


Open Access UCL Research: UiO-UvA at SemEval-2020 Task 1: Contextualised Embeddings for Lexical Semantic Change Detection discovery.ucl.ac.uk/id/eprint/10...
UiO-UvA at SemEval-2020 Task 1: Contextualised Embeddings for Lexical Semantic Change Detection
-
UCL Discovery
UCL Discovery is UCL's open access repository, showcasing and providing access to UCL research outputs from all UCL disciplines.
discovery.ucl.ac.uk
November 7, 2025 at 3:42 PM
Open Access UCL Research: UiO-UvA at SemEval-2020 Task 1: Contextualised Embeddings for Lexical Semantic Change Detection discovery.ucl.ac.uk/id/eprint/10...

My main dataset trajectory was TI-DIGITS, WSJ0, Aurora5, CHiME-1-3, Librispeech and a lot of speech and language ML competition data (SemEval, MediaEval, ComPARe), internal data and WMT(QE), back to Librispeech, AMR DARPA stuff, again internal and then excels and excels of LLM benchmarks
Evolution of AI benchmarks is like:
Toy-Bench-1997
unreasonably-clean-data-Bench
5y-old-Bench
2y-old-Bench
Live-Bench (collected last year)
Alive-Bench (real world, real time user satisfaction stats)
Prediction-Market-Bench what's Geminis perf. EoY?
Toy-Bench-1997
unreasonably-clean-data-Bench
5y-old-Bench
2y-old-Bench
Live-Bench (collected last year)
Alive-Bench (real world, real time user satisfaction stats)
Prediction-Market-Bench what's Geminis perf. EoY?
October 18, 2025 at 4:39 PM
My main dataset trajectory was TI-DIGITS, WSJ0, Aurora5, CHiME-1-3, Librispeech and a lot of speech and language ML competition data (SemEval, MediaEval, ComPARe), internal data and WMT(QE), back to Librispeech, AMR DARPA stuff, again internal and then excels and excels of LLM benchmarks

Shared Tasks at https://semeval.github.io/
- SemEval 2023 Task 12: AfriSenti https://afrisenti-semeval.github.io/
- SemEval 2024 Task 1: SemRel https://semantic-textual-relatedness.github.io/
- SemEval 2025 Task 11: Bridging the Gap https://github.com/emotion-analysis-project/SemEval2025-task11 […]
- SemEval 2023 Task 12: AfriSenti https://afrisenti-semeval.github.io/
- SemEval 2024 Task 1: SemRel https://semantic-textual-relatedness.github.io/
- SemEval 2025 Task 11: Bridging the Gap https://github.com/emotion-analysis-project/SemEval2025-task11 […]
Original post on hcommons.social
hcommons.social
September 24, 2025 at 12:04 PM
Shared Tasks at https://semeval.github.io/
- SemEval 2023 Task 12: AfriSenti https://afrisenti-semeval.github.io/
- SemEval 2024 Task 1: SemRel https://semantic-textual-relatedness.github.io/
- SemEval 2025 Task 11: Bridging the Gap https://github.com/emotion-analysis-project/SemEval2025-task11 […]
- SemEval 2023 Task 12: AfriSenti https://afrisenti-semeval.github.io/
- SemEval 2024 Task 1: SemRel https://semantic-textual-relatedness.github.io/
- SemEval 2025 Task 11: Bridging the Gap https://github.com/emotion-analysis-project/SemEval2025-task11 […]

Pleased to announce our #NLP SemEval Task 7: Everyday Knowledge Across Diverse Languages & Cultures.
We extend the BLEnD Benchmark to >30 language-culture pairs. [Our task is Junior-friendly, with live Q&A & tutorials.] 1/
We extend the BLEnD Benchmark to >30 language-culture pairs. [Our task is Junior-friendly, with live Q&A & tutorials.] 1/

September 22, 2025 at 11:14 AM
Pleased to announce our #NLP SemEval Task 7: Everyday Knowledge Across Diverse Languages & Cultures.
We extend the BLEnD Benchmark to >30 language-culture pairs. [Our task is Junior-friendly, with live Q&A & tutorials.] 1/
We extend the BLEnD Benchmark to >30 language-culture pairs. [Our task is Junior-friendly, with live Q&A & tutorials.] 1/

