




Artem Moskalev
@artemmoskalev.bsky.social
Re-imagining drug discovery with AI 🧬. Deep Learning ⚭ Geometry. Previously PhD at the University of Amsterdam. https://amoskalev.github.io/
Pinned

ICML Spotlight 🚨 Equivariance is too slow and expensive, especially when you need global context. It makes us wonder if it even worths it? We present Geometric Hyena Networks — a simple equivariant model orders of magnitude more memory- and compute-efficient for high-dimensional data.
1/8
1/8
Job alert 🚨 Our team is looking for ML Research Scientist to join Johnson&Johnson research. We work on geometric deep learning and LLMs in drug discovery. 🧬🤓 Drop me a message if you’re interested, or share this if you know someone who’s a great fit!
Multiple locations available.
Multiple locations available.
August 14, 2025 at 4:29 PM
Job alert 🚨 Our team is looking for ML Research Scientist to join Johnson&Johnson research. We work on geometric deep learning and LLMs in drug discovery. 🧬🤓 Drop me a message if you’re interested, or share this if you know someone who’s a great fit!
Multiple locations available.
Multiple locations available.
Our code for Hierarchical RNA Language models is out! Multiple training regimes, architectures and evaluations, check it out!
Code: github.com/johnsonandjo...
Code: github.com/johnsonandjo...
August 12, 2025 at 7:18 AM
Our code for Hierarchical RNA Language models is out! Multiple training regimes, architectures and evaluations, check it out!
Code: github.com/johnsonandjo...
Code: github.com/johnsonandjo...
Interested in efficient equivariance for long-context? Visit our Geoemtric Hyena poster at ICML! ⭐️Spotlight⭐️
When: 11 a.m. — 1:30 p.m Wed July 16
Where: East Exhibition Hall A-B #E-3103
When: 11 a.m. — 1:30 p.m Wed July 16
Where: East Exhibition Hall A-B #E-3103
ICML Spotlight 🚨 Equivariance is too slow and expensive, especially when you need global context. It makes us wonder if it even worths it? We present Geometric Hyena Networks — a simple equivariant model orders of magnitude more memory- and compute-efficient for high-dimensional data.
1/8
1/8
July 14, 2025 at 9:21 AM
Interested in efficient equivariance for long-context? Visit our Geoemtric Hyena poster at ICML! ⭐️Spotlight⭐️
When: 11 a.m. — 1:30 p.m Wed July 16
Where: East Exhibition Hall A-B #E-3103
When: 11 a.m. — 1:30 p.m Wed July 16
Where: East Exhibition Hall A-B #E-3103
In SF June 23–25 🇺🇸 and Boston June 29–30 🇺🇸
Let me know if you're around! Happy to meet and chat about life and AI for bio!
Let me know if you're around! Happy to meet and chat about life and AI for bio!
June 23, 2025 at 5:09 AM
In SF June 23–25 🇺🇸 and Boston June 29–30 🇺🇸
Let me know if you're around! Happy to meet and chat about life and AI for bio!
Let me know if you're around! Happy to meet and chat about life and AI for bio!
ICML Spotlight 🚨 Equivariance is too slow and expensive, especially when you need global context. It makes us wonder if it even worths it? We present Geometric Hyena Networks — a simple equivariant model orders of magnitude more memory- and compute-efficient for high-dimensional data.
1/8
1/8
June 4, 2025 at 8:03 AM
ICML Spotlight 🚨 Equivariance is too slow and expensive, especially when you need global context. It makes us wonder if it even worths it? We present Geometric Hyena Networks — a simple equivariant model orders of magnitude more memory- and compute-efficient for high-dimensional data.
1/8
1/8
Attending ICLR 🇸🇬 Always happy to chat about LLMs and geometric deep learning for drug discovery and bio!
We are presenting two conference, and two ORALS workshop papers
- HELM:Hierarchical Encoding for mRNA Language Modeling. Thursday 10-12:30. Hall 3+Hall 2B #6. openreview.net/forum?id=MMHqnUOnl0
We are presenting two conference, and two ORALS workshop papers
- HELM:Hierarchical Encoding for mRNA Language Modeling. Thursday 10-12:30. Hall 3+Hall 2B #6. openreview.net/forum?id=MMHqnUOnl0
April 21, 2025 at 5:35 AM
Attending ICLR 🇸🇬 Always happy to chat about LLMs and geometric deep learning for drug discovery and bio!
We are presenting two conference, and two ORALS workshop papers
- HELM:Hierarchical Encoding for mRNA Language Modeling. Thursday 10-12:30. Hall 3+Hall 2B #6. openreview.net/forum?id=MMHqnUOnl0
We are presenting two conference, and two ORALS workshop papers
- HELM:Hierarchical Encoding for mRNA Language Modeling. Thursday 10-12:30. Hall 3+Hall 2B #6. openreview.net/forum?id=MMHqnUOnl0
Reposted by Artem Moskalev

