



David Schlangen
@davidschlangen.bsky.social
Prof of Computational Linguistics / NLP @ Uni Potsdam, Germany. Working on embodied / multimodal / conversational AI. In a way. Also affiliated w/ DFKI Berlin (German Research Center for AI).
Pinned
Do we do introductions here? Anyway, here is mine: I’m a Professor of Computational Linguistics at the University of Potsdam.
I am interested in understanding “understanding”, the process or activity by which an agent makes sense of its environment and, in interaction, of and with other agents.
I am interested in understanding “understanding”, the process or activity by which an agent makes sense of its environment and, in interaction, of and with other agents.
Bonus post advertising this other thread through the medium of "memes" which I've been told is what you have to do on social media.



July 20, 2025 at 11:44 AM
Bonus post advertising this other thread through the medium of "memes" which I've been told is what you have to do on social media.
It's great to see the idea of using games / interactions to evaluate LLMs gain traction, with textarena.ai and now ARC-AGI-3 being latest entrants.
This is something we've been exploring since early 2023 with clembench ( clembench.github.io ), which we've been continuously maintaining & extending. »
This is something we've been exploring since early 2023 with clembench ( clembench.github.io ), which we've been continuously maintaining & extending. »
July 20, 2025 at 11:21 AM
It's great to see the idea of using games / interactions to evaluate LLMs gain traction, with textarena.ai and now ARC-AGI-3 being latest entrants.
This is something we've been exploring since early 2023 with clembench ( clembench.github.io ), which we've been continuously maintaining & extending. »
This is something we've been exploring since early 2023 with clembench ( clembench.github.io ), which we've been continuously maintaining & extending. »
Reposted by David Schlangen

📄 [ACL 2025 main] LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks (doi.org/10.48550/arX...)
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
There is an increasing trend towards evaluating NLP models with LLMs instead of human judgments, raising questions about the validity of these evaluations, as well as their reproducibility in the case...
doi.org
July 18, 2025 at 10:19 AM
📄 [ACL 2025 main] LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks (doi.org/10.48550/arX...)
🚨 New pre-print! (Well, new & much improved version in any case.) 🚨
If you're interested in LLM post-training techniques and in how to make LLMs better "language users", read this thread, introducing the "LM Playpen".
If you're interested in LLM post-training techniques and in how to make LLMs better "language users", read this thread, introducing the "LM Playpen".

May 29, 2025 at 8:41 PM
🚨 New pre-print! (Well, new & much improved version in any case.) 🚨
If you're interested in LLM post-training techniques and in how to make LLMs better "language users", read this thread, introducing the "LM Playpen".
If you're interested in LLM post-training techniques and in how to make LLMs better "language users", read this thread, introducing the "LM Playpen".
The University of Potsdam invites applications for 5 postdoc positions, incl. Cognitive Sciences, incl. NLP (esp. cognitive).
These are fairly independent research positions that will allow the candidate to build their own profile. Dln June 2nd.
Details: tinyurl.com/pd-potsdam-2...
#NLProc #AI 🤖🧠
These are fairly independent research positions that will allow the candidate to build their own profile. Dln June 2nd.
Details: tinyurl.com/pd-potsdam-2...
#NLProc #AI 🤖🧠
tinyurl.com
May 21, 2025 at 3:53 PM
The University of Potsdam invites applications for 5 postdoc positions, incl. Cognitive Sciences, incl. NLP (esp. cognitive).
These are fairly independent research positions that will allow the candidate to build their own profile. Dln June 2nd.
Details: tinyurl.com/pd-potsdam-2...
#NLProc #AI 🤖🧠
These are fairly independent research positions that will allow the candidate to build their own profile. Dln June 2nd.
Details: tinyurl.com/pd-potsdam-2...
#NLProc #AI 🤖🧠
There's indeed suddenly a bit of flexibility in a system that's not exactly known for that.. If there's anyone (post-doc, tenure-track, or more senior) in the #NLP space currently in the US who'd like to explore possiblities in Potsdam, contact me.
🤖🧠
www.nytimes.com/2025/05/14/b...
🤖🧠
www.nytimes.com/2025/05/14/b...

