




Axel 👨💻 Developer
@axelgarciak.bsky.social
👨💻 Software Engineer 💾 Software minimalist/retro
🤖 AI tinkerer 🏗️ Building tech communities
🇪🇺 UK 🇬🇧🇩🇪🇻🇪 | Check bio: axelgarciak.com/bio
🤖 AI tinkerer 🏗️ Building tech communities
🇪🇺 UK 🇬🇧🇩🇪🇻🇪 | Check bio: axelgarciak.com/bio
Qwen3-next-80B-A3B 👀
Only 3B active parameters and almost as good (in benchmarks) as Qwen3-235B-A22B and Qwen3-32B.
Only 3B active parameters and almost as good (in benchmarks) as Qwen3-235B-A22B and Qwen3-32B.


September 11, 2025 at 7:35 PM
Qwen3-next-80B-A3B 👀
Only 3B active parameters and almost as good (in benchmarks) as Qwen3-235B-A22B and Qwen3-32B.
Only 3B active parameters and almost as good (in benchmarks) as Qwen3-235B-A22B and Qwen3-32B.
Gemma 3 270M (Million not Billion) released.
I keep a close-eye to small models, and this one is a great win.
I've seen some tests and it is clever enough despite its size, but the main purpose is to fine-tune it to do specialized tasks.
I keep a close-eye to small models, and this one is a great win.
I've seen some tests and it is clever enough despite its size, but the main purpose is to fine-tune it to do specialized tasks.

August 16, 2025 at 12:57 AM
Gemma 3 270M (Million not Billion) released.
I keep a close-eye to small models, and this one is a great win.
I've seen some tests and it is clever enough despite its size, but the main purpose is to fine-tune it to do specialized tasks.
I keep a close-eye to small models, and this one is a great win.
I've seen some tests and it is clever enough despite its size, but the main purpose is to fine-tune it to do specialized tasks.
Qwen3-coder seems to be great 👀
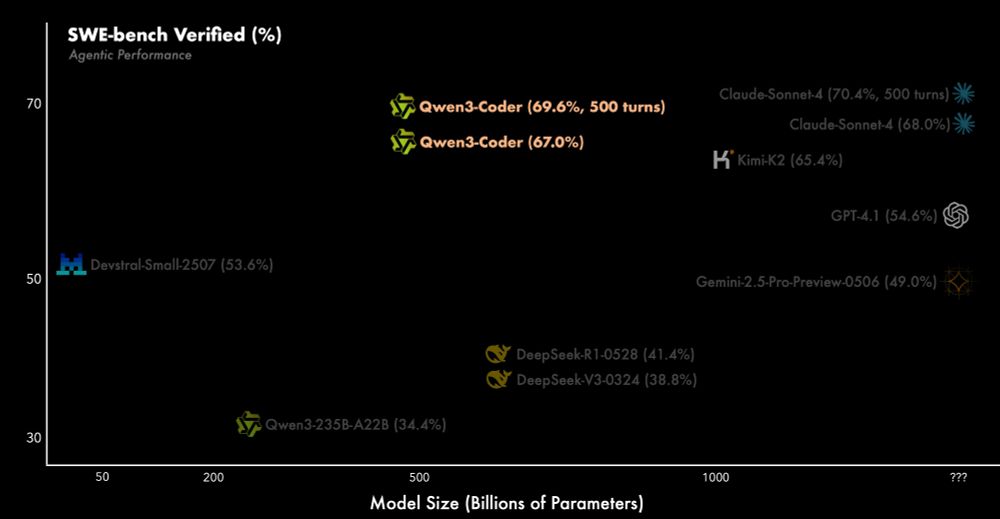
July 22, 2025 at 10:40 PM
Qwen3-coder seems to be great 👀
So many great announcements at Google I/O that is hard to put on a list.
I like Gemma 3n. They are decent lightweight models to run offline on smartphones.
They have 5B and 8B raw parameters but are comparable with the memory footprint of 2B to 4B models!
I like Gemma 3n. They are decent lightweight models to run offline on smartphones.
They have 5B and 8B raw parameters but are comparable with the memory footprint of 2B to 4B models!
