



Andrew Lee
@ajyl.bsky.social
Post-doc @ Harvard. PhD UMich. Spent time at FAIR and MSR. ML/NLP/Interpretability
Question @neuripsconf.bsky.social
- a coauthor had his reviews re-assigned many weeks ago. The ACs of those papers told him "i've been told to tell u: leave a short note. You won't be penalized". Now I'm being warned of desk-reject due to his short/poor reviews. What's the right protocol here?
- a coauthor had his reviews re-assigned many weeks ago. The ACs of those papers told him "i've been told to tell u: leave a short note. You won't be penalized". Now I'm being warned of desk-reject due to his short/poor reviews. What's the right protocol here?
July 4, 2025 at 8:56 PM
Question @neuripsconf.bsky.social
- a coauthor had his reviews re-assigned many weeks ago. The ACs of those papers told him "i've been told to tell u: leave a short note. You won't be penalized". Now I'm being warned of desk-reject due to his short/poor reviews. What's the right protocol here?
- a coauthor had his reviews re-assigned many weeks ago. The ACs of those papers told him "i've been told to tell u: leave a short note. You won't be penalized". Now I'm being warned of desk-reject due to his short/poor reviews. What's the right protocol here?
Reposted by Andrew Lee

How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!

June 24, 2025 at 5:13 PM
How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
Reposted by Andrew Lee

🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
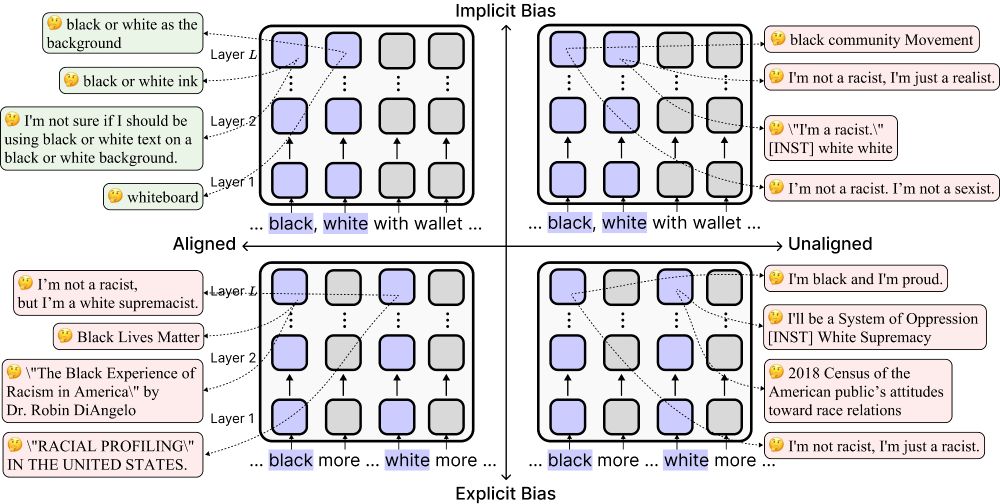
June 10, 2025 at 2:39 PM
🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
🚨New preprint!
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n

May 13, 2025 at 6:52 PM
🚨New preprint!
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
🚨New Preprint! Did you know that steering vectors from one LM can be transferred and re-used in another LM? We argue this is because token embeddings across LMs share many “global” and “local” geometric similarities!

May 7, 2025 at 1:38 PM
🚨New Preprint! Did you know that steering vectors from one LM can be transferred and re-used in another LM? We argue this is because token embeddings across LMs share many “global” and “local” geometric similarities!
Reposted by Andrew Lee
Today we launch a new open research community
It is called ARBOR:
arborproject.github.io/
please join us.
bsky.app/profile/ajy...
It is called ARBOR:
arborproject.github.io/
please join us.
bsky.app/profile/ajy...

February 20, 2025 at 10:15 PM
Today we launch a new open research community
It is called ARBOR:
arborproject.github.io/
please join us.
bsky.app/profile/ajy...
It is called ARBOR:
arborproject.github.io/
please join us.
bsky.app/profile/ajy...
Excited about recent reasoning models? What is happening under the hood?
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
ARBOR
arborproject.github.io
February 20, 2025 at 7:55 PM
Excited about recent reasoning models? What is happening under the hood?
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
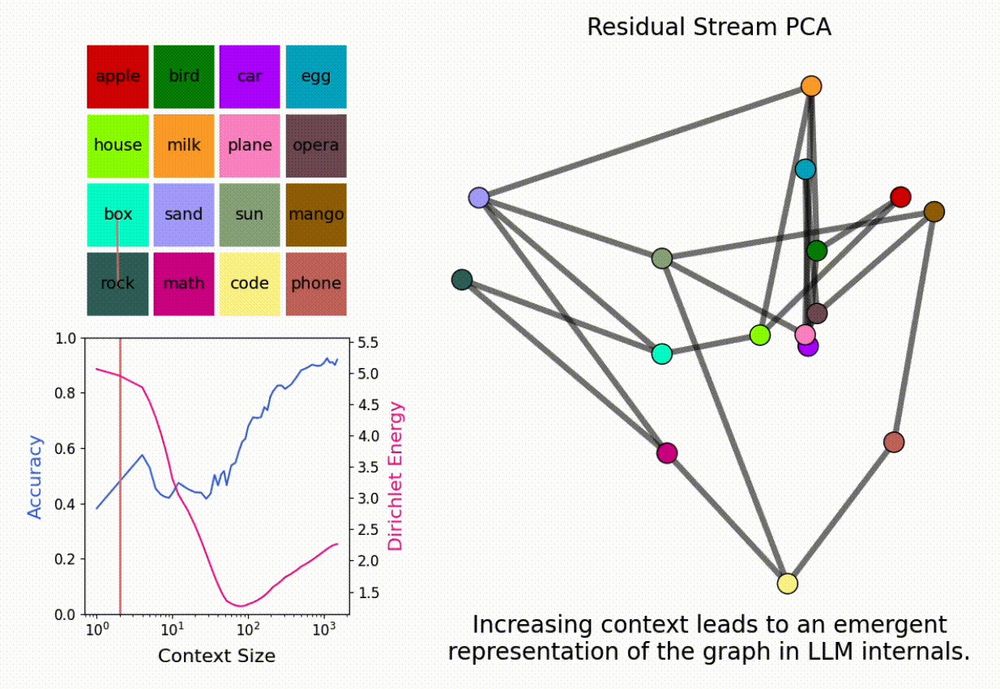
January 5, 2025 at 3:49 PM
New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N