



What makes tabular data unique (and interesting!) is not merely that it's arranged into rows and columns. New blogpost: calvinmccarter.substack.com/p/the-idiosy...

The idiosyncrasies of tabular data
The things that make tabular data different
calvinmccarter.substack.com
August 19, 2025 at 3:06 AM
What makes tabular data unique (and interesting!) is not merely that it's arranged into rows and columns. New blogpost: calvinmccarter.substack.com/p/the-idiosy...
Has anyone tried far-UVC in their home? It's now dropped into the ~$300 price range where I'm interested in trying it for myself. substack.com/home/post/p-...

Flipping the switch on far-UVC
We’ve known about far-UVC’s promise for a decade. Why isn't it everywhere?
substack.com
March 11, 2025 at 2:43 PM
Has anyone tried far-UVC in their home? It's now dropped into the ~$300 price range where I'm interested in trying it for myself. substack.com/home/post/p-...
Here's a link to the report: cleanlabelproject.org/wp-content/u... (TLDR heuristics: whey is better than plant-based, non-organic is better than organic, unflavored is better than chocolate-flavored)
January 12, 2025 at 8:15 PM
Here's a link to the report: cleanlabelproject.org/wp-content/u... (TLDR heuristics: whey is better than plant-based, non-organic is better than organic, unflavored is better than chocolate-flavored)
Ultra exciting! And it's gratifying to see that this method uses the kernel density integral preprocessing method that I published in @tmlr-pub.bsky.social (2023). (One takeaway: even if your ML research focus isn't deep learning, pursue directions that complement rather than compete with it.)

This might be the first time after 10 years that boosted trees are not the best default choice when working with data in tables.
Instead a pre-trained neural network is, the new TabPFN, as we just published in Nature 🎉
Instead a pre-trained neural network is, the new TabPFN, as we just published in Nature 🎉

January 8, 2025 at 7:03 PM
Ultra exciting! And it's gratifying to see that this method uses the kernel density integral preprocessing method that I published in @tmlr-pub.bsky.social (2023). (One takeaway: even if your ML research focus isn't deep learning, pursue directions that complement rather than compete with it.)
Reposted by Calvin McCarter