The World Is Wooing U.S. Researchers Shunned by Trump
www.nytimes.com
May 14, 2025 at 12:02 PM
There's indeed suddenly a bit of flexibility in a system that's not exactly known for that.. If there's anyone (post-doc, tenure-track, or more senior) in the #NLP space currently in the US who'd like to explore possiblities in Potsdam, contact me.
🤖🧠
www.nytimes.com/2025/05/14/b...
🤖🧠
www.nytimes.com/2025/05/14/b...
"We ablated both algorithm and hyperparameter choices [...]"
When did "to ablate" take on the meaning "to systematically vary"? I've noticed this only recently, but it's seems to be super common now.
When did "to ablate" take on the meaning "to systematically vary"? I've noticed this only recently, but it's seems to be super common now.
May 7, 2025 at 9:04 PM
"We ablated both algorithm and hyperparameter choices [...]"
When did "to ablate" take on the meaning "to systematically vary"? I've noticed this only recently, but it's seems to be super common now.
When did "to ablate" take on the meaning "to systematically vary"? I've noticed this only recently, but it's seems to be super common now.
Reposted by David Schlangen
Update 2: New pre-print! Outcome of an ELLIS workshop last year, & more than a year of discussions and work, across labs and countries: Meet the Playpen, an environment for exploring learning in dialogic interaction.
arxiv.org/abs/2504.08590
1/2
arxiv.org/abs/2504.08590
1/2

April 15, 2025 at 6:51 PM
Update 2: New pre-print! Outcome of an ELLIS workshop last year, & more than a year of discussions and work, across labs and countries: Meet the Playpen, an environment for exploring learning in dialogic interaction.
arxiv.org/abs/2504.08590
1/2
arxiv.org/abs/2504.08590
1/2
Update 2: New pre-print! Outcome of an ELLIS workshop last year, & more than a year of discussions and work, across labs and countries: Meet the Playpen, an environment for exploring learning in dialogic interaction.
arxiv.org/abs/2504.08590
1/2
arxiv.org/abs/2504.08590
1/2
April 15, 2025 at 6:51 PM
Update 2: New pre-print! Outcome of an ELLIS workshop last year, & more than a year of discussions and work, across labs and countries: Meet the Playpen, an environment for exploring learning in dialogic interaction.
arxiv.org/abs/2504.08590
1/2
arxiv.org/abs/2504.08590
1/2
Update 1: New models added to our dialogue game-based agentic LLM leaderboard. TL;DR: GPT-4.1 as good as 4o, but much cheaper. Llama4 indeed not very good (decisively worse than 3.2 70B!). OLMo decent, but there's still a secret sauce that only closed labs have.
clembench.github.io
clembench.github.io
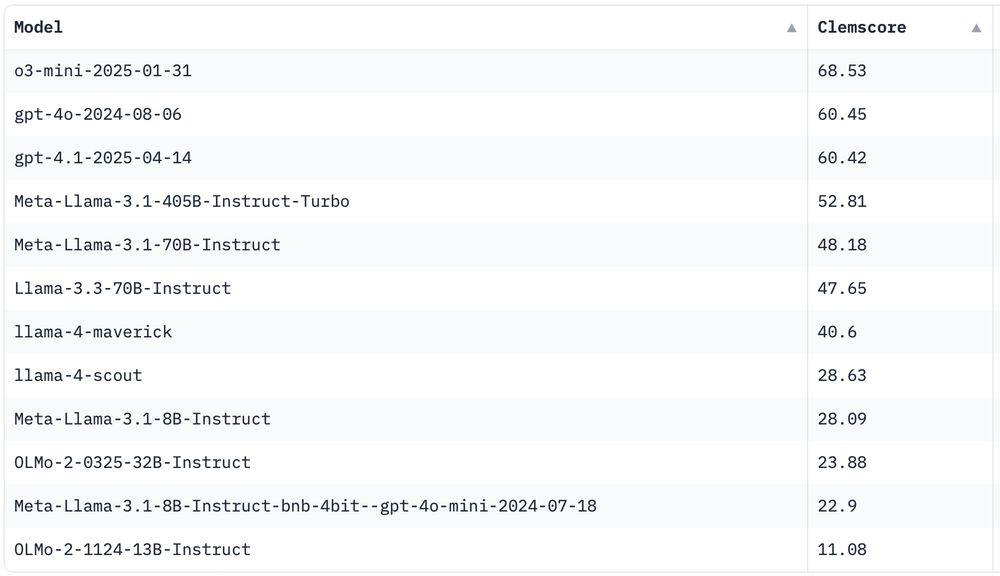
April 15, 2025 at 6:35 PM
Update 1: New models added to our dialogue game-based agentic LLM leaderboard. TL;DR: GPT-4.1 as good as 4o, but much cheaper. Llama4 indeed not very good (decisively worse than 3.2 70B!). OLMo decent, but there's still a secret sauce that only closed labs have.
clembench.github.io
clembench.github.io
Reposted by David Schlangen