Introducing All-atom Diffusion Transformers
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇

March 10, 2025 at 4:20 PM
Introducing All-atom Diffusion Transformers
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇
Reposted by Artem Moskalev

🤹 Excited to share Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems
joint work with @wellingmax.bsky.social and @jwvdm.bsky.social
preprint: arxiv.org/abs/2502.17019
code: github.com/maxxxzdn/erwin
joint work with @wellingmax.bsky.social and @jwvdm.bsky.social
preprint: arxiv.org/abs/2502.17019
code: github.com/maxxxzdn/erwin
March 5, 2025 at 6:04 PM
🤹 Excited to share Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems
joint work with @wellingmax.bsky.social and @jwvdm.bsky.social
preprint: arxiv.org/abs/2502.17019
code: github.com/maxxxzdn/erwin
joint work with @wellingmax.bsky.social and @jwvdm.bsky.social
preprint: arxiv.org/abs/2502.17019
code: github.com/maxxxzdn/erwin
North Sea weekend 🌊


March 2, 2025 at 7:24 PM
North Sea weekend 🌊
AI/ML Internships in Drug Discovery🚨
Our team is hiring PhD research interns for summer 2025 in the US. Come work with us on cutting-edge drug discovery projects! We have 3 openings:
Our team is hiring PhD research interns for summer 2025 in the US. Come work with us on cutting-edge drug discovery projects! We have 3 openings:
February 7, 2025 at 9:51 AM
AI/ML Internships in Drug Discovery🚨
Our team is hiring PhD research interns for summer 2025 in the US. Come work with us on cutting-edge drug discovery projects! We have 3 openings:
Our team is hiring PhD research interns for summer 2025 in the US. Come work with us on cutting-edge drug discovery projects! We have 3 openings:
Accepted to ICLR 🚨 Does using more geometry always help with molecule property prediction? In practice, we deal with imperfect geometries, which introduce structural noise.
In our work arxiv.org/abs/2410.11933, we investigate when and how geometric information is useful (or not) for RNA molecules.
In our work arxiv.org/abs/2410.11933, we investigate when and how geometric information is useful (or not) for RNA molecules.

Beyond Sequence: Impact of Geometric Context for RNA Property Prediction
Accurate prediction of RNA properties, such as stability and interactions, is crucial for advancing our understanding of biological processes and developing RNA-based therapeutics. RNA structures can ...
arxiv.org
February 3, 2025 at 8:55 AM
Accepted to ICLR 🚨 Does using more geometry always help with molecule property prediction? In practice, we deal with imperfect geometries, which introduce structural noise.
In our work arxiv.org/abs/2410.11933, we investigate when and how geometric information is useful (or not) for RNA molecules.
In our work arxiv.org/abs/2410.11933, we investigate when and how geometric information is useful (or not) for RNA molecules.
Accepted to ICLR 🚨 Don't treat the language of biology as natural language! Biology speaks in hierarchical patterns that natural language models don't fully capture. Meet HELM: a method to align your bio-Language Model with the intrinsic structure of mRNA sequences.
arxiv.org/abs/2410.12459
1/5
arxiv.org/abs/2410.12459
1/5