“MWAHAHA, which stands for Models Write Automatic Humor And Humans Annotate, is SemEval 2026's Task 1 and is the first task dedicated to advancing the state of the art in Computational Humor Generation.”
MWAHAHA: A Competition on Humor Generation […]
MWAHAHA: A Competition on Humor Generation […]
Original post on mastodon.social
mastodon.social
September 8, 2025 at 1:06 PM
“MWAHAHA, which stands for Models Write Automatic Humor And Humans Annotate, is SemEval 2026's Task 1 and is the first task dedicated to advancing the state of the art in Computational Humor Generation.”
MWAHAHA: A Competition on Humor Generation […]
MWAHAHA: A Competition on Humor Generation […]

Best Paper Award für die Publikation „DNB-AI-Project at SemEval-2025 Task 5: An LLM-Ensemble Approach for Automated Subject Indexing": blog.dnb.de/ki-projekt-g...
📸 DNB, Maximilian Kähler, Lisa Kluge CC BY 4.0
📸 DNB, Maximilian Kähler, Lisa Kluge CC BY 4.0
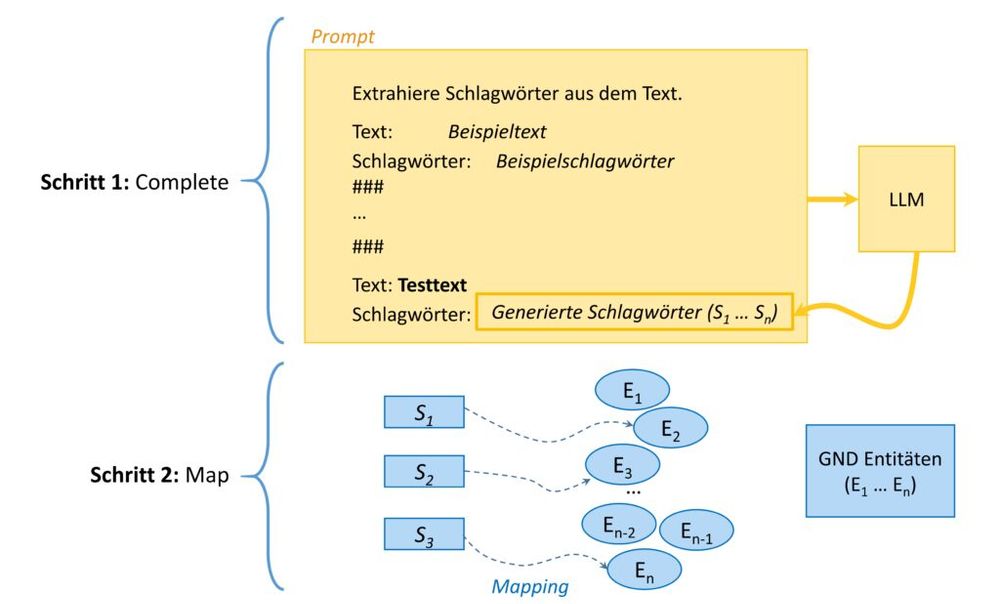
September 2, 2025 at 11:21 AM
Best Paper Award für die Publikation „DNB-AI-Project at SemEval-2025 Task 5: An LLM-Ensemble Approach for Automated Subject Indexing": blog.dnb.de/ki-projekt-g...
📸 DNB, Maximilian Kähler, Lisa Kluge CC BY 4.0
📸 DNB, Maximilian Kähler, Lisa Kluge CC BY 4.0

