

Edward H. Kennedy
@edwardhkennedy.bsky.social
2.5K followers
260 following
64 posts
assoc prof of statistics & data science at Carnegie Mellon
https://www.ehkennedy.com/
interested in causality, machine learning, nonparametrics, public policy, etc
Posts
Media
Videos
Starter Packs
Pinned






Reposted by Edward H. Kennedy






Reposted by Edward H. Kennedy


Reposted by Edward H. Kennedy

Peter Hull
@instrumenthull.bsky.social
· Dec 27




Reposted by Edward H. Kennedy

Iván Díaz
@idiaz.bsky.social
· Dec 13

Alec McClean
@alecmcclean.bsky.social
· Dec 13

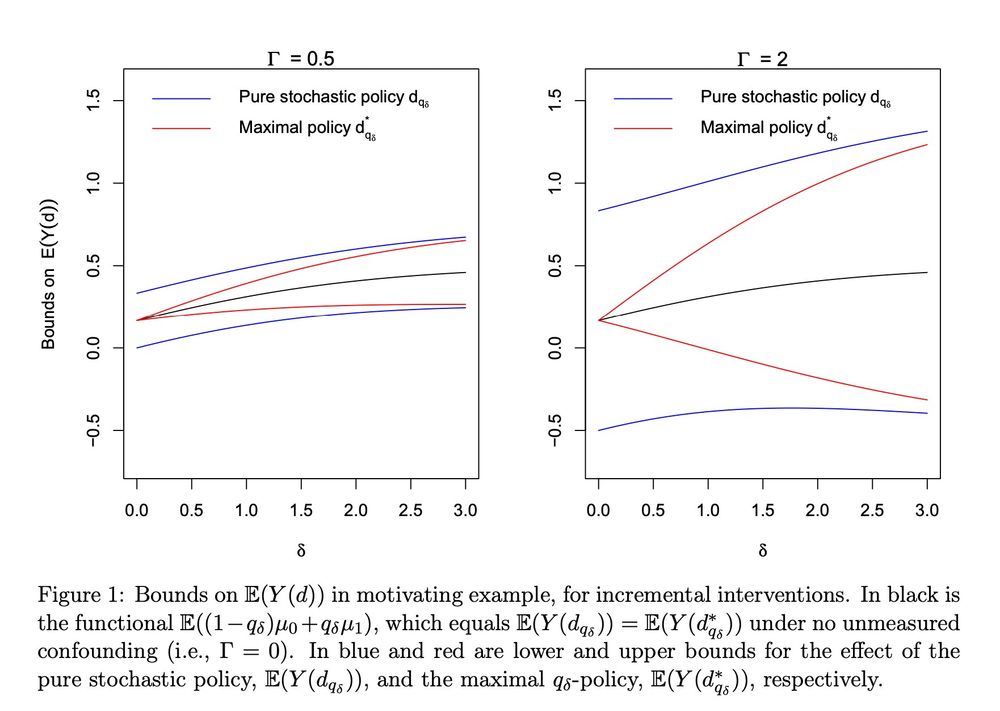
Fair comparisons of causal parameters with many treatments and positivity violations
Comparing outcomes across treatments is essential in medicine and public policy. To do so, researchers typically estimate a set of parameters, possibly counterfactual, with each targeting a different ...
arxiv.org
Reposted by Edward H. Kennedy
Alec McClean
@alecmcclean.bsky.social
· Dec 13
Fair comparisons of causal parameters with many treatments and positivity violations
Comparing outcomes across treatments is essential in medicine and public policy. To do so, researchers typically estimate a set of parameters, possibly counterfactual, with each targeting a different ...
arxiv.org
Reposted by Edward H. Kennedy



Reposted by Edward H. Kennedy
Alec McClean
@alecmcclean.bsky.social
· Dec 13





Reposted by Edward H. Kennedy