January 23, 2025 at 11:51 AM
Accepted to ICLR 🚨 Don't treat the language of biology as natural language! Biology speaks in hierarchical patterns that natural language models don't fully capture. Meet HELM: a method to align your bio-Language Model with the intrinsic structure of mRNA sequences.
arxiv.org/abs/2410.12459
1/5
arxiv.org/abs/2410.12459
1/5
Reposted by Artem Moskalev

Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264

December 10, 2024 at 8:35 AM
Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Reposted by Artem Moskalev

Three BioML starter packs now!
Pack 1: go.bsky.app/2VWBcCd
Pack 2: go.bsky.app/Bw84Hmc
Pack 3: go.bsky.app/NAKYUok
DM if you want to be included (or nominate people who should be!)
Pack 1: go.bsky.app/2VWBcCd
Pack 2: go.bsky.app/Bw84Hmc
Pack 3: go.bsky.app/NAKYUok
DM if you want to be included (or nominate people who should be!)
December 3, 2024 at 3:27 AM
Three BioML starter packs now!
Pack 1: go.bsky.app/2VWBcCd
Pack 2: go.bsky.app/Bw84Hmc
Pack 3: go.bsky.app/NAKYUok
DM if you want to be included (or nominate people who should be!)
Pack 1: go.bsky.app/2VWBcCd
Pack 2: go.bsky.app/Bw84Hmc
Pack 3: go.bsky.app/NAKYUok
DM if you want to be included (or nominate people who should be!)
Reposted by Artem Moskalev

Scientific machine learning starter pack
go.bsky.app/9a1GVeq
go.bsky.app/9a1GVeq
November 26, 2024 at 5:03 AM
Scientific machine learning starter pack
go.bsky.app/9a1GVeq
go.bsky.app/9a1GVeq
Finally!

⚛️ cuEquivariance ⚛️ is something I've been waiting for forever. Thank you Mario Geiger and team!
Curious to see where the "equivariance is just too slow" debate goes 👀
github.com/nvidia/cuequ...
Curious to see where the "equivariance is just too slow" debate goes 👀
github.com/nvidia/cuequ...

GitHub - NVIDIA/cuEquivariance: cuEquivariance is a math library that is a collective of low-level primitives and tensor ops to accelerate widely-used models, like DiffDock, MACE, Allegro and NEQUIP, ...
cuEquivariance is a math library that is a collective of low-level primitives and tensor ops to accelerate widely-used models, like DiffDock, MACE, Allegro and NEQUIP, based on equivariant neural n...
github.com
November 21, 2024 at 10:06 PM
Finally!
Reposted by Artem Moskalev

A starter pack for researchers interested in Geometric Deep Learning - in the broadest sense possible!
Let me know if you would like to be listed. :)
Thanks @sharvaree.bsky.social for the idea!
go.bsky.app/7h8sek
Let me know if you would like to be listed. :)
Thanks @sharvaree.bsky.social for the idea!
go.bsky.app/7h8sek
November 20, 2024 at 3:35 PM
A starter pack for researchers interested in Geometric Deep Learning - in the broadest sense possible!
Let me know if you would like to be listed. :)
Thanks @sharvaree.bsky.social for the idea!
go.bsky.app/7h8sek
Let me know if you would like to be listed. :)
Thanks @sharvaree.bsky.social for the idea!
go.bsky.app/7h8sek
Reposted by Artem Moskalev

My Simons talk on all the next-token & multi-token prediction stuff I've been yapping about is up, if anyone wants to watch!
There're better versions of the talk that Gregor co-presented with me elsewhere, but sadly not recorded. He is an amazing presenter!
www.youtube.com/watch?v=9V0b...
There're better versions of the talk that Gregor co-presented with me elsewhere, but sadly not recorded. He is an amazing presenter!
www.youtube.com/watch?v=9V0b...

