



@eleutherai.bsky.social
If you can't make it, no problem! All of our reading groups and speaker series upload to our YouTube. We have over 100 hours of content on topics from ML Scalability and Performance to Functional Analysis to podcasts and interviews featuring our team.
www.youtube.com/@Eleuther_AI...
www.youtube.com/@Eleuther_AI...

EleutherAI
www.youtube.com
June 26, 2025 at 6:16 PM
If you can't make it, no problem! All of our reading groups and speaker series upload to our YouTube. We have over 100 hours of content on topics from ML Scalability and Performance to Functional Analysis to podcasts and interviews featuring our team.
www.youtube.com/@Eleuther_AI...
www.youtube.com/@Eleuther_AI...
Her talk with be primarily drawing on two recent papers:
"BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training" arxiv.org/abs/2409.04599
"BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization" arxiv.org/abs/2505.24689
"BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training" arxiv.org/abs/2409.04599
"BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization" arxiv.org/abs/2505.24689

BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization
Byte Pair Encoding (BPE) tokenizers, widely used in Large Language Models, face challenges in multilingual settings, including penalization of non-Western scripts and the creation of tokens with parti...
arxiv.org
June 26, 2025 at 6:16 PM
Her talk with be primarily drawing on two recent papers:
"BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training" arxiv.org/abs/2409.04599
"BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization" arxiv.org/abs/2505.24689
"BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training" arxiv.org/abs/2409.04599
"BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization" arxiv.org/abs/2505.24689
We are launching a new speaker series at EleutherAI, focused on promoting recent research by our team and community members.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.

June 26, 2025 at 6:16 PM
We are launching a new speaker series at EleutherAI, focused on promoting recent research by our team and community members.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.
This dataset was previewed at the Datasets Convening we co-hosted with @mozilla.org to consult with leading experts in open datasets.
Read more about the event: blog.mozilla.org/en/mozilla/d...
And the paper distilling the best practices participants identified: arxiv.org/abs/2501.08365
Read more about the event: blog.mozilla.org/en/mozilla/d...
And the paper distilling the best practices participants identified: arxiv.org/abs/2501.08365

Mozilla, EleutherAI publish research on open datasets for LLM training | The Mozilla Blog
Update: Following the 2024 Mozilla AI Dataset Convening, AI builders and researchers publish best practices for creating open datasets for LLM training.&nb
blog.mozilla.org
June 6, 2025 at 7:19 PM
This dataset was previewed at the Datasets Convening we co-hosted with @mozilla.org to consult with leading experts in open datasets.
Read more about the event: blog.mozilla.org/en/mozilla/d...
And the paper distilling the best practices participants identified: arxiv.org/abs/2501.08365
Read more about the event: blog.mozilla.org/en/mozilla/d...
And the paper distilling the best practices participants identified: arxiv.org/abs/2501.08365
This was a huge effort across twelve institutions. Thank you to all the authors for their hard work.
This work was supported by @mozilla.org @mozilla.ai, Sutter Hill Ventures, the National Sciences and Engineering Research Council of Canada, and Lawrence Livermore National Laboratory.
This work was supported by @mozilla.org @mozilla.ai, Sutter Hill Ventures, the National Sciences and Engineering Research Council of Canada, and Lawrence Livermore National Laboratory.
June 6, 2025 at 7:19 PM
This was a huge effort across twelve institutions. Thank you to all the authors for their hard work.
This work was supported by @mozilla.org @mozilla.ai, Sutter Hill Ventures, the National Sciences and Engineering Research Council of Canada, and Lawrence Livermore National Laboratory.
This work was supported by @mozilla.org @mozilla.ai, Sutter Hill Ventures, the National Sciences and Engineering Research Council of Canada, and Lawrence Livermore National Laboratory.
For more, check out...
Paper: arxiv.org/abs/2506.05209
Artifacts: huggingface.co/common-pile
GitHub: github.com/r-three/comm...
EleutherAI's blog post: huggingface.co/blog/stellaa...
Coverage in @washingtonpost.com by @nitasha.bsky.social: www.washingtonpost.com/politics/202...
Paper: arxiv.org/abs/2506.05209
Artifacts: huggingface.co/common-pile
GitHub: github.com/r-three/comm...
EleutherAI's blog post: huggingface.co/blog/stellaa...
Coverage in @washingtonpost.com by @nitasha.bsky.social: www.washingtonpost.com/politics/202...
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concern...
arxiv.org
June 6, 2025 at 7:19 PM
For more, check out...
Paper: arxiv.org/abs/2506.05209
Artifacts: huggingface.co/common-pile
GitHub: github.com/r-three/comm...
EleutherAI's blog post: huggingface.co/blog/stellaa...
Coverage in @washingtonpost.com by @nitasha.bsky.social: www.washingtonpost.com/politics/202...
Paper: arxiv.org/abs/2506.05209
Artifacts: huggingface.co/common-pile
GitHub: github.com/r-three/comm...
EleutherAI's blog post: huggingface.co/blog/stellaa...
Coverage in @washingtonpost.com by @nitasha.bsky.social: www.washingtonpost.com/politics/202...
We're calling this v0.1 for a reason: we are excited to continue to build the open data ecosystem and hope to train bigger models on more data in the future!
If you know datasets we should include in the next version, open an issue: github.com/r-three/comm...
If you know datasets we should include in the next version, open an issue: github.com/r-three/comm...
June 6, 2025 at 7:19 PM
We're calling this v0.1 for a reason: we are excited to continue to build the open data ecosystem and hope to train bigger models on more data in the future!
If you know datasets we should include in the next version, open an issue: github.com/r-three/comm...
If you know datasets we should include in the next version, open an issue: github.com/r-three/comm...
Several other groups have put out openly licensed dataset recently, why is ours better? Ablation studies show trained on Common Pile v0.1 outperform them, matching the performance of models trained on the original Pile and OSCAR, though still falling short of FineWeb

