



Amanda Bertsch
@abertsch.bsky.social
Reposted by Amanda Bertsch

LLMs don't accumulate information over the course of a text the way you'd hope!
I think this is why LLMs often feel 'fixated on the wrong thing' or 'overly literal'—they are usually responding using the most relevant single thing they remember, not the aggregate of what was said
I think this is why LLMs often feel 'fixated on the wrong thing' or 'overly literal'—they are usually responding using the most relevant single thing they remember, not the aggregate of what was said
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!

November 9, 2025 at 8:06 PM
LLMs don't accumulate information over the course of a text the way you'd hope!
I think this is why LLMs often feel 'fixated on the wrong thing' or 'overly literal'—they are usually responding using the most relevant single thing they remember, not the aggregate of what was said
I think this is why LLMs often feel 'fixated on the wrong thing' or 'overly literal'—they are usually responding using the most relevant single thing they remember, not the aggregate of what was said
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
November 7, 2025 at 5:07 PM
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
Reposted by Amanda Bertsch

why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇

November 5, 2025 at 11:11 PM
why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
Reposted by Amanda Bertsch

DeltaNet Explained by Sonlin Yang
A gentle and comprehensive introduction to the DeltaNet
Part 1: sustcsonglin.github.io/blog/2024/de...
Part 2: sustcsonglin.github.io/blog/2024/de...
Part 3: sustcsonglin.github.io/blog/2024/de...
A gentle and comprehensive introduction to the DeltaNet
Part 1: sustcsonglin.github.io/blog/2024/de...
Part 2: sustcsonglin.github.io/blog/2024/de...
Part 3: sustcsonglin.github.io/blog/2024/de...

November 5, 2025 at 11:45 PM
DeltaNet Explained by Sonlin Yang
A gentle and comprehensive introduction to the DeltaNet
Part 1: sustcsonglin.github.io/blog/2024/de...
Part 2: sustcsonglin.github.io/blog/2024/de...
Part 3: sustcsonglin.github.io/blog/2024/de...
A gentle and comprehensive introduction to the DeltaNet
Part 1: sustcsonglin.github.io/blog/2024/de...
Part 2: sustcsonglin.github.io/blog/2024/de...
Part 3: sustcsonglin.github.io/blog/2024/de...
Reposted by Amanda Bertsch

I’ll be presenting this work in **2 hours** at EMNLP’s Gather Session 3. Come by to chat about fanfiction, literary notions of similarity, long-context modeling, and consent-focused data collection!
Digital humanities researchers often care about fine-grained similarity based on narrative elements like plot or tone, which don’t necessarily correlate with surface-level textual features.
Can embedding models capture this? We study this in the context of fanfiction!
Can embedding models capture this? We study this in the context of fanfiction!

November 5, 2025 at 10:01 PM
I’ll be presenting this work in **2 hours** at EMNLP’s Gather Session 3. Come by to chat about fanfiction, literary notions of similarity, long-context modeling, and consent-focused data collection!
Reposted by Amanda Bertsch
Digital humanities researchers often care about fine-grained similarity based on narrative elements like plot or tone, which don’t necessarily correlate with surface-level textual features.
Can embedding models capture this? We study this in the context of fanfiction!
Can embedding models capture this? We study this in the context of fanfiction!
November 5, 2025 at 9:59 PM
Digital humanities researchers often care about fine-grained similarity based on narrative elements like plot or tone, which don’t necessarily correlate with surface-level textual features.
Can embedding models capture this? We study this in the context of fanfiction!
Can embedding models capture this? We study this in the context of fanfiction!
. @gneubig.bsky.social and I are co-teaching a new class on LM inference this fall!
We designed this class to give a broad view on the space, from more classical decoding algorithms to recent methods for LLMs, plus a wide range of efficiency-focused work.
website: phontron.com/class/lminfe...
We designed this class to give a broad view on the space, from more classical decoding algorithms to recent methods for LLMs, plus a wide range of efficiency-focused work.
website: phontron.com/class/lminfe...
11-664/763 LM Inference
A class at Carnegie Mellon University on language model inference algorithms.
phontron.com
September 12, 2025 at 5:14 PM
. @gneubig.bsky.social and I are co-teaching a new class on LM inference this fall!
We designed this class to give a broad view on the space, from more classical decoding algorithms to recent methods for LLMs, plus a wide range of efficiency-focused work.
website: phontron.com/class/lminfe...
We designed this class to give a broad view on the space, from more classical decoding algorithms to recent methods for LLMs, plus a wide range of efficiency-focused work.
website: phontron.com/class/lminfe...
Reposted by Amanda Bertsch