Earlier this year, the Annif team participated in the LLMs4Subjects challenge, where our automated indexing tool performed nicely! 🏆 We also got new ideas for Annif development out of the challenge! The SemEval-2025 workshop proceedings are now available 👉 […]
Original post on some.kansalliskirjasto.fi
some.kansalliskirjasto.fi
August 28, 2025 at 10:58 AM
Earlier this year, the Annif team participated in the LLMs4Subjects challenge, where our automated indexing tool performed nicely! 🏆 We also got new ideas for Annif development out of the challenge! The SemEval-2025 workshop proceedings are now available 👉 […]
Annif-tiimi osallistui alkuvuodesta LLMs4Subjects-haasteeseen, jossa automaattisen asiasanoituksen työkalumme pärjäsi hienosti! 🏆 Saimme kisasta uusia ideoita Annifin kehitykseen! SemEval-2025-työpajan julkaisut ovat nyt luettavissa 👉 https://aclanthology.org/volumes/2025.semeval-1/
Haaste […]
Haaste […]
Original post on some.kansalliskirjasto.fi
some.kansalliskirjasto.fi
August 28, 2025 at 10:58 AM
Annif-tiimi osallistui alkuvuodesta LLMs4Subjects-haasteeseen, jossa automaattisen asiasanoituksen työkalumme pärjäsi hienosti! 🏆 Saimme kisasta uusia ideoita Annifin kehitykseen! SemEval-2025-työpajan julkaisut ovat nyt luettavissa 👉 https://aclanthology.org/volumes/2025.semeval-1/
Haaste […]
Haaste […]

Ladislav Lenc, Daniel C\'ifka, Ji\v{r}\'i Mart\'inek, Jakub \v{S}m\'id, Pavel Kr\'al
UWBa at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
https://arxiv.org/abs/2508.09517
UWBa at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
https://arxiv.org/abs/2508.09517
August 14, 2025 at 6:50 AM
Ladislav Lenc, Daniel C\'ifka, Ji\v{r}\'i Mart\'inek, Jakub \v{S}m\'id, Pavel Kr\'al
UWBa at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
https://arxiv.org/abs/2508.09517
UWBa at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
https://arxiv.org/abs/2508.09517

Ladislav Lenc, Daniel C\'ifka, Ji\v{r}\'i Mart\'inek, Jakub \v{S}m\'id, Pavel Kr\'al: UWBa at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval https://arxiv.org/abs/2508.09517 https://arxiv.org/pdf/2508.09517 https://arxiv.org/html/2508.09517
August 14, 2025 at 6:30 AM
Ladislav Lenc, Daniel C\'ifka, Ji\v{r}\'i Mart\'inek, Jakub \v{S}m\'id, Pavel Kr\'al: UWBa at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval https://arxiv.org/abs/2508.09517 https://arxiv.org/pdf/2508.09517 https://arxiv.org/html/2508.09517
Adri\'an Gude, Roi Santos-R\'ios, Francisco Prado-Vali\~no, Ana Ezquerro, Jes\'us Vilares: LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA https://arxiv.org/abs/2508.09012 https://arxiv.org/pdf/2508.09012 https://arxiv.org/html/2508.09012
August 13, 2025 at 6:30 AM
Adri\'an Gude, Roi Santos-R\'ios, Francisco Prado-Vali\~no, Ana Ezquerro, Jes\'us Vilares: LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA https://arxiv.org/abs/2508.09012 https://arxiv.org/pdf/2508.09012 https://arxiv.org/html/2508.09012
Adri\'an Gude, Roi Santos-R\'ios, Francisco Prado-Vali\~no, Ana Ezquerro, Jes\'us Vilares
LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA
https://arxiv.org/abs/2508.09012
LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA
https://arxiv.org/abs/2508.09012
August 13, 2025 at 5:50 AM
Adri\'an Gude, Roi Santos-R\'ios, Francisco Prado-Vali\~no, Ana Ezquerro, Jes\'us Vilares
LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA
https://arxiv.org/abs/2508.09012
LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA
https://arxiv.org/abs/2508.09012

... if I include myself in Gen X, then I might say as a very Gen X thing to say that I did not know I would be published in ACL and now I wish I had tried to find a better team name than Jim. Or whatever, aclanthology.org/2025.semeval...