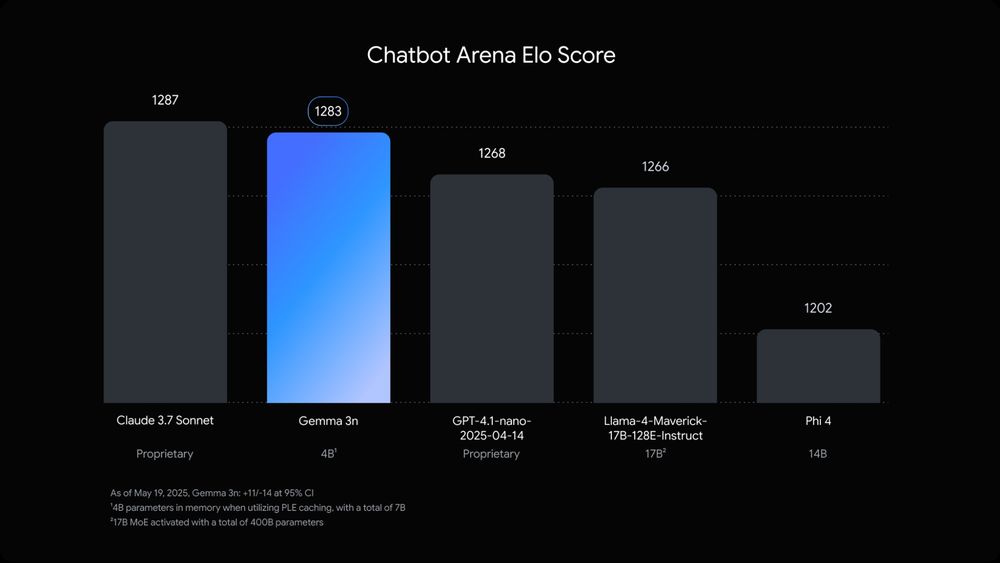
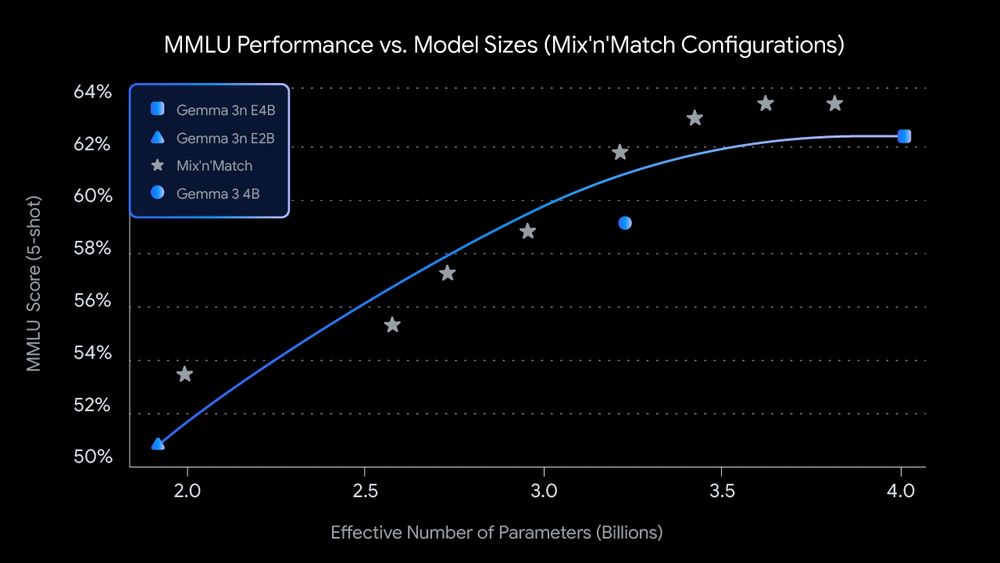
May 20, 2025 at 8:38 PM
So many great announcements at Google I/O that is hard to put on a list.
I like Gemma 3n. They are decent lightweight models to run offline on smartphones.
They have 5B and 8B raw parameters but are comparable with the memory footprint of 2B to 4B models!
I like Gemma 3n. They are decent lightweight models to run offline on smartphones.
They have 5B and 8B raw parameters but are comparable with the memory footprint of 2B to 4B models!
Companies should release their AI models/LLM as soon as possible.
That way they don't have to compare themselves to Qwen3 or DeepSeek r2 and distill versions.
The more they wait, the more embarrassing it will be when they don't compare their model to those two. 😅
That way they don't have to compare themselves to Qwen3 or DeepSeek r2 and distill versions.
The more they wait, the more embarrassing it will be when they don't compare their model to those two. 😅
May 1, 2025 at 4:19 PM
Companies should release their AI models/LLM as soon as possible.