When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
🧵1/9
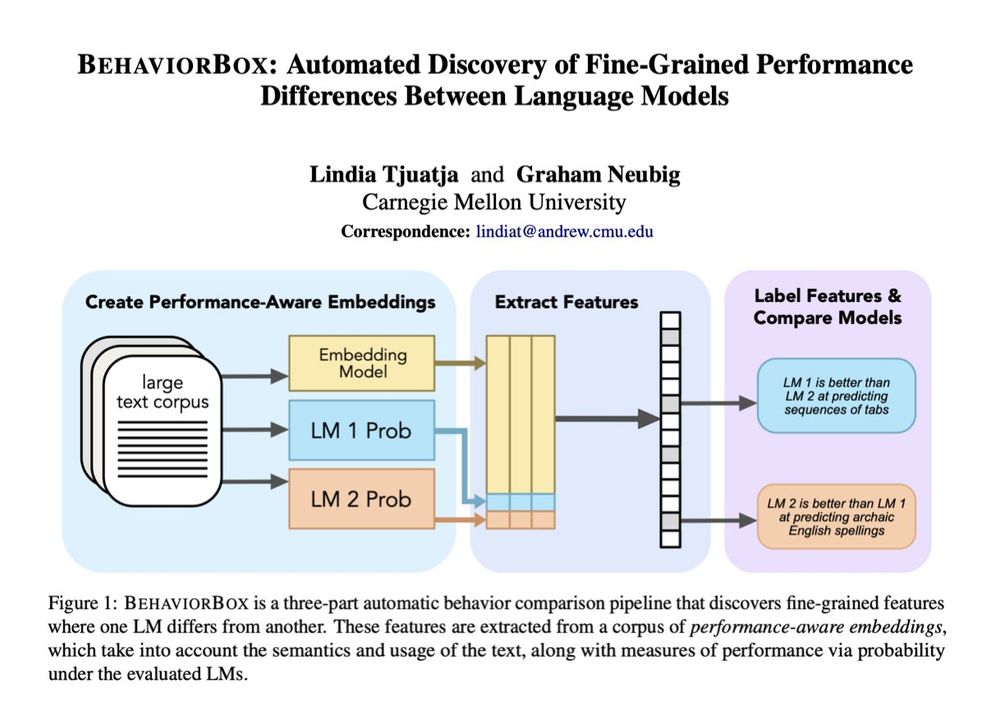
June 9, 2025 at 1:47 PM
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
🧵1/9
super excited to see folks at #NAACL25 this week! I'll be presenting our work on long-context ICL Wednesday in the 2pm poster session in Hall 3-- would love to chat with folks there or at the rest of the conference about long context data, ICL, inference time methods, New Mexican food, etc :)
April 30, 2025 at 12:03 AM
super excited to see folks at #NAACL25 this week! I'll be presenting our work on long-context ICL Wednesday in the 2pm poster session in Hall 3-- would love to chat with folks there or at the rest of the conference about long context data, ICL, inference time methods, New Mexican food, etc :)
Reposted by Amanda Bertsch

How can we better think and talk about human-like qualities attributed to language technologies like LLMs? In our #CHI2025 paper, we taxonomize how text outputs from cases of user interactions with language technologies can contribute to anthropomorphism. arxiv.org/abs/2502.09870 1/n

March 6, 2025 at 3:43 AM
How can we better think and talk about human-like qualities attributed to language technologies like LLMs? In our #CHI2025 paper, we taxonomize how text outputs from cases of user interactions with language technologies can contribute to anthropomorphism. arxiv.org/abs/2502.09870 1/n
Reposted by Amanda Bertsch

9.6 million seconds = 1 PhD 🔥
Finally analyzed my PhD time tracking data so you can plan your own research journey more effectively: mxij.me/x/phd-learning-dynamics
For current students: I hope this helps put your journey into perspective. Wishing you all the best!
Finally analyzed my PhD time tracking data so you can plan your own research journey more effectively: mxij.me/x/phd-learning-dynamics
For current students: I hope this helps put your journey into perspective. Wishing you all the best!

