




Feldera
@feldera.bsky.social
The incremental compute platform for data-intensive products
Your pipeline was disrupted.
Feldera’s Health Page tells you why in seconds. No K8s access. No waiting on DevOps.
Details -> www.feldera.com/blog/introdu...
Feldera’s Health Page tells you why in seconds. No K8s access. No waiting on DevOps.
Details -> www.feldera.com/blog/introdu...

January 26, 2026 at 9:15 PM
Your pipeline was disrupted.
Feldera’s Health Page tells you why in seconds. No K8s access. No waiting on DevOps.
Details -> www.feldera.com/blog/introdu...
Feldera’s Health Page tells you why in seconds. No K8s access. No waiting on DevOps.
Details -> www.feldera.com/blog/introdu...
Introducing Feldera Health 🩺
A lightweight health monitoring solution built directly into Feldera. See the real-time status of your compiler, API server, and runner at a glance.
✅ Available today on try.feldera.com and Enterprise Feldera
📝 Detailed technical blog coming soon
A lightweight health monitoring solution built directly into Feldera. See the real-time status of your compiler, API server, and runner at a glance.
✅ Available today on try.feldera.com and Enterprise Feldera
📝 Detailed technical blog coming soon
January 22, 2026 at 7:00 PM
Introducing Feldera Health 🩺
A lightweight health monitoring solution built directly into Feldera. See the real-time status of your compiler, API server, and runner at a glance.
✅ Available today on try.feldera.com and Enterprise Feldera
📝 Detailed technical blog coming soon
A lightweight health monitoring solution built directly into Feldera. See the real-time status of your compiler, API server, and runner at a glance.
✅ Available today on try.feldera.com and Enterprise Feldera
📝 Detailed technical blog coming soon
Incremental Updates - January 2026 edition is here! 🚀
This edition covers:
- Product updates: adaptive join rebalancing, GC for ASOF joins and more
- New blogs: deep dive into our profiler, constant folding in Calcite, and a look back at our progress in 2025
www.linkedin.com/pulse/januar...
This edition covers:
- Product updates: adaptive join rebalancing, GC for ASOF joins and more
- New blogs: deep dive into our profiler, constant folding in Calcite, and a look back at our progress in 2025
www.linkedin.com/pulse/januar...

January Edition 2026
The past many months have been busy for us at Feldera. We continue to ship compounding improvements for our customers when it comes to usability, performance and efficiency.
www.linkedin.com
January 15, 2026 at 5:50 PM
Incremental Updates - January 2026 edition is here! 🚀
This edition covers:
- Product updates: adaptive join rebalancing, GC for ASOF joins and more
- New blogs: deep dive into our profiler, constant folding in Calcite, and a look back at our progress in 2025
www.linkedin.com/pulse/januar...
This edition covers:
- Product updates: adaptive join rebalancing, GC for ASOF joins and more
- New blogs: deep dive into our profiler, constant folding in Calcite, and a look back at our progress in 2025
www.linkedin.com/pulse/januar...
🩻 X-ray vision for your SQL pipeline in Feldera.
-Click any node -> see metrics across all cores.
-Heat map shows bottlenecks instantly.
-Expand to trace back to your SQL code.
⚡ Seconds to see what used to take hours to find.
Dive deeper: www.feldera.com/blog/introdu...
-Click any node -> see metrics across all cores.
-Heat map shows bottlenecks instantly.
-Expand to trace back to your SQL code.
⚡ Seconds to see what used to take hours to find.
Dive deeper: www.feldera.com/blog/introdu...
December 23, 2025 at 9:38 PM
🩻 X-ray vision for your SQL pipeline in Feldera.
-Click any node -> see metrics across all cores.
-Heat map shows bottlenecks instantly.
-Expand to trace back to your SQL code.
⚡ Seconds to see what used to take hours to find.
Dive deeper: www.feldera.com/blog/introdu...
-Click any node -> see metrics across all cores.
-Heat map shows bottlenecks instantly.
-Expand to trace back to your SQL code.
⚡ Seconds to see what used to take hours to find.
Dive deeper: www.feldera.com/blog/introdu...
2025:
📦 166 unique releases, 1,162 changes, avg. new release every 2.4 days
📊 10x cost reduction for users, hours old insights into sub-second latency
⚡ 70-node Spark clusters -> single digit Feldera instances
2026: Make incremental compute inevitable
Full story: www.feldera.com/blog/feldera...
📦 166 unique releases, 1,162 changes, avg. new release every 2.4 days
📊 10x cost reduction for users, hours old insights into sub-second latency
⚡ 70-node Spark clusters -> single digit Feldera instances
2026: Make incremental compute inevitable
Full story: www.feldera.com/blog/feldera...