That way they don't have to compare themselves to Qwen3 or DeepSeek r2 and distill versions.
The more they wait, the more embarrassing it will be when they don't compare their model to those two. 😅
That way they don't have to compare themselves to Qwen3 or DeepSeek r2 and distill versions.
The more they wait, the more embarrassing it will be when they don't compare their model to those two. 😅
Qwen3 is the ultimate GPU-Poor LLM!
Qwen3 4B and 8B are good for many use cases. Even Qwen3 0.6B seems coherent.
Qwen3-30B-A3 can be run with 4GB VRAM with enough system RAM.
I ran it on 4GB VRAM and got 12tok/s!
Qwen3 4B and 8B are good for many use cases. Even Qwen3 0.6B seems coherent.
Qwen3-30B-A3 can be run with 4GB VRAM with enough system RAM.
I ran it on 4GB VRAM and got 12tok/s!
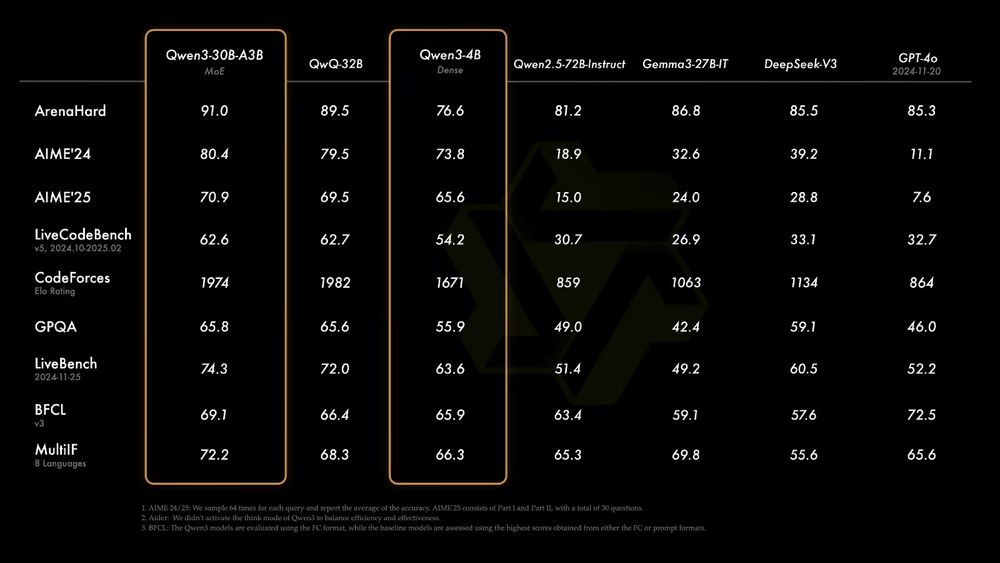
April 30, 2025 at 11:02 PM
Qwen3 is the ultimate GPU-Poor LLM!
Qwen3 4B and 8B are good for many use cases. Even Qwen3 0.6B seems coherent.
Qwen3-30B-A3 can be run with 4GB VRAM with enough system RAM.
I ran it on 4GB VRAM and got 12tok/s!
Qwen3 4B and 8B are good for many use cases. Even Qwen3 0.6B seems coherent.
Qwen3-30B-A3 can be run with 4GB VRAM with enough system RAM.
I ran it on 4GB VRAM and got 12tok/s!