June 6, 2025 at 7:19 PM
Several other groups have put out openly licensed dataset recently, why is ours better? Ablation studies show trained on Common Pile v0.1 outperform them, matching the performance of models trained on the original Pile and OSCAR, though still falling short of FineWeb
Our pretrained models, Comma v0.1-1T and -2T perform comparably to leading models trained in the same regime. These plots also include Qwen as a SOTA 8B reference, though it saw 36T tokens


June 6, 2025 at 7:19 PM
Our pretrained models, Comma v0.1-1T and -2T perform comparably to leading models trained in the same regime. These plots also include Qwen as a SOTA 8B reference, though it saw 36T tokens
We put a lot of work into our metadata, such as having two rounds of manually validating the ToS of websites in Common Crawl, manually identifying trustworthy YouTube channels, and leveraging work by the BigCode Project and @softwareheritage.org to build the openly licensed subset of StackV2.
June 6, 2025 at 7:19 PM
We put a lot of work into our metadata, such as having two rounds of manually validating the ToS of websites in Common Crawl, manually identifying trustworthy YouTube channels, and leveraging work by the BigCode Project and @softwareheritage.org to build the openly licensed subset of StackV2.
The project of open science for machine learning only works if we are able to distribute the training data. Openly licensed data lets us do that, under mild conditions. We make sure to provide document-level metadata for authorship, licensing information, links back to the originals, and more.



June 6, 2025 at 7:19 PM
The project of open science for machine learning only works if we are able to distribute the training data. Openly licensed data lets us do that, under mild conditions. We make sure to provide document-level metadata for authorship, licensing information, links back to the originals, and more.
What do we mean by "openly licensed" data? Following the lead of orgs like @wikimediafoundation.org and @creativecommons.bsky.social we adopt the definition laid out by @okfn.bsky.social: opendefinition.org
Succinctly put, it's data that anyone can use, modify, and share for any purpose.
Succinctly put, it's data that anyone can use, modify, and share for any purpose.

June 6, 2025 at 7:19 PM
What do we mean by "openly licensed" data? Following the lead of orgs like @wikimediafoundation.org and @creativecommons.bsky.social we adopt the definition laid out by @okfn.bsky.social: opendefinition.org
Succinctly put, it's data that anyone can use, modify, and share for any purpose.
Succinctly put, it's data that anyone can use, modify, and share for any purpose.
The Common Pile comprises text from 30 distinct sources, covering a wide variety of domains including research papers, code, books, educational materials, audio transcripts, governmental text, and more. Some of this text is commonplace in AI, but a lot of it is pretty new.

