



David Brandfonbrener
@brandfonbrener.bsky.social
Research scientist at Meta on the llama team
Thinking about language models
Past: PhD at NYU, fellow at Harvard’s Kempner Institute
Thinking about language models
Past: PhD at NYU, fellow at Harvard’s Kempner Institute
Reposted by David Brandfonbrener

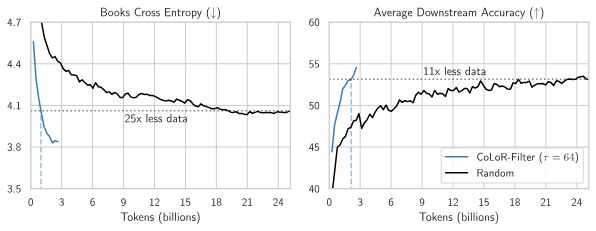
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
April 5, 2025 at 12:04 PM
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
I’m heading to NeurIPS Wednesday through Sunday. DM me if you want to meet up!
December 8, 2024 at 4:43 PM
I’m heading to NeurIPS Wednesday through Sunday. DM me if you want to meet up!
Reposted by David Brandfonbrener

NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and the John A. Paulson School of Engineering and Applied Sciences (SEAS). Read the full description & apply today: academicpositions.harvard.edu/postings/14362
#ML #AI
#ML #AI

December 3, 2024 at 1:24 AM
NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and the John A. Paulson School of Engineering and Applied Sciences (SEAS). Read the full description & apply today: academicpositions.harvard.edu/postings/14362
#ML #AI
#ML #AI
How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.

November 21, 2024 at 3:11 PM
How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.