




Ali Behrouz
@alibehrouz.bsky.social
Intern @Google, Ph.D. Student @Cornell_CS.
Interested in machine learning, LLM, brain, and healthcare.
abehrouz.github.io
Interested in machine learning, LLM, brain, and healthcare.
abehrouz.github.io
Pinned
Ali Behrouz
@alibehrouz.bsky.social
· Dec 3

🌟 Best of Both Worlds!
❓Have you ever wondered why hybrid models (RNN + Transformers) are powerful? We answer this through the lens of circuit complexity and graphs!
Excited to share our work on understanding Graph Sequence Models (GSM), which allows the use of any sequence model for graphs.
❓Have you ever wondered why hybrid models (RNN + Transformers) are powerful? We answer this through the lens of circuit complexity and graphs!
Excited to share our work on understanding Graph Sequence Models (GSM), which allows the use of any sequence model for graphs.
Reposted by Ali Behrouz

Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social

January 13, 2025 at 7:53 PM
Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social
I'll be at #NeurIPS2024 next week, and would be happy to chat about deep learning architectures, sequence modeling, reasoning, neuroscience, world models, graphs, and almost anything :)
I also will be presenting Chimera (a 2D SSM) on Wednesday (4:30 PM).
I also will be presenting Chimera (a 2D SSM) on Wednesday (4:30 PM).
December 5, 2024 at 8:43 PM
I'll be at #NeurIPS2024 next week, and would be happy to chat about deep learning architectures, sequence modeling, reasoning, neuroscience, world models, graphs, and almost anything :)
I also will be presenting Chimera (a 2D SSM) on Wednesday (4:30 PM).
I also will be presenting Chimera (a 2D SSM) on Wednesday (4:30 PM).
🌟 Best of Both Worlds!
❓Have you ever wondered why hybrid models (RNN + Transformers) are powerful? We answer this through the lens of circuit complexity and graphs!
Excited to share our work on understanding Graph Sequence Models (GSM), which allows the use of any sequence model for graphs.
❓Have you ever wondered why hybrid models (RNN + Transformers) are powerful? We answer this through the lens of circuit complexity and graphs!
Excited to share our work on understanding Graph Sequence Models (GSM), which allows the use of any sequence model for graphs.
December 3, 2024 at 9:57 PM
🌟 Best of Both Worlds!
❓Have you ever wondered why hybrid models (RNN + Transformers) are powerful? We answer this through the lens of circuit complexity and graphs!
Excited to share our work on understanding Graph Sequence Models (GSM), which allows the use of any sequence model for graphs.
❓Have you ever wondered why hybrid models (RNN + Transformers) are powerful? We answer this through the lens of circuit complexity and graphs!
Excited to share our work on understanding Graph Sequence Models (GSM), which allows the use of any sequence model for graphs.
Are univariate SSMs effective when there are 2D dependencies?
✨In our #NeurIPS paper we show how to effectively model multivariate time series by input-dependent (selective) 2-dimensional state space models with fast training using a 2D parallel scan. (1/8)
✨In our #NeurIPS paper we show how to effectively model multivariate time series by input-dependent (selective) 2-dimensional state space models with fast training using a 2D parallel scan. (1/8)
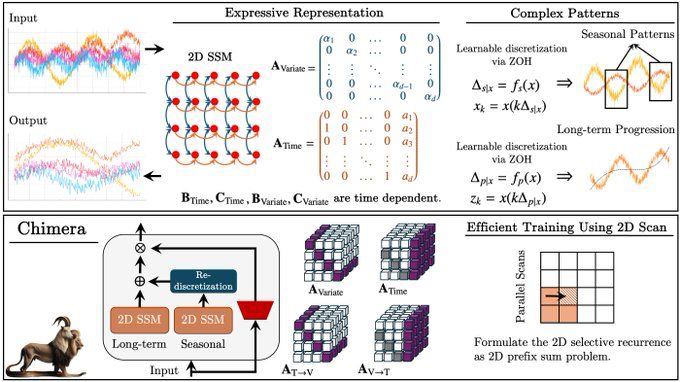
November 20, 2024 at 1:43 AM
Are univariate SSMs effective when there are 2D dependencies?
✨In our #NeurIPS paper we show how to effectively model multivariate time series by input-dependent (selective) 2-dimensional state space models with fast training using a 2D parallel scan. (1/8)
✨In our #NeurIPS paper we show how to effectively model multivariate time series by input-dependent (selective) 2-dimensional state space models with fast training using a 2D parallel scan. (1/8)