June 6, 2025 at 7:19 PM
The Common Pile comprises text from 30 distinct sources, covering a wide variety of domains including research papers, code, books, educational materials, audio transcripts, governmental text, and more. Some of this text is commonplace in AI, but a lot of it is pretty new.
Can you train a performant language model using only openly licensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2

June 6, 2025 at 7:19 PM
Can you train a performant language model using only openly licensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
Reposted

Call for papers!
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
1st Workshop on Multilingual Data Quality Signals
wmdqs.org
May 29, 2025 at 5:18 PM
Call for papers!
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
Today, at 11am ET, @storytracer.org will be giving a live demo on the @mozilla.ai Discord showcasing two Blueprints for creating open datasets: audio transcription using self-hosted Whisper models and document conversion using Docling. Join the event here: discord.com/invite/4jtc8...

April 28, 2025 at 12:26 PM
Today, at 11am ET, @storytracer.org will be giving a live demo on the @mozilla.ai Discord showcasing two Blueprints for creating open datasets: audio transcription using self-hosted Whisper models and document conversion using Docling. Join the event here: discord.com/invite/4jtc8...
Very cool work!

🚀 **Exciting News!** 🎉 Evalita-LLM is here! 🇮🇹 A new benchmark for evaluating LLMs—offering native Italian tasks, generative challenges, and fair multi-prompt evaluations. Now also available in lm-evaluation harness by @eleutherai.bsky.social !
ArXiv: arxiv.org/abs/2502.02289
#NLProc #LLM #Evaluation
ArXiv: arxiv.org/abs/2502.02289
#NLProc #LLM #Evaluation

Evalita-LLM: Benchmarking Large Language Models on Italian
We describe Evalita-LLM, a new benchmark designed to evaluate Large Language Models (LLMs) on Italian tasks. The distinguishing and innovative features of Evalita-LLM are the following: (i) all tasks ...
arxiv.org
February 24, 2025 at 10:03 PM
Very cool work!
Reposted

Proud to be at the AI Action Summit representing @eleutherai.bsky.social and the open source community. The focus on AI for the public good is exciting! DM me or @aviya.bsky.social to talk about centering openness, transparency, and public good in the AI ecosystem.
February 10, 2025 at 11:51 AM
Proud to be at the AI Action Summit representing @eleutherai.bsky.social and the open source community. The focus on AI for the public good is exciting! DM me or @aviya.bsky.social to talk about centering openness, transparency, and public good in the AI ecosystem.
Reposted

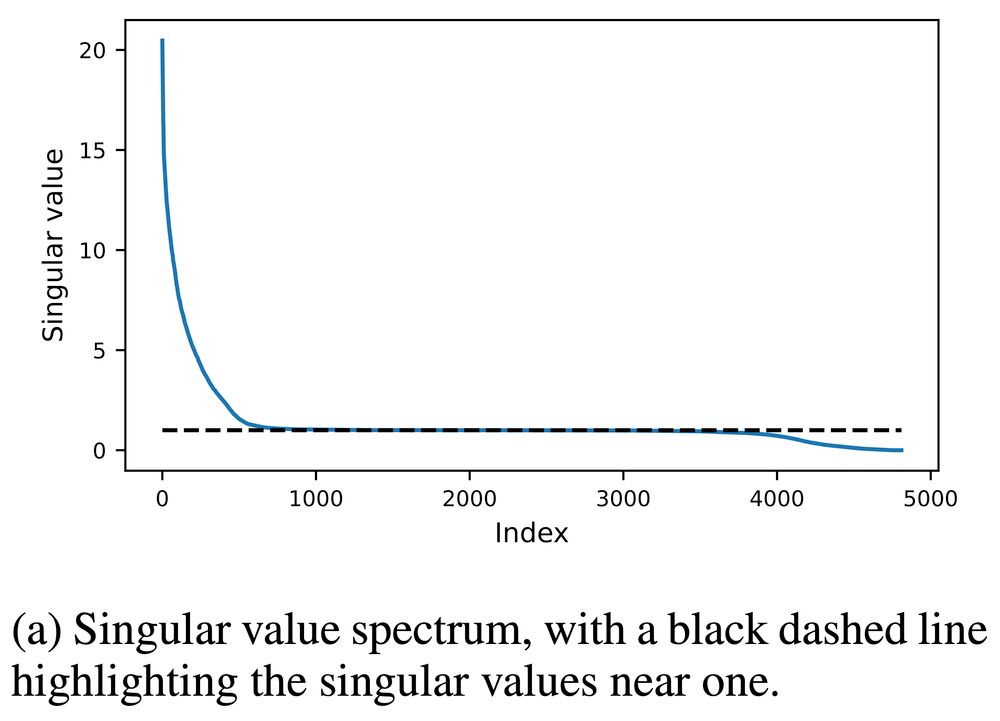
How do a neural network's final parameters depend on its initial ones?
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
December 11, 2024 at 8:30 PM
How do a neural network's final parameters depend on its initial ones?
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
You can find our code here: github.com/EleutherAI/s...
If you're interested in helping out with this kind of research, check out the concept-editing channel on our Discord.
This work is by Thomas Marshall, Adam Scherlis, and @norabelrose.bsky.social. It is funded in part by a grant from OpenPhil.
If you're interested in helping out with this kind of research, check out the concept-editing channel on our Discord.
This work is by Thomas Marshall, Adam Scherlis, and @norabelrose.bsky.social. It is funded in part by a grant from OpenPhil.

