



Elana Simon
@elanasimon.bsky.social
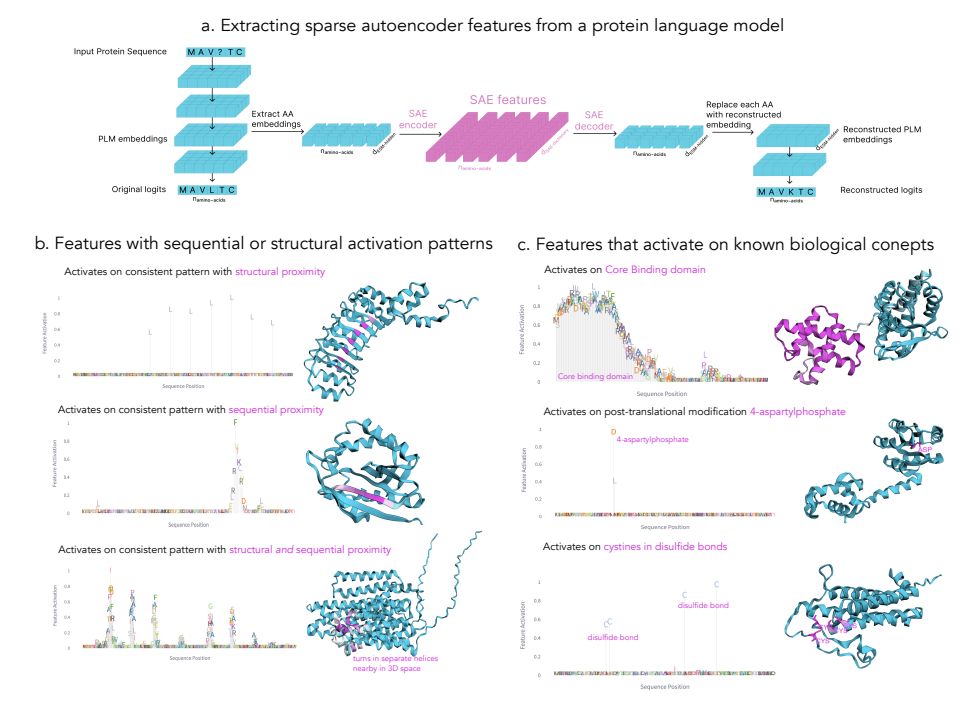
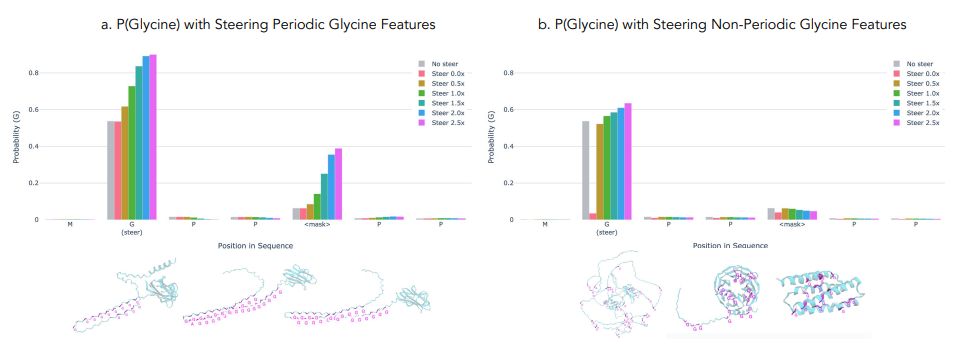
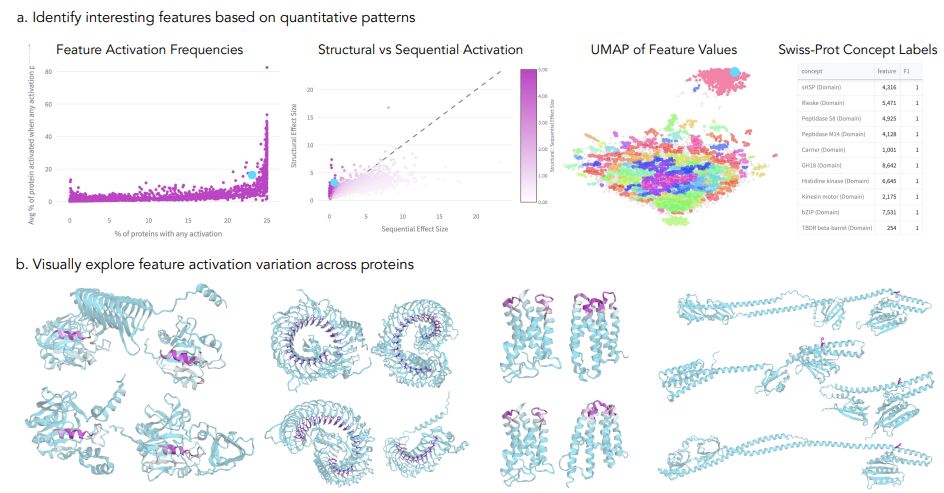
🧬 What are protein language models (PLMs) actually learning about biology? Our paper introduces InterPLM - a framework that reveals interpretable features in PLMs using sparse autoencoders, giving us a window into how these models represent protein structure and function.
🧵(1/8)
🧵(1/8)

November 19, 2024 at 7:36 PM
🧬 What are protein language models (PLMs) actually learning about biology? Our paper introduces InterPLM - a framework that reveals interpretable features in PLMs using sparse autoencoders, giving us a window into how these models represent protein structure and function.
🧵(1/8)
🧵(1/8)
Reposted by Elana Simon

www.biorxiv.org/content/10.1...
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders
Code: github.com/ElanaPearl/I...
Interactive site: interplm.ai
Nice work by Elana Simon from James Zou lab
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders
Code: github.com/ElanaPearl/I...
Interactive site: interplm.ai
Nice work by Elana Simon from James Zou lab

InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders
Protein language models (PLMs) have demonstrated remarkable success in protein modeling and design, yet their internal mechanisms for predicting structure and function remain poorly understood. Here w...
www.biorxiv.org
November 19, 2024 at 2:39 AM
www.biorxiv.org/content/10.1...
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders
Code: github.com/ElanaPearl/I...
Interactive site: interplm.ai
Nice work by Elana Simon from James Zou lab
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders
Code: github.com/ElanaPearl/I...
Interactive site: interplm.ai
Nice work by Elana Simon from James Zou lab
Reposted by Elana Simon

November 18, 2024 at 10:20 PM