The Pitfalls of Next-token Prediction
YouTube video by Simons Institute
www.youtube.com
November 20, 2024 at 6:48 PM
My Simons talk on all the next-token & multi-token prediction stuff I've been yapping about is up, if anyone wants to watch!
There're better versions of the talk that Gregor co-presented with me elsewhere, but sadly not recorded. He is an amazing presenter!
www.youtube.com/watch?v=9V0b...
There're better versions of the talk that Gregor co-presented with me elsewhere, but sadly not recorded. He is an amazing presenter!
www.youtube.com/watch?v=9V0b...
Reposted by Artem Moskalev

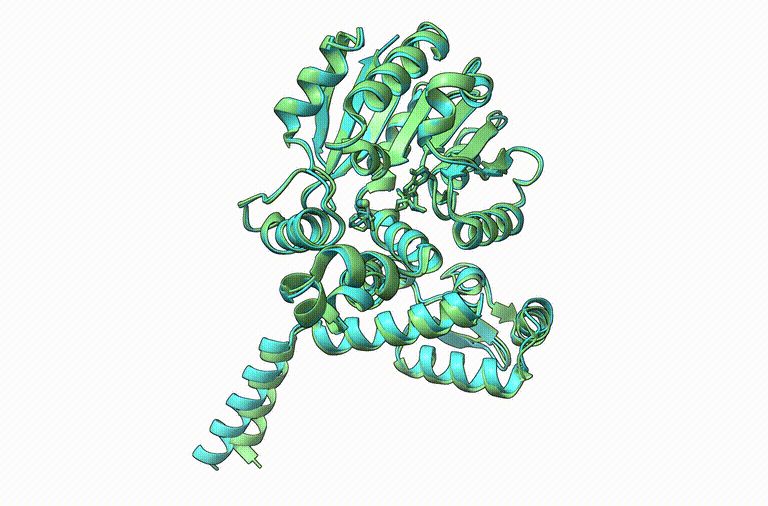
Thrilled to announce Boltz-1, the first open-source and commercially available model to achieve AlphaFold3-level accuracy on biomolecular structure prediction! An exciting collaboration with Jeremy, Saro, and an amazing team at MIT and Genesis Therapeutics. A thread!
November 17, 2024 at 4:20 PM
Thrilled to announce Boltz-1, the first open-source and commercially available model to achieve AlphaFold3-level accuracy on biomolecular structure prediction! An exciting collaboration with Jeremy, Saro, and an amazing team at MIT and Genesis Therapeutics. A thread!
Why so many reviewers tend to prefer complexity over simplicity in design?
November 19, 2024 at 9:58 PM
Why so many reviewers tend to prefer complexity over simplicity in design?
Reposted by Artem Moskalev

Yesterday, @erikjbekkers.bsky.social presented his vision on equivariance to IvI (at UvA), showcasing recent work on geometry-grounded representation learning - addressing fundamental limitations in geometric reasoning of current AI systems. 🤖
Exciting times ahead for geometric deep learning! 🌐 🤩
Exciting times ahead for geometric deep learning! 🌐 🤩


November 19, 2024 at 4:11 PM
Yesterday, @erikjbekkers.bsky.social presented his vision on equivariance to IvI (at UvA), showcasing recent work on geometry-grounded representation learning - addressing fundamental limitations in geometric reasoning of current AI systems. 🤖
Exciting times ahead for geometric deep learning! 🌐 🤩
Exciting times ahead for geometric deep learning! 🌐 🤩
What would be a good way of getting better in jax as an experienced pytorch user? 🤓
November 19, 2024 at 2:34 PM
What would be a good way of getting better in jax as an experienced pytorch user? 🤓