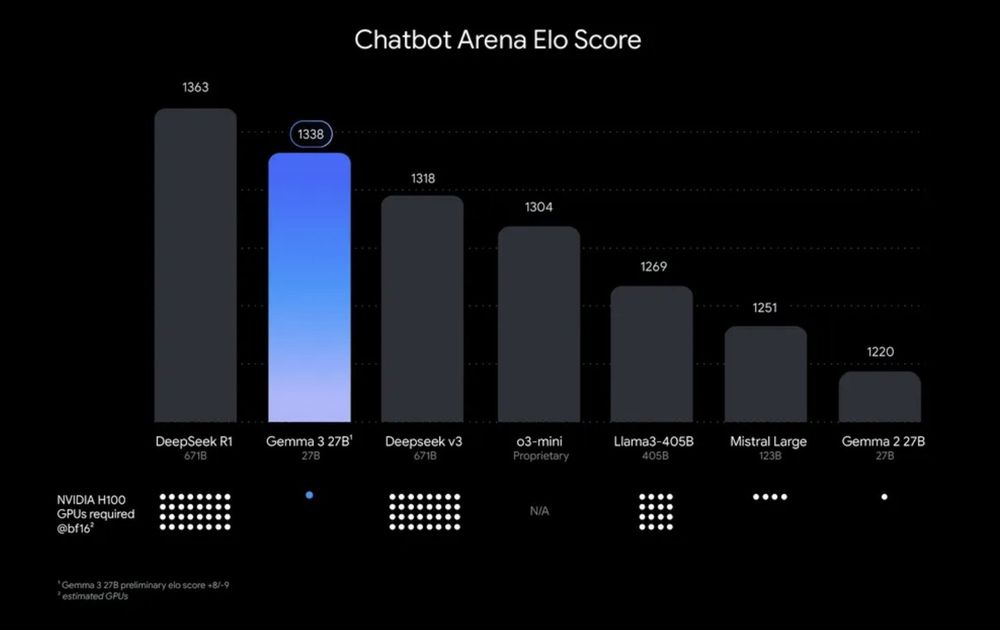
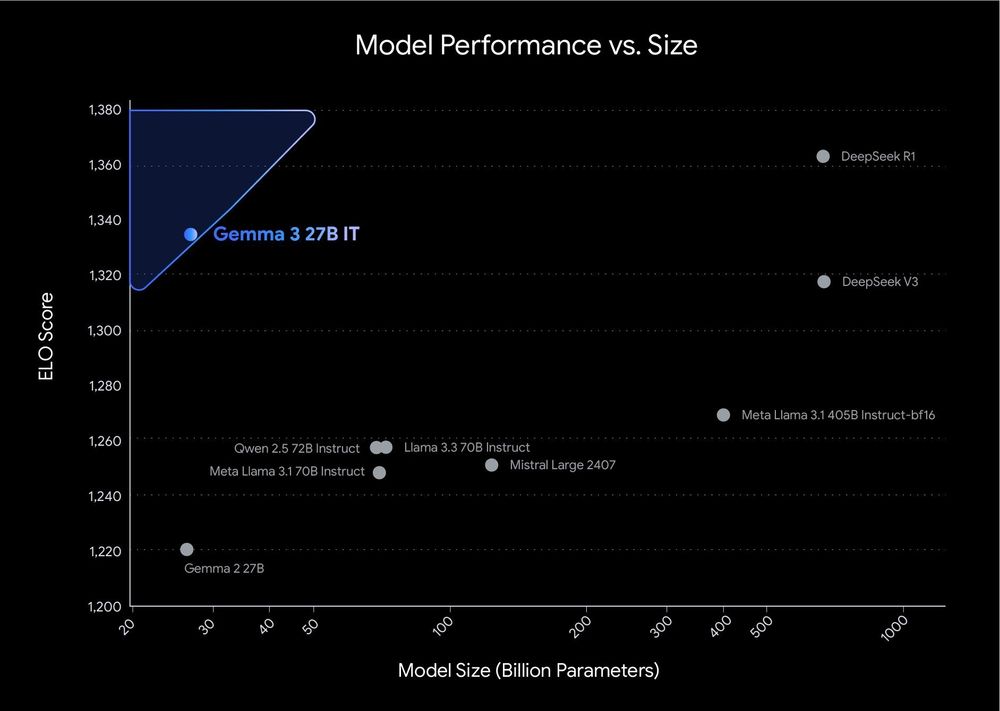
Good to see smaller LLMs pushing the pareto frontier of size vs performance.
Gemma 3 27B by Google DeepMind was released with performance between DeepSeek V3 and R1.
