
Egor Zverev
@egorzverev.bsky.social
46 followers
85 following
23 posts
ml safety researcher | visiting phd student @ETHZ | doing phd @ISTA | prev. @phystech | prev. developer @GSOC | love poetry
Posts
Media
Videos
Starter Packs


Reposted by Egor Zverev


Reposted by Egor Zverev

Zeynep Akata
@zeynepakata.bsky.social
· Aug 28
Reposted by Egor Zverev


Egor Zverev
@egorzverev.bsky.social
· Jul 25
Reposted by Egor Zverev


Egor Zverev
@egorzverev.bsky.social
· Jun 24

Reposted by Egor Zverev

Reposted by Egor Zverev

Egor Zverev
@egorzverev.bsky.social
· Apr 25

Egor Zverev
@egorzverev.bsky.social
· Mar 18

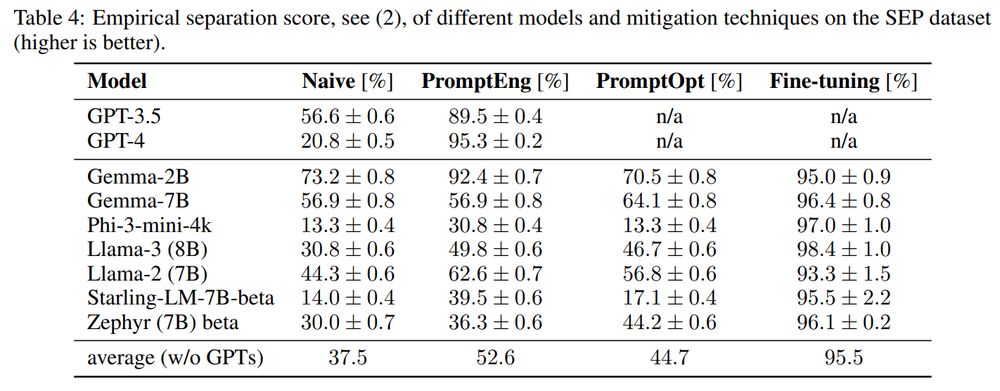
GitHub - egozverev/Should-It-Be-Executed-Or-Processed: Accompanying code and SEP dataset for the "Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?" paper.
Accompanying code and SEP dataset for the "Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?" paper. - GitHub - egozverev/Should-It-Be-Executed-Or-Processed: A...
github.com
Egor Zverev
@egorzverev.bsky.social
· Mar 18
Egor Zverev
@egorzverev.bsky.social
· Mar 18

Egor Zverev
@egorzverev.bsky.social
· Mar 18
