


Alex Dimakis
@alexdimakis.bsky.social
UC Berkeley Professor working on AI. Co-Director: National AI Institute on the Foundations of Machine Learning (IFML). http://BespokeLabs.ai cofounder
Reposted by Alex Dimakis

Confirmed keynote speakers for the Greeks 🇬🇷 in #AI 2025 Symposium in Athens, Greece 🤗
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai

April 11, 2025 at 7:10 PM
Confirmed keynote speakers for the Greeks 🇬🇷 in #AI 2025 Symposium in Athens, Greece 🤗
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
Excited to be part of Greeksin.ai
Confirmed keynote speakers for the Greeks 🇬🇷 in #AI 2025 Symposium in Athens, Greece 🤗
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
April 13, 2025 at 7:30 AM
Excited to be part of Greeksin.ai
We are excited to release the OpenThinker2 reasoning models and data:
1. Outperforms DeepSeekR1-32B in reasoning.
2. Fully open source, open weights and open data (1M samples).
3. Post-trained only with SFT. RL post-training will likely further improve performance.
github.com/open-thought...
1. Outperforms DeepSeekR1-32B in reasoning.
2. Fully open source, open weights and open data (1M samples).
3. Post-trained only with SFT. RL post-training will likely further improve performance.
github.com/open-thought...

GitHub - open-thoughts/open-thoughts: Fully open data curation for reasoning models
Fully open data curation for reasoning models. Contribute to open-thoughts/open-thoughts development by creating an account on GitHub.
github.com
April 3, 2025 at 5:28 PM
We are excited to release the OpenThinker2 reasoning models and data:
1. Outperforms DeepSeekR1-32B in reasoning.
2. Fully open source, open weights and open data (1M samples).
3. Post-trained only with SFT. RL post-training will likely further improve performance.
github.com/open-thought...
1. Outperforms DeepSeekR1-32B in reasoning.
2. Fully open source, open weights and open data (1M samples).
3. Post-trained only with SFT. RL post-training will likely further improve performance.
github.com/open-thought...
We are releasing OpenThinker-32B, the best 32B reasoning model with open data. We match or outperform Deepseek-R1-32B (a closed data model) in reasoning benchmarks. Congrats to Negin and the whole Open Thoughts team.
github.com/open-thought...
github.com/open-thought...

February 12, 2025 at 8:11 PM
We are releasing OpenThinker-32B, the best 32B reasoning model with open data. We match or outperform Deepseek-R1-32B (a closed data model) in reasoning benchmarks. Congrats to Negin and the whole Open Thoughts team.
github.com/open-thought...
github.com/open-thought...
What if we had the data that DeepSeek-R1 was post-trained on?
We announce Open Thoughts, an effort to create such open reasoning datasets. Using our data we trained Open Thinker 7B an open data model with performance very close to DeepSeekR1-7B distill. (1/n)
We announce Open Thoughts, an effort to create such open reasoning datasets. Using our data we trained Open Thinker 7B an open data model with performance very close to DeepSeekR1-7B distill. (1/n)

January 28, 2025 at 6:23 PM
What if we had the data that DeepSeek-R1 was post-trained on?
We announce Open Thoughts, an effort to create such open reasoning datasets. Using our data we trained Open Thinker 7B an open data model with performance very close to DeepSeekR1-7B distill. (1/n)
We announce Open Thoughts, an effort to create such open reasoning datasets. Using our data we trained Open Thinker 7B an open data model with performance very close to DeepSeekR1-7B distill. (1/n)
We just did a crazy 48h sprint to create the best public reasoning dataset using Berkeley's Sky-T1, Curator and DeepSeek R1. We can get o1-Preview reasoning on a 32B model and 48x less data than Deepseek.
t.co/WO5UV2LZQM
t.co/WO5UV2LZQM
https://www.bespokelabs.ai/blog/bespoke-stratos-the-unreasonable-effectiveness-of-reasoning-distillation
t.co
January 22, 2025 at 6:59 PM
We just did a crazy 48h sprint to create the best public reasoning dataset using Berkeley's Sky-T1, Curator and DeepSeek R1. We can get o1-Preview reasoning on a 32B model and 48x less data than Deepseek.
t.co/WO5UV2LZQM
t.co/WO5UV2LZQM
The Berkeley Sky computing lab just trained a GPT-o1 level reasoning model, spending only $450 to create the instruction dataset. The data is 17K math and coding problems solved step by step. They created this dataset by prompting QwQ at $450 cost. Q: Impossible without distilling a bigger model?

