



Artidoro Pagnoni
@artidoro.bsky.social
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
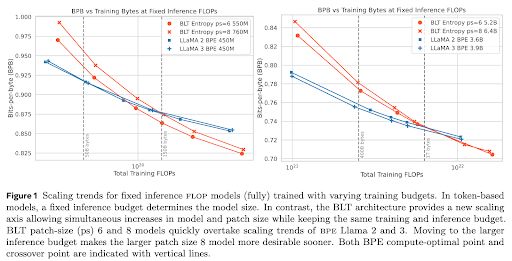
December 13, 2024 at 4:53 PM
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...