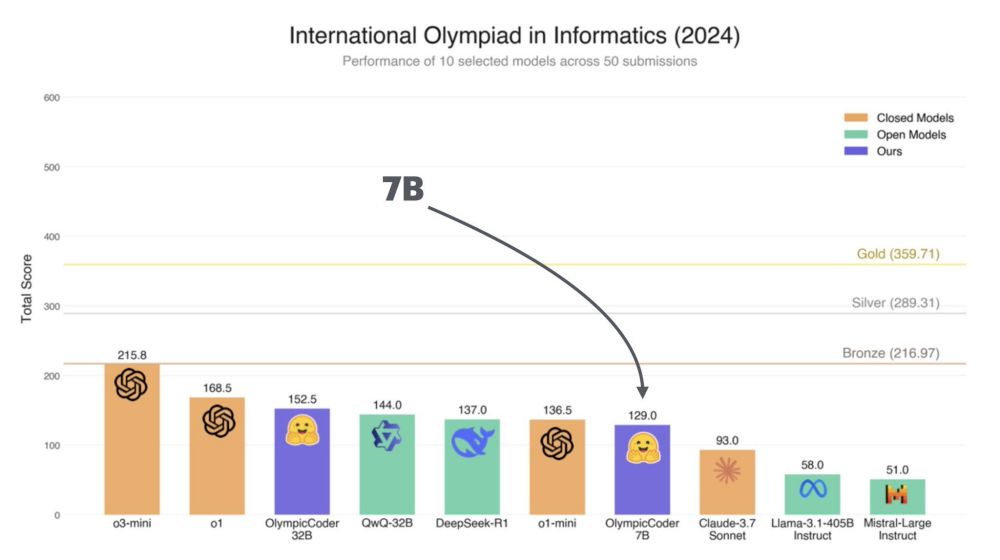
OlympicCoder 7B by Hugging Face with better performance than Claude 3.7 in Olympiad-Level Programming Problems.
Gemma 3 27B by Google DeepMind was released with performance between DeepSeek V3 and R1.
OlympicCoder 7B by Hugging Face with better performance than Claude 3.7 in Olympiad-Level Programming Problems.
March 12, 2025 at 7:49 PM
Good to see smaller LLMs pushing the pareto frontier of size vs performance.
Gemma 3 27B by Google DeepMind was released with performance between DeepSeek V3 and R1.
OlympicCoder 7B by Hugging Face with better performance than Claude 3.7 in Olympiad-Level Programming Problems.
Gemma 3 27B by Google DeepMind was released with performance between DeepSeek V3 and R1.
OlympicCoder 7B by Hugging Face with better performance than Claude 3.7 in Olympiad-Level Programming Problems.
The debate around AI is polarized: either it's taking our jobs tomorrow or it's just hype.
Anyone who's actually used AI for longer than a few minutes knows the truth is far less sensational.
Anyone who's actually used AI for longer than a few minutes knows the truth is far less sensational.
January 19, 2025 at 8:42 PM
The debate around AI is polarized: either it's taking our jobs tomorrow or it's just hype.
Anyone who's actually used AI for longer than a few minutes knows the truth is far less sensational.
Anyone who's actually used AI for longer than a few minutes knows the truth is far less sensational.
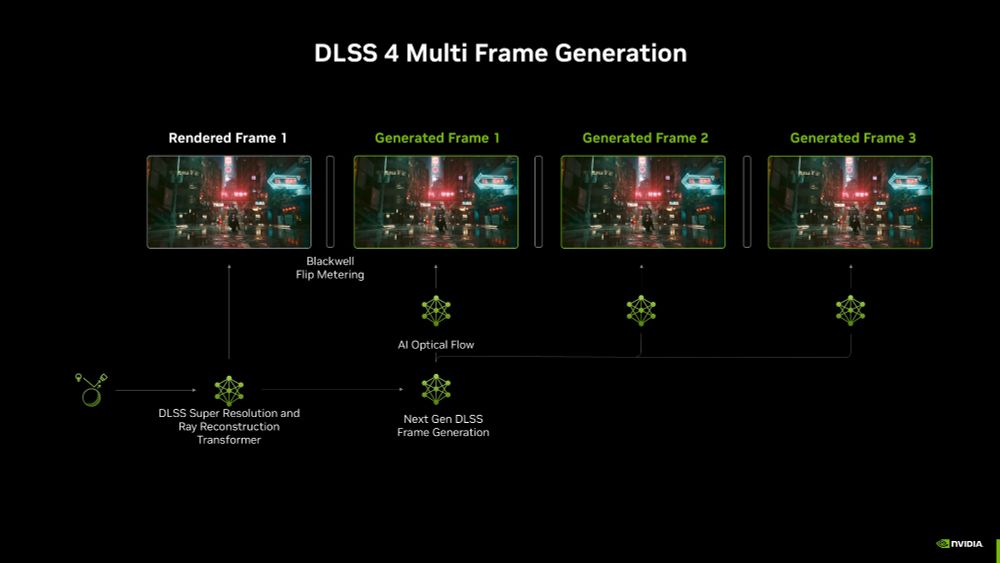
One of the coolest AI use cases I've read about recently is DLSS 4 for NVIDIA GPUs.