Feldera in 2025: Building the Future of Incremental Compute
Feldera's 2025 year in review: comprehensive SQL support, state-of-the-art infrastructure, advanced connectors, and the future of real-time analytics.
www.feldera.com
December 19, 2025 at 6:59 PM
2025:
📦 166 unique releases, 1,162 changes, avg. new release every 2.4 days
📊 10x cost reduction for users, hours old insights into sub-second latency
⚡ 70-node Spark clusters -> single digit Feldera instances
2026: Make incremental compute inevitable
Full story: www.feldera.com/blog/feldera...
📦 166 unique releases, 1,162 changes, avg. new release every 2.4 days
📊 10x cost reduction for users, hours old insights into sub-second latency
⚡ 70-node Spark clusters -> single digit Feldera instances
2026: Make incremental compute inevitable
Full story: www.feldera.com/blog/feldera...
You can’t optimize what you can’t profile.
Which operators are a bottleneck? Are there skewed joins? Why is storage use spiking?
Our engineering team used to spend hours trying to answer these questions when performance problems would show up in the wild.
Which operators are a bottleneck? Are there skewed joins? Why is storage use spiking?
Our engineering team used to spend hours trying to answer these questions when performance problems would show up in the wild.
December 11, 2025 at 5:44 PM
You can’t optimize what you can’t profile.
Which operators are a bottleneck? Are there skewed joins? Why is storage use spiking?
Our engineering team used to spend hours trying to answer these questions when performance problems would show up in the wild.
Which operators are a bottleneck? Are there skewed joins? Why is storage use spiking?
Our engineering team used to spend hours trying to answer these questions when performance problems would show up in the wild.
Rust Compilation can be slow. Backfills can take days. And no one likes to wait. ⏳
We’ve recently shipped features that will get you deploying faster and scaling more efficiently:
- Parallel Compilation
- Fast Backfill
- Backfill Avoidance
We’ve recently shipped features that will get you deploying faster and scaling more efficiently:
- Parallel Compilation
- Fast Backfill
- Backfill Avoidance
December 3, 2025 at 6:54 PM
Rust Compilation can be slow. Backfills can take days. And no one likes to wait. ⏳
We’ve recently shipped features that will get you deploying faster and scaling more efficiently:
- Parallel Compilation
- Fast Backfill
- Backfill Avoidance
We’ve recently shipped features that will get you deploying faster and scaling more efficiently:
- Parallel Compilation
- Fast Backfill
- Backfill Avoidance
If you’re excited about hard technical problems and want to shape the future of real-time systems, Feldera is hiring (remotely!) for a Solutions Engineer (Enterprise) and a Software Engineer (Reliability, Performance)
jobs.ashbyhq.com/feldera/544a...
jobs.ashbyhq.com/feldera/544a...
Jobs
jobs.ashbyhq.com
September 6, 2025 at 12:57 AM
If you’re excited about hard technical problems and want to shape the future of real-time systems, Feldera is hiring (remotely!) for a Solutions Engineer (Enterprise) and a Software Engineer (Reliability, Performance)
jobs.ashbyhq.com/feldera/544a...
jobs.ashbyhq.com/feldera/544a...
Reposted by Feldera

Some of my work at @feldera.bsky.social involves containers. I keep getting spam from some vendor who wants to sell me casters to put on the containers 🤣

September 2, 2025 at 3:22 PM
Some of my work at @feldera.bsky.social involves containers. I keep getting spam from some vendor who wants to sell me casters to put on the containers 🤣
"This is the true power of incremental compute. By only needing compute resources proportional to the size of the change, instead of the size of the whole dataset, businesses can dramatically slash compute spend for their analytics."
👇
www.feldera.com/blog/how-fel...
👇
www.feldera.com/blog/how-fel...

How Feldera Customers Slash Cloud Spend (10x and beyond)
By only needing compute resources proportional to the size of the change, instead of the size of the whole dataset, businesses can dramatically slash compute spend for their analytics.
www.feldera.com
August 20, 2025 at 5:01 PM
"This is the true power of incremental compute. By only needing compute resources proportional to the size of the change, instead of the size of the whole dataset, businesses can dramatically slash compute spend for their analytics."
👇
www.feldera.com/blog/how-fel...
👇
www.feldera.com/blog/how-fel...
Reposted by Feldera
At @feldera.bsky.social I've been doing a lot of performance work. I needed an easy way to watch the Prometheus metrics for a pipeline, so I wrote a simple tool for the Feldera CLI that shows the pipeline metrics. Here's the progress of a pipeline that runs in about 30 seconds.
August 20, 2025 at 12:27 AM
At @feldera.bsky.social I've been doing a lot of performance work. I needed an easy way to watch the Prometheus metrics for a pipeline, so I wrote a simple tool for the Feldera CLI that shows the pipeline metrics. Here's the progress of a pipeline that runs in about 30 seconds.
If you've written even the most basic compute program, you've likely already written programs that "integrate".
Integration is central to Feldera and its underlying theory of incremental compute. It is also all around us in the real world! 👇
Integration is central to Feldera and its underlying theory of incremental compute. It is also all around us in the real world! 👇