The Learning Dynamics of a PhD
This is what a PhD looks like: 9.6 million seconds of research.
mxij.me
December 23, 2024 at 10:08 PM
9.6 million seconds = 1 PhD 🔥
Finally analyzed my PhD time tracking data so you can plan your own research journey more effectively: mxij.me/x/phd-learning-dynamics
For current students: I hope this helps put your journey into perspective. Wishing you all the best!
Finally analyzed my PhD time tracking data so you can plan your own research journey more effectively: mxij.me/x/phd-learning-dynamics
For current students: I hope this helps put your journey into perspective. Wishing you all the best!
Reposted by Amanda Bertsch

When I started on ARL project that funds my PhD, the thing we were supposed to build was a "MaterialsGPT".
What is a MaterialsGPT? Where does that idea come from? I got to spend a lot of time thinking about that second question with @davidthewid.bsky.social and Lucy Suchman (!) working on this:
What is a MaterialsGPT? Where does that idea come from? I got to spend a lot of time thinking about that second question with @davidthewid.bsky.social and Lucy Suchman (!) working on this:

December 17, 2024 at 2:33 PM
When I started on ARL project that funds my PhD, the thing we were supposed to build was a "MaterialsGPT".
What is a MaterialsGPT? Where does that idea come from? I got to spend a lot of time thinking about that second question with @davidthewid.bsky.social and Lucy Suchman (!) working on this:
What is a MaterialsGPT? Where does that idea come from? I got to spend a lot of time thinking about that second question with @davidthewid.bsky.social and Lucy Suchman (!) working on this:
Reposted by Amanda Bertsch

📢 NEW Paper!
@siree.sh, Lucy Suchman, and I examine a corpus of 7,000 US Military grant solicitations to ask what the world’s largest military wants with to do with AI, by looking at what it seeks to fund. #STS
📄: arxiv.org/pdf/2411.17840
We find…
@siree.sh, Lucy Suchman, and I examine a corpus of 7,000 US Military grant solicitations to ask what the world’s largest military wants with to do with AI, by looking at what it seeks to fund. #STS
📄: arxiv.org/pdf/2411.17840
We find…

December 9, 2024 at 2:18 PM
📢 NEW Paper!
@siree.sh, Lucy Suchman, and I examine a corpus of 7,000 US Military grant solicitations to ask what the world’s largest military wants with to do with AI, by looking at what it seeks to fund. #STS
📄: arxiv.org/pdf/2411.17840
We find…
@siree.sh, Lucy Suchman, and I examine a corpus of 7,000 US Military grant solicitations to ask what the world’s largest military wants with to do with AI, by looking at what it seeks to fund. #STS
📄: arxiv.org/pdf/2411.17840
We find…
Reposted by Amanda Bertsch

when you try to convert your text into smaller pieces but all it gives you is Elvish, that’s a tolkienizer
November 20, 2024 at 5:51 PM
when you try to convert your text into smaller pieces but all it gives you is Elvish, that’s a tolkienizer
Reposted by Amanda Bertsch

That’s right. You might think that all successful CS academics are good at running. But that’s only because the ones who weren’t, have been eaten by bears.

A disproportionate number of sucessful CS academics have some intense cardio hobby. Took me some years to understand.

Every time I see someone post this image it goes viral
November 21, 2024 at 12:45 AM
That’s right. You might think that all successful CS academics are good at running. But that’s only because the ones who weren’t, have been eaten by bears.
Reposted by Amanda Bertsch
💬 Have you or a loved one compared LM probabilities to human linguistic acceptability judgments? You may be overcompensating for the effect of frequency and length!
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:

November 20, 2024 at 6:08 PM
💬 Have you or a loved one compared LM probabilities to human linguistic acceptability judgments? You may be overcompensating for the effect of frequency and length!
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:
Reposted by Amanda Bertsch
I'm keeping track of people at the CMU Language Technologies Institute here: go.bsky.app/NhTwCVb. Follow along!
November 12, 2024 at 2:54 PM
I'm keeping track of people at the CMU Language Technologies Institute here: go.bsky.app/NhTwCVb. Follow along!
Reposted by Amanda Bertsch

Today is the day!! Find me at 2 PM in the Jasmine Hall (the one on the floor near food).
I will be at #EMNLP2024 presenting our work on "Extrinsic Evaluation of Cultural Competence in Large Language Models" in Poster Session 12 on Thursday 2-3:30 PM.
In this work we take the first steps towards asking whether LLMs can cater to diverse cultures in *user-facing generative* tasks.
[1/7]
In this work we take the first steps towards asking whether LLMs can cater to diverse cultures in *user-facing generative* tasks.
[1/7]