DLSS stands for Deep Learning Super Sampling.
Games use DLSS AI to predict multiple frames and improve image quality/upscaling.
That allows lower-spec GPUs to play at higher resolutions/FPS!
DLSS stands for Deep Learning Super Sampling.
Games use DLSS AI to predict multiple frames and improve image quality/upscaling.
That allows lower-spec GPUs to play at higher resolutions/FPS!
January 13, 2025 at 9:07 PM
One of the coolest AI use cases I've read about recently is DLSS 4 for NVIDIA GPUs.
DLSS stands for Deep Learning Super Sampling.
Games use DLSS AI to predict multiple frames and improve image quality/upscaling.
That allows lower-spec GPUs to play at higher resolutions/FPS!
DLSS stands for Deep Learning Super Sampling.
Games use DLSS AI to predict multiple frames and improve image quality/upscaling.
That allows lower-spec GPUs to play at higher resolutions/FPS!
Made-up tech news headline #1:
Tech CEO Replaces Dev Team with AI, Only to Be Ousted by Ex-Employee's AI-Powered SAAS One Month Later.
Tech CEO Replaces Dev Team with AI, Only to Be Ousted by Ex-Employee's AI-Powered SAAS One Month Later.
January 12, 2025 at 7:04 AM
Made-up tech news headline #1:
Tech CEO Replaces Dev Team with AI, Only to Be Ousted by Ex-Employee's AI-Powered SAAS One Month Later.
Tech CEO Replaces Dev Team with AI, Only to Be Ousted by Ex-Employee's AI-Powered SAAS One Month Later.
Interesting text-to-video model preserving transparency: TransPixar.
January 10, 2025 at 10:05 AM
Interesting text-to-video model preserving transparency: TransPixar.
Nvidia announced Project Digits, a personal AI supercomputer launching in May for $3K:
- Powered by GB10 Grace Blackwell Superchip.
- 128GB of unified memory.
- Can be linked to run bigger models.
It's kind of the Linux version of Mac Mini with 2x memory but 1.5x price.
- Powered by GB10 Grace Blackwell Superchip.
- 128GB of unified memory.
- Can be linked to run bigger models.
It's kind of the Linux version of Mac Mini with 2x memory but 1.5x price.

January 7, 2025 at 12:21 PM
Nvidia announced Project Digits, a personal AI supercomputer launching in May for $3K:
- Powered by GB10 Grace Blackwell Superchip.
- 128GB of unified memory.
- Can be linked to run bigger models.
It's kind of the Linux version of Mac Mini with 2x memory but 1.5x price.
- Powered by GB10 Grace Blackwell Superchip.
- 128GB of unified memory.
- Can be linked to run bigger models.
It's kind of the Linux version of Mac Mini with 2x memory but 1.5x price.
Made-up tech role #27:
Senior Overengineer.
Why use one line of code when you can use 100?
- Turns simple tasks into complex microservices.
- Believes every app needs AI, blockchain, and a custom-built framework.
- Thinks “scalability” is more important than functionality.
Senior Overengineer.
Why use one line of code when you can use 100?
- Turns simple tasks into complex microservices.
- Believes every app needs AI, blockchain, and a custom-built framework.
- Thinks “scalability” is more important than functionality.
January 4, 2025 at 5:36 PM
Made-up tech role #27:
Senior Overengineer.
Why use one line of code when you can use 100?
- Turns simple tasks into complex microservices.
- Believes every app needs AI, blockchain, and a custom-built framework.
- Thinks “scalability” is more important than functionality.
Senior Overengineer.
Why use one line of code when you can use 100?
- Turns simple tasks into complex microservices.
- Believes every app needs AI, blockchain, and a custom-built framework.
- Thinks “scalability” is more important than functionality.
Made-up tech role #26:
Agile Stand-Up Philosopher.
Turns 15-minute meetings into existential debates.
Agile Stand-Up Philosopher.
Turns 15-minute meetings into existential debates.

January 3, 2025 at 6:38 AM
Made-up tech role #26:
Agile Stand-Up Philosopher.
Turns 15-minute meetings into existential debates.
Agile Stand-Up Philosopher.
Turns 15-minute meetings into existential debates.
It seems that BlueSky is becoming my main social media platform.
I seem to find more interesting content here and it is not a coincidence as the feeds are easy to customize.
I seem to find more interesting content here and it is not a coincidence as the feeds are easy to customize.
