



Aditi Krishnapriyan
@ask1729.bsky.social
Assistant Professor at UC Berkeley
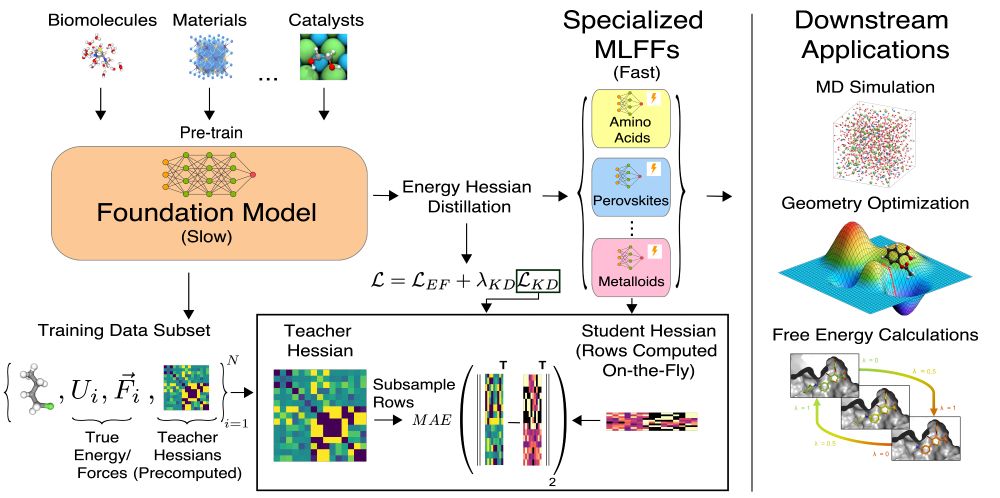
1/ Machine learning force fields are hot right now 🔥: models are getting bigger + being trained on more data. But how do we balance size, speed, and specificity? We introduce a method for doing model distillation on large-scale MLFFs into fast, specialized MLFFs! More details below:
#ICLR2025
#ICLR2025
March 13, 2025 at 3:06 PM
1/ Machine learning force fields are hot right now 🔥: models are getting bigger + being trained on more data. But how do we balance size, speed, and specificity? We introduce a method for doing model distillation on large-scale MLFFs into fast, specialized MLFFs! More details below:
#ICLR2025
#ICLR2025