GitHub - EleutherAI/steering-llama3
Contribute to EleutherAI/steering-llama3 development by creating an account on GitHub.
github.com
November 22, 2024 at 3:15 AM
You can find our code here: github.com/EleutherAI/s...
If you're interested in helping out with this kind of research, check out the concept-editing channel on our Discord.
This work is by Thomas Marshall, Adam Scherlis, and @norabelrose.bsky.social. It is funded in part by a grant from OpenPhil.
If you're interested in helping out with this kind of research, check out the concept-editing channel on our Discord.
This work is by Thomas Marshall, Adam Scherlis, and @norabelrose.bsky.social. It is funded in part by a grant from OpenPhil.
ACE isn't just for RWKV! ACE enables more precise control over model behavior than prior methods. For example, on Gemma, we cause the model to behave almost identically on harmless and harmful prompts — either refusing all of them, or accepting all of them — for a fixed steering parameter.

November 22, 2024 at 3:15 AM
ACE isn't just for RWKV! ACE enables more precise control over model behavior than prior methods. For example, on Gemma, we cause the model to behave almost identically on harmless and harmful prompts — either refusing all of them, or accepting all of them — for a fixed steering parameter.
ACE (Affine Concept Editing) assumes that concepts are affine functions, rather than linear ones. It projects activations onto a hyperplane containing the centroid of the target behavior — one which may not pass through the origin.

November 22, 2024 at 3:15 AM
ACE (Affine Concept Editing) assumes that concepts are affine functions, rather than linear ones. It projects activations onto a hyperplane containing the centroid of the target behavior — one which may not pass through the origin.
For example, Arditi et al. (arxiv.org/abs/2406.11717) argued that refusal is mediated by a single "direction," or linear subspace, in many language models. But when we applied their method on a RWKV model, we got nonsense results! We propose a new method called ACE, that fixes this issue.

November 22, 2024 at 3:15 AM
For example, Arditi et al. (arxiv.org/abs/2406.11717) argued that refusal is mediated by a single "direction," or linear subspace, in many language models. But when we applied their method on a RWKV model, we got nonsense results! We propose a new method called ACE, that fixes this issue.
The latest from our interpretability team: there is an ambiguity in prior work on the linear representation hypothesis:
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Refusal in LLMs is an Affine Function
We propose affine concept editing (ACE) as an approach for steering language models' behavior by intervening directly in activations. We begin with an affine decomposition of model activation vectors ...
arxiv.org
November 22, 2024 at 3:15 AM
The latest from our interpretability team: there is an ambiguity in prior work on the linear representation hypothesis:
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Hi! You could add us :) @stellaathena.bsky.social and @norabelrose.bsky.social are here too.
November 20, 2024 at 9:56 PM
Hi! You could add us :) @stellaathena.bsky.social and @norabelrose.bsky.social are here too.