Nicola Horst, Davide Mazzaccara, Antonia Schmidt, Michael Sullivan, Filippo Moment\`e, Luca Franceschetti, Philipp Sadler, Sherzod Hakimov, Alberto Testoni, ...
Playpen: An Environment for Exploring Learning Through Conversational Interaction
https://arxiv.org/abs/2504.08590
Playpen: An Environment for Exploring Learning Through Conversational Interaction
https://arxiv.org/abs/2504.08590
April 14, 2025 at 5:36 AM
Nicola Horst, Davide Mazzaccara, Antonia Schmidt, Michael Sullivan, Filippo Moment\`e, Luca Franceschetti, Philipp Sadler, Sherzod Hakimov, Alberto Testoni, ...
Playpen: An Environment for Exploring Learning Through Conversational Interaction
https://arxiv.org/abs/2504.08590
Playpen: An Environment for Exploring Learning Through Conversational Interaction
https://arxiv.org/abs/2504.08590
Wenn die Grünen verhandeln könnten, würden am Tag vor einer Ankündigung über eine Einigung zur Schuldenbremse Söder und Dobrindt ankündigen, dass sie sich für immer aus der Bundespolitik heraushalten werden (und dass die CSU nie wieder einen Verkehrsminister stellen wird).
March 6, 2025 at 4:05 PM
Wenn die Grünen verhandeln könnten, würden am Tag vor einer Ankündigung über eine Einigung zur Schuldenbremse Söder und Dobrindt ankündigen, dass sie sich für immer aus der Bundespolitik heraushalten werden (und dass die CSU nie wieder einen Verkehrsminister stellen wird).
Press release by my Uni about our benchmark for LLMs as agents, which is now out in v2.0.
Check it out here: clembench.github.io
Check it out here: clembench.github.io
March 6, 2025 at 11:01 AM
Press release by my Uni about our benchmark for LLMs as agents, which is now out in v2.0.
Check it out here: clembench.github.io
Check it out here: clembench.github.io
Happy to see increasing interest in exploring social interaction as a learning environment!
Along similar lines: We’re preparing a (complementary) challenge that will focus on exploring interaction for post-training, coming with a rich interaction environment to get things started. Stay tuned!
Along similar lines: We’re preparing a (complementary) challenge that will focus on exploring interaction for post-training, coming with a rich interaction environment to get things started. Stay tuned!

We are expecting🫄
A 3rd BabyLM👶, as a workshop
@emnlpmeeting.bsky.social
Kept: all
New:
Interaction (education, agentic) track
Workshop papers
More in 🧵
Even more:
arxiv.org/abs/2502.10645
babylm.github.io
#AI #LLMs #MachineLearning #language #cognition #NLP #data
🤖📈
A 3rd BabyLM👶, as a workshop
@emnlpmeeting.bsky.social
Kept: all
New:
Interaction (education, agentic) track
Workshop papers
More in 🧵
Even more:
arxiv.org/abs/2502.10645
babylm.github.io
#AI #LLMs #MachineLearning #language #cognition #NLP #data
🤖📈

February 19, 2025 at 9:50 PM
Happy to see increasing interest in exploring social interaction as a learning environment!
Along similar lines: We’re preparing a (complementary) challenge that will focus on exploring interaction for post-training, coming with a rich interaction environment to get things started. Stay tuned!
Along similar lines: We’re preparing a (complementary) challenge that will focus on exploring interaction for post-training, coming with a rich interaction environment to get things started. Stay tuned!
I'm not on X, so I'll use the opportunity of @karpathy.bsky.social 's post over there to plug our "clembench" project here. We've been doing exactly this--evaluating LLMs w/ conversational games--since early 2023, with several papers out by now (e.g. EMNLP 23).
clembench.github.io
clembench.github.io

February 3, 2025 at 10:22 AM
I'm not on X, so I'll use the opportunity of @karpathy.bsky.social 's post over there to plug our "clembench" project here. We've been doing exactly this--evaluating LLMs w/ conversational games--since early 2023, with several papers out by now (e.g. EMNLP 23).
clembench.github.io
clembench.github.io
So, are we banning social network apps now whose owners potentially try to influence the political discourse in other countries? Asking for a supranational political and economic union.
January 17, 2025 at 4:27 PM
So, are we banning social network apps now whose owners potentially try to influence the political discourse in other countries? Asking for a supranational political and economic union.
I just randomly found this book on my bookshelf. It must have been transported there from an alternate timeline. “20 years of research on agents”? Preposterous! We all know that the very idea of software agents has only been invented last year by the LLM folks!