January 2, 2025 at 11:54 AM
It seems that BlueSky is becoming my main social media platform.
I seem to find more interesting content here and it is not a coincidence as the feeds are easy to customize.
I seem to find more interesting content here and it is not a coincidence as the feeds are easy to customize.
I sometimes miss the simplicity of early web development.
No build tools, node.js, npm... just write code and see it work in the browser.
You could inspect the source and understand everything.
vue.js at least still makes it possible to write an app without a build system.
No build tools, node.js, npm... just write code and see it work in the browser.
You could inspect the source and understand everything.
vue.js at least still makes it possible to write an app without a build system.
January 1, 2025 at 10:27 PM
I sometimes miss the simplicity of early web development.
No build tools, node.js, npm... just write code and see it work in the browser.
You could inspect the source and understand everything.
vue.js at least still makes it possible to write an app without a build system.
No build tools, node.js, npm... just write code and see it work in the browser.
You could inspect the source and understand everything.
vue.js at least still makes it possible to write an app without a build system.
2025 is a perfect square:
45² = 2025
This will happen again in 2116.
It's also the sum of the cubes of all single digit numbers:
0³ + 1³ + 2³ + 3³ + 4³ + 5³ + 6³ + 7³ + 8³ + 9³ = 2025.
45² = 2025
This will happen again in 2116.
It's also the sum of the cubes of all single digit numbers:
0³ + 1³ + 2³ + 3³ + 4³ + 5³ + 6³ + 7³ + 8³ + 9³ = 2025.
January 1, 2025 at 6:30 PM
2025 is a perfect square:
45² = 2025
This will happen again in 2116.
It's also the sum of the cubes of all single digit numbers:
0³ + 1³ + 2³ + 3³ + 4³ + 5³ + 6³ + 7³ + 8³ + 9³ = 2025.
45² = 2025
This will happen again in 2116.
It's also the sum of the cubes of all single digit numbers:
0³ + 1³ + 2³ + 3³ + 4³ + 5³ + 6³ + 7³ + 8³ + 9³ = 2025.
Happy New Year 2025! 🎆🎇
January 1, 2025 at 12:26 AM
Happy New Year 2025! 🎆🎇
The Korean institute KAIST found a way to turn cancer cells into normal cells using a computer model.
It works for colon cancer, could work for others, and may reduce side effects and recurrence.
The technology has been transferred to BioRevert Inc. for practical development.
It works for colon cancer, could work for others, and may reduce side effects and recurrence.
The technology has been transferred to BioRevert Inc. for practical development.

Control of Cellular Differentiation Trajectories for Cancer Reversion
A computational framework, single-cell Boolean network inference and control (BENEIN), is presented. Applying BENEIN to human large intestinal single-cell transcriptome, MYB, HDAC2, and FOXA2 are ide...
onlinelibrary.wiley.com
December 30, 2024 at 8:33 AM
The Korean institute KAIST found a way to turn cancer cells into normal cells using a computer model.
It works for colon cancer, could work for others, and may reduce side effects and recurrence.
The technology has been transferred to BioRevert Inc. for practical development.
It works for colon cancer, could work for others, and may reduce side effects and recurrence.
The technology has been transferred to BioRevert Inc. for practical development.
SemiKong LLM: First open-source LLM for semiconductors, built on Llama3.1.
Key takeaways:
- Fine-tuned with semiconductor specific datasets.
- Collaborative and scalable for diverse use cases.
- Attempts to address the industry challenge of knowledge gaps when experts retire.
Key takeaways:
- Fine-tuned with semiconductor specific datasets.
- Collaborative and scalable for diverse use cases.
- Attempts to address the industry challenge of knowledge gaps when experts retire.

SemiKong | The World's First Open-Source LLM for Semiconductor
SemiKong outperforms general-purpose LLMs in semiconductor-specific tasks. An AI Alliance core project. Led by industry & AI specialists from Aitomatic, TEL, FPT
semikong.ai
December 29, 2024 at 5:50 PM
SemiKong LLM: First open-source LLM for semiconductors, built on Llama3.1.
Key takeaways:
- Fine-tuned with semiconductor specific datasets.
- Collaborative and scalable for diverse use cases.
- Attempts to address the industry challenge of knowledge gaps when experts retire.
Key takeaways:
- Fine-tuned with semiconductor specific datasets.
- Collaborative and scalable for diverse use cases.