November 14, 2024 at 12:19 PM
Today is the day!! Find me at 2 PM in the Jasmine Hall (the one on the floor near food).
Reposted by Amanda Bertsch
(Hehe first bsky post!) I'll be at #EMNLP2024 💃🌴! Happy to chat about (among other things):
✨linguistically+cognitively motivated evaluation
✨NLP for low-resource+endangered languages
✨figuring out what features of language data LMs are *actually* learning
I'll be presenting two posters 🧵:
✨linguistically+cognitively motivated evaluation
✨NLP for low-resource+endangered languages
✨figuring out what features of language data LMs are *actually* learning
I'll be presenting two posters 🧵:
November 8, 2024 at 6:39 PM
(Hehe first bsky post!) I'll be at #EMNLP2024 💃🌴! Happy to chat about (among other things):
✨linguistically+cognitively motivated evaluation
✨NLP for low-resource+endangered languages
✨figuring out what features of language data LMs are *actually* learning
I'll be presenting two posters 🧵:
✨linguistically+cognitively motivated evaluation
✨NLP for low-resource+endangered languages
✨figuring out what features of language data LMs are *actually* learning
I'll be presenting two posters 🧵:
Reposted by Amanda Bertsch

Taking a stand that we aren’t doing the #nlproc tag here. It’s #nlp. We used #nlproc because a decade ago the #nlp tag was full of sleazy scammers selling guides for hypnotizing women into sleeping with you.
But guess what? We won. All the sleazy scammers are doing natural language processing now.
But guess what? We won. All the sleazy scammers are doing natural language processing now.
November 8, 2024 at 3:10 AM
Reposted by Amanda Bertsch

Building/customizing your own LLM? You'll want to curate training data for it, but how do you know what makes the data good?
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵

November 5, 2024 at 10:37 PM
Building/customizing your own LLM? You'll want to curate training data for it, but how do you know what makes the data good?
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
Reposted by Amanda Bertsch
bsky.app/profile/sire... it was so interesting to see participants' perceptions of "paradigm shifts" paralleled across eras and cycles of NLP, and at the same time nothing until recent years had reached quite the level of *47%* of ACL papers in 2021 citing BERT
We conducted long-form interviews with established NLP researchers, which reveal larger trends and forces that have been shaping the NLP research community since the 1980s.

October 12, 2023 at 3:47 PM
bsky.app/profile/sire... it was so interesting to see participants' perceptions of "paradigm shifts" paralleled across eras and cycles of NLP, and at the same time nothing until recent years had reached quite the level of *47%* of ACL papers in 2021 citing BERT
Reposted by Amanda Bertsch
We all know that “recently large language models have”, “large language models are”, and “large language models can.” But *why* LLMs? How did we get here? (where is “here”?) What forces are shaping NLP, and how recent are they, actually?
To appear at EMNLP 2023: arxiv.org/abs/2310.07715
To appear at EMNLP 2023: arxiv.org/abs/2310.07715

October 12, 2023 at 1:59 PM
We all know that “recently large language models have”, “large language models are”, and “large language models can.” But *why* LLMs? How did we get here? (where is “here”?) What forces are shaping NLP, and how recent are they, actually?
To appear at EMNLP 2023: arxiv.org/abs/2310.07715
To appear at EMNLP 2023: arxiv.org/abs/2310.07715
Reposted by Amanda Bertsch

Talking to the youths in 2023: did you know that "podcast" comes from a pun on "broadcast" plus the Apple iPod, a precursor to the iPhone that only played music
Talking to the youths in 2043: did you know that "tweet" comes from a pun on Twitter, a precursor to various shortform social media
Talking to the youths in 2043: did you know that "tweet" comes from a pun on Twitter, a precursor to various shortform social media
October 11, 2023 at 3:40 AM
Talking to the youths in 2023: did you know that "podcast" comes from a pun on "broadcast" plus the Apple iPod, a precursor to the iPhone that only played music
Talking to the youths in 2043: did you know that "tweet" comes from a pun on Twitter, a precursor to various shortform social media
Talking to the youths in 2043: did you know that "tweet" comes from a pun on Twitter, a precursor to various shortform social media