Jim at SemEval-2025 Task 5: Multilingual BERT Ensemble
Jim Hahn. Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025). 2025.
aclanthology.org
August 11, 2025 at 5:45 PM
... if I include myself in Gen X, then I might say as a very Gen X thing to say that I did not know I would be published in ACL and now I wish I had tried to find a better team name than Jim. Or whatever, aclanthology.org/2025.semeval...
Catherine Kobus, Fran\c{c}ois Lancelot, Marion-C\'ecile Martin, Nawal Ould Amer
ATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering
https://arxiv.org/abs/2508.05179
ATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering
https://arxiv.org/abs/2508.05179
August 8, 2025 at 6:45 AM
Catherine Kobus, Fran\c{c}ois Lancelot, Marion-C\'ecile Martin, Nawal Ould Amer
ATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering
https://arxiv.org/abs/2508.05179
ATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering
https://arxiv.org/abs/2508.05179
Catherine Kobus, Fran\c{c}ois Lancelot, Marion-C\'ecile Martin, Nawal Ould Amer: ATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering https://arxiv.org/abs/2508.05179 https://arxiv.org/pdf/2508.05179 https://arxiv.org/html/2508.05179
August 8, 2025 at 6:30 AM
Catherine Kobus, Fran\c{c}ois Lancelot, Marion-C\'ecile Martin, Nawal Ould Amer: ATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering https://arxiv.org/abs/2508.05179 https://arxiv.org/pdf/2508.05179 https://arxiv.org/html/2508.05179
Pranshu Rastogi: fact check AI at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-checked Claim Retrieval https://arxiv.org/abs/2508.03475 https://arxiv.org/pdf/2508.03475 https://arxiv.org/html/2508.03475
August 6, 2025 at 6:30 AM
Pranshu Rastogi: fact check AI at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-checked Claim Retrieval https://arxiv.org/abs/2508.03475 https://arxiv.org/pdf/2508.03475 https://arxiv.org/html/2508.03475
Pranshu Rastogi
fact check AI at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-checked Claim Retrieval
https://arxiv.org/abs/2508.03475
fact check AI at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-checked Claim Retrieval
https://arxiv.org/abs/2508.03475
August 6, 2025 at 6:01 AM
Pranshu Rastogi
fact check AI at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-checked Claim Retrieval
https://arxiv.org/abs/2508.03475
fact check AI at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-checked Claim Retrieval
https://arxiv.org/abs/2508.03475
Jiyu Chen, Necva B\"ol\"uc\"u, Sarvnaz Karimi, Diego Moll\'a, C\'ecile L. Paris
CSIRO-LT at SemEval-2025 Task 11: Adapting LLMs for Emotion Recognition for Multiple Languages
https://arxiv.org/abs/2508.01161
CSIRO-LT at SemEval-2025 Task 11: Adapting LLMs for Emotion Recognition for Multiple Languages
https://arxiv.org/abs/2508.01161
August 5, 2025 at 10:53 AM
Jiyu Chen, Necva B\"ol\"uc\"u, Sarvnaz Karimi, Diego Moll\'a, C\'ecile L. Paris
CSIRO-LT at SemEval-2025 Task 11: Adapting LLMs for Emotion Recognition for Multiple Languages
https://arxiv.org/abs/2508.01161
CSIRO-LT at SemEval-2025 Task 11: Adapting LLMs for Emotion Recognition for Multiple Languages
https://arxiv.org/abs/2508.01161
Jiyu Chen, Necva B\"ol\"uc\"u, Sarvnaz Karimi, Diego Moll\'a, C\'ecile L. Paris: CSIRO-LT at SemEval-2025 Task 11: Adapting LLMs for Emotion Recognition for Multiple Languages https://arxiv.org/abs/2508.01161 https://arxiv.org/pdf/2508.01161 https://arxiv.org/html/2508.01161
August 5, 2025 at 6:29 AM
Jiyu Chen, Necva B\"ol\"uc\"u, Sarvnaz Karimi, Diego Moll\'a, C\'ecile L. Paris: CSIRO-LT at SemEval-2025 Task 11: Adapting LLMs for Emotion Recognition for Multiple Languages https://arxiv.org/abs/2508.01161 https://arxiv.org/pdf/2508.01161 https://arxiv.org/html/2508.01161

🚀Excited to announce our MTRAGEval task at SemEval 2026!
Arxiv: arxiv.org/abs/2501.03468
Github: github.com/IBM/mt-rag-b... (please 🌟!)
MTRAGEval: ibm.github.io/mt-rag-bench...
Arxiv: arxiv.org/abs/2501.03468
Github: github.com/IBM/mt-rag-b... (please 🌟!)
MTRAGEval: ibm.github.io/mt-rag-bench...

MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a ...
arxiv.org
August 4, 2025 at 6:33 AM
🚀Excited to announce our MTRAGEval task at SemEval 2026!
Arxiv: arxiv.org/abs/2501.03468
Github: github.com/IBM/mt-rag-b... (please 🌟!)
MTRAGEval: ibm.github.io/mt-rag-bench...
Arxiv: arxiv.org/abs/2501.03468
Github: github.com/IBM/mt-rag-b... (please 🌟!)
MTRAGEval: ibm.github.io/mt-rag-bench...
Atakan Site, Emre Hakan Erdemir, G\"ul\c{s}en Eryi\u{g}it: ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation https://arxiv.org/abs/2508.00762 https://arxiv.org/pdf/2508.00762 https://arxiv.org/html/2508.00762
August 4, 2025 at 6:30 AM
Atakan Site, Emre Hakan Erdemir, G\"ul\c{s}en Eryi\u{g}it: ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation https://arxiv.org/abs/2508.00762 https://arxiv.org/pdf/2508.00762 https://arxiv.org/html/2508.00762
Atakan Site, Emre Hakan Erdemir, G\"ul\c{s}en Eryi\u{g}it
ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation
https://arxiv.org/abs/2508.00762
ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation
https://arxiv.org/abs/2508.00762
August 4, 2025 at 4:31 AM
Atakan Site, Emre Hakan Erdemir, G\"ul\c{s}en Eryi\u{g}it
ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation
https://arxiv.org/abs/2508.00762
ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation
https://arxiv.org/abs/2508.00762

🔍 Sample data is already available!
We invite researchers, teams, and solo experimenters to benchmark systems and explore how machines understand stories.
All the details are on our site:
🌐 narrative-similarity-task.github.io
#SemEval #NLP #NarrativeAI #DH #CLS
We invite researchers, teams, and solo experimenters to benchmark systems and explore how machines understand stories.
All the details are on our site:
🌐 narrative-similarity-task.github.io
#SemEval #NLP #NarrativeAI #DH #CLS
Narrative Similarity Task - Narrative Similarity Task
SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
narrative-similarity-task.github.io
August 1, 2025 at 3:18 PM
🔍 Sample data is already available!
We invite researchers, teams, and solo experimenters to benchmark systems and explore how machines understand stories.
All the details are on our site:
🌐 narrative-similarity-task.github.io
#SemEval #NLP #NarrativeAI #DH #CLS
We invite researchers, teams, and solo experimenters to benchmark systems and explore how machines understand stories.
All the details are on our site:
🌐 narrative-similarity-task.github.io
#SemEval #NLP #NarrativeAI #DH #CLS
🎉 We’re excited to kick things off! We’re launching SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning. This is a joint effort by @hanshatzel.bsky.social (University of Hamburg) and the fortext lab, as part of the PLANS project, in collaboration with Toloka AI.

August 1, 2025 at 3:15 PM
🎉 We’re excited to kick things off! We’re launching SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning. This is a joint effort by @hanshatzel.bsky.social (University of Hamburg) and the fortext lab, as part of the PLANS project, in collaboration with Toloka AI.

🚨 Shared Task Alert! 🚨
We are announcing the shared task on narrative similarity: SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
We invite you to benchmark LLMs, embedding models, or even test your favorite narrative formalism. Sample data is now available!
We are announcing the shared task on narrative similarity: SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
We invite you to benchmark LLMs, embedding models, or even test your favorite narrative formalism. Sample data is now available!
Narrative Similarity Task - Narrative Similarity Task
SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
narrative-similarity-task.github.io
August 1, 2025 at 1:42 PM
🚨 Shared Task Alert! 🚨
We are announcing the shared task on narrative similarity: SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
We invite you to benchmark LLMs, embedding models, or even test your favorite narrative formalism. Sample data is now available!
We are announcing the shared task on narrative similarity: SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
We invite you to benchmark LLMs, embedding models, or even test your favorite narrative formalism. Sample data is now available!