- Attempts to address the industry challenge of knowledge gaps when experts retire.
Meta introduced Byte Latent Transformer (BLT), key takeaways:
- Processes raw bytes, no tokenization
- Dynamic patching reduces compute costs by 50%
- Excels in multilingual, noisy, and low-resource tasks
- Extends to image/audio applications
Hopefully we see BLT models soon!
- Processes raw bytes, no tokenization
- Dynamic patching reduces compute costs by 50%
- Excels in multilingual, noisy, and low-resource tasks
- Extends to image/audio applications
Hopefully we see BLT models soon!
December 29, 2024 at 1:16 PM
Meta introduced Byte Latent Transformer (BLT), key takeaways:
- Processes raw bytes, no tokenization
- Dynamic patching reduces compute costs by 50%
- Excels in multilingual, noisy, and low-resource tasks
- Extends to image/audio applications
Hopefully we see BLT models soon!
- Processes raw bytes, no tokenization
- Dynamic patching reduces compute costs by 50%
- Excels in multilingual, noisy, and low-resource tasks
- Extends to image/audio applications
Hopefully we see BLT models soon!
Today I learned about the GPU-poor LLM arena.
It's interesting as the models ranked there usually fit inside 4GB VRAM or less and run relatively well without GPU as well.
EXAONE from LG is on the lead. I tested the 3B model before and it did well for its size.
Here's the link:
It's interesting as the models ranked there usually fit inside 4GB VRAM or less and run relatively well without GPU as well.
EXAONE from LG is on the lead. I tested the 3B model before and it did well for its size.
Here's the link:
December 28, 2024 at 7:33 PM
Today I learned about the GPU-poor LLM arena.
It's interesting as the models ranked there usually fit inside 4GB VRAM or less and run relatively well without GPU as well.
EXAONE from LG is on the lead. I tested the 3B model before and it did well for its size.
Here's the link:
It's interesting as the models ranked there usually fit inside 4GB VRAM or less and run relatively well without GPU as well.
EXAONE from LG is on the lead. I tested the 3B model before and it did well for its size.
Here's the link:
ghostty 1.0 has been released!
It is a blazingly fast terminal emulator written by the legendary Mitchell Hashimoto in the Zig programming language.
Check it out: ghostty.org
It is a blazingly fast terminal emulator written by the legendary Mitchell Hashimoto in the Zig programming language.
Check it out: ghostty.org

Ghostty
Ghostty is a fast, feature-rich, and cross-platform terminal emulator that uses platform-native UI and GPU acceleration.
ghostty.org
December 27, 2024 at 11:17 AM
ghostty 1.0 has been released!
It is a blazingly fast terminal emulator written by the legendary Mitchell Hashimoto in the Zig programming language.
Check it out: ghostty.org
It is a blazingly fast terminal emulator written by the legendary Mitchell Hashimoto in the Zig programming language.
Check it out: ghostty.org
DeepSeek v3 LLM is out!
According to benchmarks it is as good as GPT-4o/ Claude 3.5 Sonnet, but open source.
Here's a summary:
According to benchmarks it is as good as GPT-4o/ Claude 3.5 Sonnet, but open source.
Here's a summary:

December 27, 2024 at 8:47 AM
DeepSeek v3 LLM is out!
According to benchmarks it is as good as GPT-4o/ Claude 3.5 Sonnet, but open source.
Here's a summary:
According to benchmarks it is as good as GPT-4o/ Claude 3.5 Sonnet, but open source.
Here's a summary:
Made-up tech role #25:
Scrum Claus.
🎷 Making a list, checking it twice, gonna find out who's naughty and nice.
- Runs daily stand-ups where everyone pretends they’re on track.
- Believes every sprint should end with a Christmas miracle.
Scrum Claus.
🎷 Making a list, checking it twice, gonna find out who's naughty and nice.
- Runs daily stand-ups where everyone pretends they’re on track.
- Believes every sprint should end with a Christmas miracle.

December 25, 2024 at 7:55 PM
Made-up tech role #25:
Scrum Claus.
🎷 Making a list, checking it twice, gonna find out who's naughty and nice.
- Runs daily stand-ups where everyone pretends they’re on track.
- Believes every sprint should end with a Christmas miracle.
Scrum Claus.
🎷 Making a list, checking it twice, gonna find out who's naughty and nice.
- Runs daily stand-ups where everyone pretends they’re on track.
- Believes every sprint should end with a Christmas miracle.