
by Jason Lee

Reposted by Jason Lee

@jasondeanlee.bsky.social!
We prove a neural scaling law in the SGD learning of extensive width two-layer neural networks.
arxiv.org/abs/2504.19983
🧵below (1/10)

by Wolfgang Crämer — Reposted by Jason Lee, Robert West, Helen Tager‐Flusberg , and 17 more Jason Lee, Robert West, Helen Tager‐Flusberg, Catherine Kyobutungi, James P. Collins, Ankur R. Desai, Christoph Scherber, Julian L. Simon, Sarah Mitchell, Kai Sassenberg, Dirk Messner, Thomas Hanitzsch, Melissa L. Finucane, Rachel M. Gisselquist, Sandra González‐Bailón, Sandrine Sorlin, Serge Jaumain, Vanessa Manceron, Emanuela Galasso, David Lefebvre

Keep an eye on this space for updates, event information, and ways to get involved. We can't wait to see everyone #standupforscience2025 on March 7th, both in DC and locations nationwide!
#scienceforall #sciencenotsilence


Reposted by Jason Lee

-Physicist Fritz Houtermans
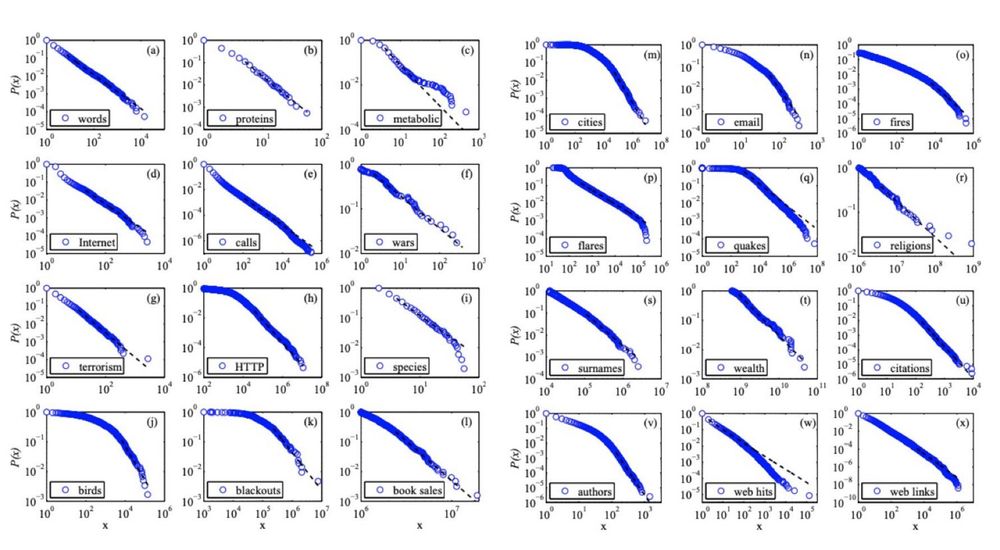
There's a lot of truth to this. log-log plots are often abused and can be very misleading
1/5
by Jason Lee
Settling the sampling complexity of RL: arxiv.org/abs/2307.13586
Optimal Muti-Distribution Learning (solved a COLT 2023 open problem): arxiv.org/abs/2312.05134
Anytime Acceleration of Gradient Descent (solved a COLT 2024 open problem): arxiv.org/abs/2411.17668

by Jason Lee
by Jason Lee
by Jason Lee
by Jason Lee
by Jason Lee
Reposted by Jason Lee

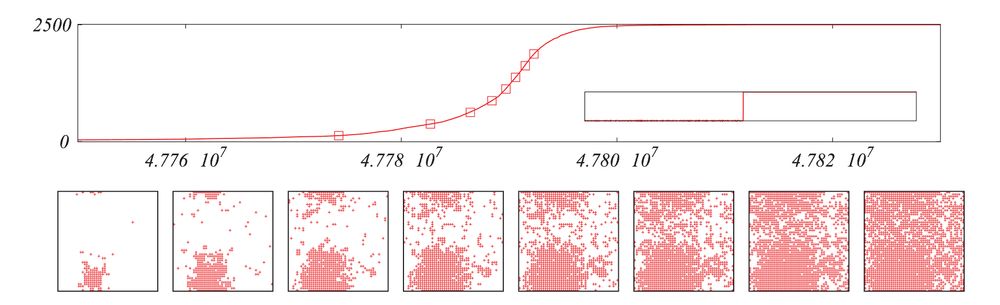
A node using B receives a benefit with respect to X, but there is a benefit to using the same tech as the majority of your neighbors.
Assume everyone uses X at time t=0. Will they switch to B?
Reposted by Jason Lee


by Jason Lee
by Jason Lee