January 14, 2025 at 6:09 PM
The Berkeley Sky computing lab just trained a GPT-o1 level reasoning model, spending only $450 to create the instruction dataset. The data is 17K math and coding problems solved step by step. They created this dataset by prompting QwQ at $450 cost. Q: Impossible without distilling a bigger model?
AI monoliths vs Unix Philosophy:
The case for small specialized AI models.
Current thinking is that AGI is coming, and one gigantic model will be able to solve everything. Current Agents are mostly prompts on one big model and prompt engineering is used for executing complex processes. (1/n)
The case for small specialized AI models.
Current thinking is that AGI is coming, and one gigantic model will be able to solve everything. Current Agents are mostly prompts on one big model and prompt engineering is used for executing complex processes. (1/n)

January 8, 2025 at 11:28 PM
AI monoliths vs Unix Philosophy:
The case for small specialized AI models.
Current thinking is that AGI is coming, and one gigantic model will be able to solve everything. Current Agents are mostly prompts on one big model and prompt engineering is used for executing complex processes. (1/n)
The case for small specialized AI models.
Current thinking is that AGI is coming, and one gigantic model will be able to solve everything. Current Agents are mostly prompts on one big model and prompt engineering is used for executing complex processes. (1/n)
Reposted by Alex Dimakis

Missed out on #Swift tickets? No worries—swing by our #SVFT poster at #NeurIPS2024 and catch *real* headliners! 🎤💃🕺
📌Where: East Exhibit Hall A-C #2207, Poster Session 4 East
⏲️When: Thu 12 Dec, 4:30 PM - 7:30 PM PST
#AI #MachineLearning #PEFT #NeurIPS24
📌Where: East Exhibit Hall A-C #2207, Poster Session 4 East
⏲️When: Thu 12 Dec, 4:30 PM - 7:30 PM PST
#AI #MachineLearning #PEFT #NeurIPS24
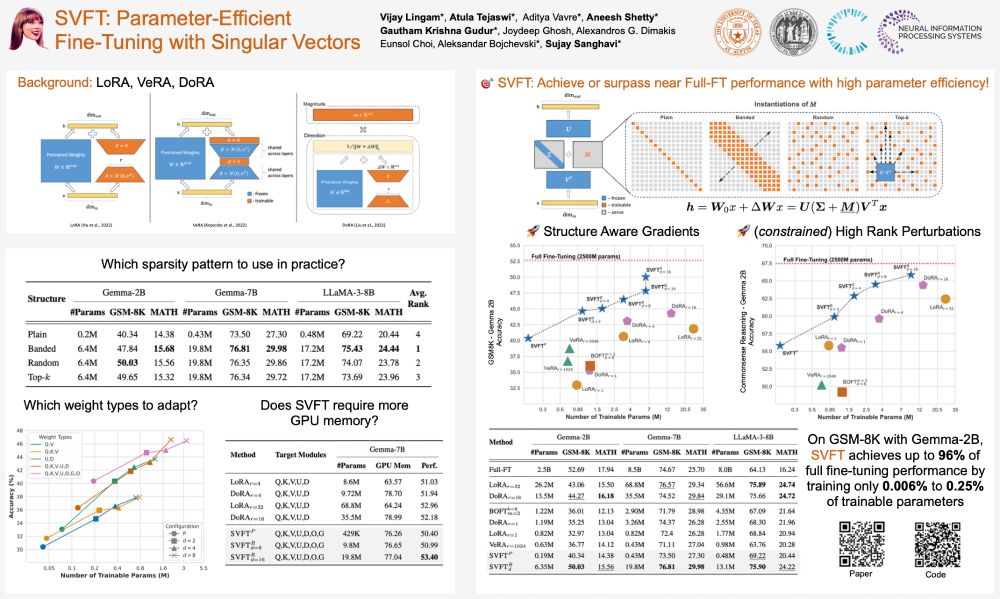
December 9, 2024 at 5:55 AM
Missed out on #Swift tickets? No worries—swing by our #SVFT poster at #NeurIPS2024 and catch *real* headliners! 🎤💃🕺
📌Where: East Exhibit Hall A-C #2207, Poster Session 4 East
⏲️When: Thu 12 Dec, 4:30 PM - 7:30 PM PST
#AI #MachineLearning #PEFT #NeurIPS24
📌Where: East Exhibit Hall A-C #2207, Poster Session 4 East
⏲️When: Thu 12 Dec, 4:30 PM - 7:30 PM PST
#AI #MachineLearning #PEFT #NeurIPS24
hello friends, I heard there is a party here?
November 19, 2024 at 10:49 PM
hello friends, I heard there is a party here?