How do you go from a hit in your antibody screen to a suitable drug? Now introducing CloneBO: we optimize antibodies in the lab by teaching a generative model how we optimize them in our bodies!
w/ Nat Gruver, Yilun Kuang, Lily Li, @andrewgwils.bsky.social and the team at Big Hat! 1/7
w/ Nat Gruver, Yilun Kuang, Lily Li, @andrewgwils.bsky.social and the team at Big Hat! 1/7
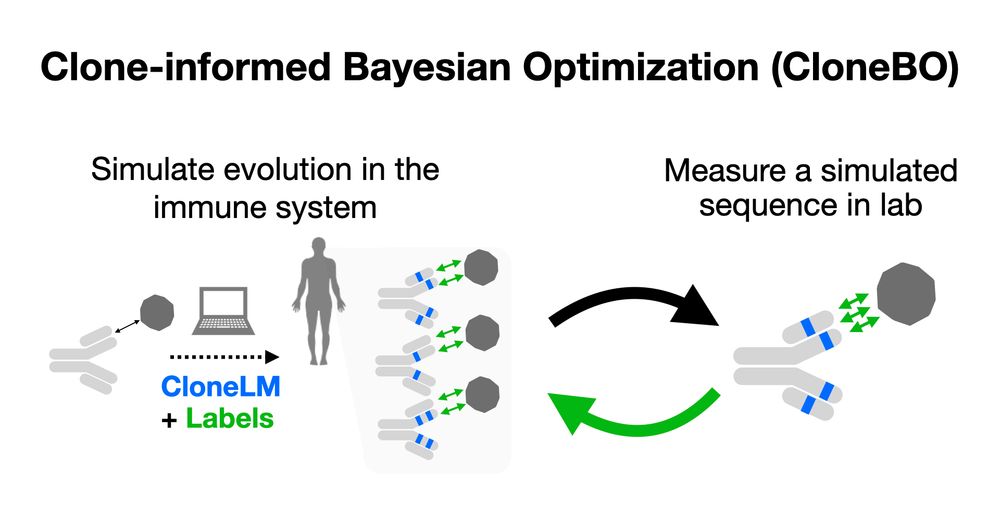
December 17, 2024 at 4:01 PM
How do you go from a hit in your antibody screen to a suitable drug? Now introducing CloneBO: we optimize antibodies in the lab by teaching a generative model how we optimize them in our bodies!
w/ Nat Gruver, Yilun Kuang, Lily Li, @andrewgwils.bsky.social and the team at Big Hat! 1/7
w/ Nat Gruver, Yilun Kuang, Lily Li, @andrewgwils.bsky.social and the team at Big Hat! 1/7
Will neural networks achieve AGI before they figure out how to do tokenization internally? Or, on the way to AGI, will they invent a tokenizer that "just works"? Another way of framing it: is tokenization AGI-complete?
November 27, 2024 at 5:40 AM
Will neural networks achieve AGI before they figure out how to do tokenization internally? Or, on the way to AGI, will they invent a tokenizer that "just works"? Another way of framing it: is tokenization AGI-complete?
JMLR and TMLR provide better reviewing, but worse publicity for accepted papers. Their only real platform, their accounts on X, get very little engagement these days. They should be on 🦋. Better yet, *MLR should have a biweekly or monthly arXiv-style email newsletter. @thegautamkamath.bsky.social
November 24, 2024 at 4:48 PM
JMLR and TMLR provide better reviewing, but worse publicity for accepted papers. Their only real platform, their accounts on X, get very little engagement these days. They should be on 🦋. Better yet, *MLR should have a biweekly or monthly arXiv-style email newsletter. @thegautamkamath.bsky.social
Pretty interesting new paper in TMLR: "Controlling the Fidelity and Diversity of Deep Generative Models via Pseudo Density" openreview.net/forum?id=8Vk...

Controlling the Fidelity and Diversity of Deep Generative Models...
We introduce an approach to bias deep generative models, such as GANs and diffusion models, towards generating data with either enhanced fidelity or increased diversity. Our approach involves...
openreview.net
November 22, 2024 at 10:22 PM
Pretty interesting new paper in TMLR: "Controlling the Fidelity and Diversity of Deep Generative Models via Pseudo Density" openreview.net/forum?id=8Vk...
Twitter is still a better place to share ML papers than Bluesky:


November 17, 2024 at 9:49 PM
Twitter is still a better place to share ML papers than Bluesky:
Excited to share a new paper published in TMLR, "Towards Backwards-Compatible Data with Confounded Domain Adaptation", solving a key problem in using AI for biology. How can you combine datasets across settings, when "what you measure" and "how you measure it" are confounded? 1/7

November 17, 2024 at 6:08 PM
Excited to share a new paper published in TMLR, "Towards Backwards-Compatible Data with Confounded Domain Adaptation", solving a key problem in using AI for biology. How can you combine datasets across settings, when "what you measure" and "how you measure it" are confounded? 1/7
Suppose you collect tissue samples with varying degrees of freshness, and want to correct for this. But what if freshness is also correlated with true biological differences (eg healthy vs cancer tissue)? My new paper out in TMLR addresses this problem: openreview.net/forum?id=GSp...
Towards Backwards-Compatible Data with Confounded Domain Adaptation
Most current domain adaptation methods address either covariate shift or label shift, but are not applicable where they occur simultaneously and are confounded with each other. Domain adaptation...
openreview.net
November 15, 2024 at 4:02 AM
Suppose you collect tissue samples with varying degrees of freshness, and want to correct for this. But what if freshness is also correlated with true biological differences (eg healthy vs cancer tissue)? My new paper out in TMLR addresses this problem: openreview.net/forum?id=GSp...