January 16, 2025 at 11:50 AM
I just randomly found this book on my bookshelf. It must have been transported there from an alternate timeline. “20 years of research on agents”? Preposterous! We all know that the very idea of software agents has only been invented last year by the LLM folks!
So my car needed to be towed this morning. It took the guy quite some time to get everything ready. Then the truck broke down. In the end, the tow truck was towed, and I got a new appointment.
I think is probably an allegory for something, maybe the ending year 2024, or the coming year 2025.
I think is probably an allegory for something, maybe the ending year 2024, or the coming year 2025.
December 31, 2024 at 10:23 AM
So my car needed to be towed this morning. It took the guy quite some time to get everything ready. Then the truck broke down. In the end, the tow truck was towed, and I got a new appointment.
I think is probably an allegory for something, maybe the ending year 2024, or the coming year 2025.
I think is probably an allegory for something, maybe the ending year 2024, or the coming year 2025.
me: I would really like to end this year with inbox zero.
also me: I would really like to end this year with cookie jar zero / “pages remaining in the books I’ve started” zero.
me again, expert problem solver: *creates IMAP folder “unprocessed emails from 2024”, selects all, moves 625 items*
also me: I would really like to end this year with cookie jar zero / “pages remaining in the books I’ve started” zero.
me again, expert problem solver: *creates IMAP folder “unprocessed emails from 2024”, selects all, moves 625 items*
December 30, 2024 at 2:06 PM
me: I would really like to end this year with inbox zero.
also me: I would really like to end this year with cookie jar zero / “pages remaining in the books I’ve started” zero.
me again, expert problem solver: *creates IMAP folder “unprocessed emails from 2024”, selects all, moves 625 items*
also me: I would really like to end this year with cookie jar zero / “pages remaining in the books I’ve started” zero.
me again, expert problem solver: *creates IMAP folder “unprocessed emails from 2024”, selects all, moves 625 items*
These new models (using “inference time scaling”) bring out what many of us have been saying for a long time, namely that reasoning fundamentally is a discursive process. (What they are missing is that it is an intersubjective, interactive, repairable, and ultimately normative one.)
December 20, 2024 at 8:36 PM
These new models (using “inference time scaling”) bring out what many of us have been saying for a long time, namely that reasoning fundamentally is a discursive process. (What they are missing is that it is an intersubjective, interactive, repairable, and ultimately normative one.)
Looking forward to the first lecture of next year, where I can again use this meme I made a couple of years ago and multiply confuse the students in my "intro to NLP" class. (What is an "LP cover"? Who is that person?)

December 20, 2024 at 12:38 PM
Looking forward to the first lecture of next year, where I can again use this meme I made a couple of years ago and multiply confuse the students in my "intro to NLP" class. (What is an "LP cover"? Who is that person?)
Can we discuss how stupid this photo button thing on the new iPhones is? Who thought that minimising the space where you can hold this damn thing without something unwanted happening is a good idea?
December 4, 2024 at 12:32 PM
Can we discuss how stupid this photo button thing on the new iPhones is? Who thought that minimising the space where you can hold this damn thing without something unwanted happening is a good idea?
For a recent talk to a lay audience, I’ve used a metaphor which I think resonated: rely on an LLMs not more than you would rely on a dream. Use it to inspire you to work something out, but don’t be the one who has to say “this was once revealed to me in a dream”.
December 1, 2024 at 10:00 AM
For a recent talk to a lay audience, I’ve used a metaphor which I think resonated: rely on an LLMs not more than you would rely on a dream. Use it to inspire you to work something out, but don’t be the one who has to say “this was once revealed to me in a dream”.
Some good news: The world now has one more doctor! Brielen Madureira passed her viva with flying colours (or, as we say in German, summa cum laude). She gave us quite some material to discuss in the viva, ending with the attached theses. (Remote: Luciana Benotti as fantastic examiner.)


November 28, 2024 at 5:45 PM
Some good news: The world now has one more doctor! Brielen Madureira passed her viva with flying colours (or, as we say in German, summa cum laude). She gave us quite some material to discuss in the viva, ending with the attached theses. (Remote: Luciana Benotti as fantastic examiner.)
Ok, this is starting to feel weird. The internet at my Uni has been down for almost 24 hours now, meaning: no new emails for almost 24 hours now. That’s like the dog finally catching the bus. What now??
November 28, 2024 at 11:07 AM
Ok, this is starting to feel weird. The internet at my Uni has been down for almost 24 hours now, meaning: no new emails for almost 24 hours now. That’s like the dog finally catching the bus. What now??