are the challenges in a multithreaded environment?
Does GC play any role in object creation?
New video will answer these questions for you.
Get access here
www.youtube.com/channel/UC_m...
Link to the video:
youtu.be/qfcnB8kciCE
What are the challenges in a multithreaded environment?
Does GC play any role in object creation?
New video will answer these questions for you.
Get access here
www.youtube.com/channel/UC_m...
Link to the video:
youtu.be/qfcnB8kciCE

January 20, 2025 at 4:15 AM
What happens when you create a "new" Object in Java?
What are the challenges in a multithreaded environment?
Does GC play any role in object creation?
New video will answer these questions for you.
Get access here
www.youtube.com/channel/UC_m...
Link to the video:
youtu.be/qfcnB8kciCE
What are the challenges in a multithreaded environment?
Does GC play any role in object creation?
New video will answer these questions for you.
Get access here
www.youtube.com/channel/UC_m...
Link to the video:
youtu.be/qfcnB8kciCE
Important conclusion for implementations:
"converts a tradeoff between update and range query costs into a mutually beneficial synergy between batching small updates and large nodes"
"converts a tradeoff between update and range query costs into a mutually beneficial synergy between batching small updates and large nodes"

January 2, 2025 at 3:40 PM
Important conclusion for implementations:
"converts a tradeoff between update and range query costs into a mutually beneficial synergy between batching small updates and large nodes"
"converts a tradeoff between update and range query costs into a mutually beneficial synergy between batching small updates and large nodes"
Some notes on how buffers are organised:
Buffers are organised into balanced binary "search" tree, ex. Red-black tree.
Buffers are organised into balanced binary "search" tree, ex. Red-black tree.

January 2, 2025 at 3:40 PM
Some notes on how buffers are organised:
Buffers are organised into balanced binary "search" tree, ex. Red-black tree.
Buffers are organised into balanced binary "search" tree, ex. Red-black tree.
Maintain Appropriate Indices:
- Indices are cheap to maintain in B"-trees, so create indices for all keys used in queries.
- Ensure each index contains all necessary information to answer queries, known as a covering index.
- Design indices to support efficient range queries.
- Indices are cheap to maintain in B"-trees, so create indices for all keys used in queries.
- Ensure each index contains all necessary information to answer queries, known as a covering index.
- Design indices to support efficient range queries.

January 2, 2025 at 3:40 PM
Maintain Appropriate Indices:
- Indices are cheap to maintain in B"-trees, so create indices for all keys used in queries.
- Ensure each index contains all necessary information to answer queries, known as a covering index.
- Design indices to support efficient range queries.
- Indices are cheap to maintain in B"-trees, so create indices for all keys used in queries.
- Ensure each index contains all necessary information to answer queries, known as a covering index.
- Design indices to support efficient range queries.
Upserts are inserted into the tree and applied when they reach the leaf, improving update performance without slowing down queries.

January 2, 2025 at 3:40 PM
Upserts are inserted into the tree and applied when they reach the leaf, improving update performance without slowing down queries.
Performance rules to make Bε-trees work for your application:
Avoid Query-Before-Update: Due to the search-insert asymmetry, avoid the read-modify-write pattern as it will be bound to the speed of a query.
Avoid Query-Before-Update: Due to the search-insert asymmetry, avoid the read-modify-write pattern as it will be bound to the speed of a query.

January 2, 2025 at 3:40 PM
Performance rules to make Bε-trees work for your application:
Avoid Query-Before-Update: Due to the search-insert asymmetry, avoid the read-modify-write pattern as it will be bound to the speed of a query.
Avoid Query-Before-Update: Due to the search-insert asymmetry, avoid the read-modify-write pattern as it will be bound to the speed of a query.
The following sequence diagram aims to show all ops in one diagram, (ambitious but works I guess..)

January 2, 2025 at 3:40 PM
The following sequence diagram aims to show all ops in one diagram, (ambitious but works I guess..)
To make sure the application returns correct state, query also needs to check the buffers to make sure it considers the latest message for the keys.

January 2, 2025 at 3:40 PM
To make sure the application returns correct state, query also needs to check the buffers to make sure it considers the latest message for the keys.
But what happens when a read comes for something that is marked as "to be deleted" but hasn't really been deleted?

January 2, 2025 at 3:40 PM
But what happens when a read comes for something that is marked as "to be deleted" but hasn't really been deleted?
The value of 𝜖 gives us the ability to tune the space requirements for pivots and buffers in an internal node.
I believe this needs to be tuned based on the type of workloads..
𝜖 must be between 0 and 1.
I believe this needs to be tuned based on the type of workloads..
𝜖 must be between 0 and 1.

January 2, 2025 at 3:40 PM
The value of 𝜖 gives us the ability to tune the space requirements for pivots and buffers in an internal node.
I believe this needs to be tuned based on the type of workloads..
𝜖 must be between 0 and 1.
I believe this needs to be tuned based on the type of workloads..
𝜖 must be between 0 and 1.
Eventually, means the messages aren't necessarily processed immediately, i.e. changes to the values aren't immediately made.

January 2, 2025 at 3:40 PM
Eventually, means the messages aren't necessarily processed immediately, i.e. changes to the values aren't immediately made.
APIs are also similar to a B-Tree (key value store apis)

January 2, 2025 at 3:40 PM
APIs are also similar to a B-Tree (key value store apis)
Bε-trees were proposed to demonstrate a performance trade-off between fast queries and fast updates in external memory data structures.

January 2, 2025 at 3:40 PM
Bε-trees were proposed to demonstrate a performance trade-off between fast queries and fast updates in external memory data structures.
I started my 2025 reading white-paper(s) on Bε-trees. A thread that captures everything you need to know about them and more..
Like, repost and share..👇
Like, repost and share..👇

January 2, 2025 at 3:40 PM
I started my 2025 reading white-paper(s) on Bε-trees. A thread that captures everything you need to know about them and more..
Like, repost and share..👇
Like, repost and share..👇
One of the Holiday projects completed. Was tougher than what I thought and easier than what my wife thought.
Now movie time. One of my favourites.
Now movie time. One of my favourites.


December 28, 2024 at 7:43 PM
One of the Holiday projects completed. Was tougher than what I thought and easier than what my wife thought.
Now movie time. One of my favourites.
Now movie time. One of my favourites.
A couple of more books and I am all set.
2025 is going to be amazing.
Stronger fundamentals.
More Deep work.
Quality content.
Along with podcasts, it will be filled with series on Distributed systems, JVM internals, Database internals and Stream processing.
2025 is going to be amazing.
Stronger fundamentals.
More Deep work.
Quality content.
Along with podcasts, it will be filled with series on Distributed systems, JVM internals, Database internals and Stream processing.


December 28, 2024 at 12:48 PM
A couple of more books and I am all set.
2025 is going to be amazing.
Stronger fundamentals.
More Deep work.
Quality content.
Along with podcasts, it will be filled with series on Distributed systems, JVM internals, Database internals and Stream processing.
2025 is going to be amazing.
Stronger fundamentals.
More Deep work.
Quality content.
Along with podcasts, it will be filled with series on Distributed systems, JVM internals, Database internals and Stream processing.