Stream Integration
In this blog post we informally introduce one core streaming operation: integration. We show that integration is a simple, useful, and fundamental stream processing primitive, which is used not only…
www.feldera.com
August 18, 2025 at 3:14 PM
If you've written even the most basic compute program, you've likely already written programs that "integrate".
Integration is central to Feldera and its underlying theory of incremental compute. It is also all around us in the real world! 👇
Integration is central to Feldera and its underlying theory of incremental compute. It is also all around us in the real world! 👇
"We chose performance over security" - a dilemma no data team should face.
#DataEngineering #DataSecurity #RealTimeAnalytics
#DataEngineering #DataSecurity #RealTimeAnalytics
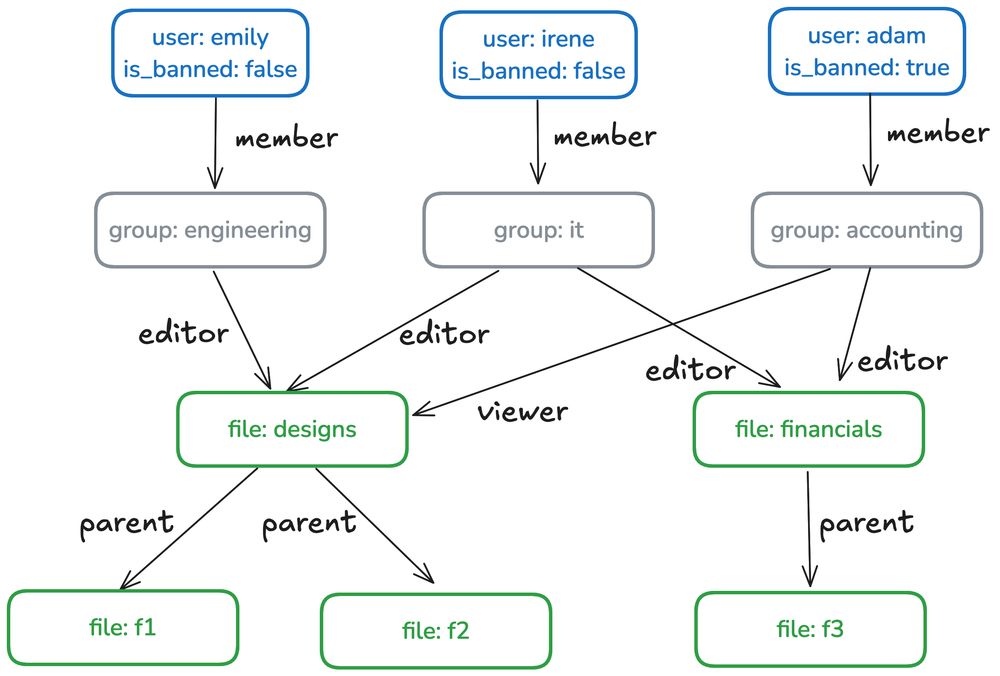
August 5, 2025 at 2:30 PM
"We chose performance over security" - a dilemma no data team should face.
#DataEngineering #DataSecurity #RealTimeAnalytics
#DataEngineering #DataSecurity #RealTimeAnalytics
New tech talk:
How to Incrementally Get Results from Your Graph Data with Feldera.
Interested in practical techniques for incremental computation or want to see how this fits into modern data engineering workflows?
Check it out: youtu.be/vpVAZbaZ2Hg
How to Incrementally Get Results from Your Graph Data with Feldera.
Interested in practical techniques for incremental computation or want to see how this fits into modern data engineering workflows?
Check it out: youtu.be/vpVAZbaZ2Hg

How to Incrementally Get Results from Your Graph Data with Feldera
YouTube video by Feldera, Inc.
youtu.be
June 18, 2025 at 7:47 PM
New tech talk:
How to Incrementally Get Results from Your Graph Data with Feldera.
Interested in practical techniques for incremental computation or want to see how this fits into modern data engineering workflows?
Check it out: youtu.be/vpVAZbaZ2Hg
How to Incrementally Get Results from Your Graph Data with Feldera.
Interested in practical techniques for incremental computation or want to see how this fits into modern data engineering workflows?
Check it out: youtu.be/vpVAZbaZ2Hg
Mihai Budiu, our exceptional Chief Scientist, won the 2025 #ACM #SIGCOMM Networking Systems Award for his groundbreaking work on #P4.
Details: www.sigcomm.org/awards/sigco...
Details: www.sigcomm.org/awards/sigco...
June 17, 2025 at 5:22 PM
Mihai Budiu, our exceptional Chief Scientist, won the 2025 #ACM #SIGCOMM Networking Systems Award for his groundbreaking work on #P4.
Details: www.sigcomm.org/awards/sigco...
Details: www.sigcomm.org/awards/sigco...
📢 Webinar - Tomorrow! -6/18 at 9am PST-
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
Sign Up - t.co/0iWPIMZY8C
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
Sign Up - t.co/0iWPIMZY8C

June 17, 2025 at 5:16 PM
📢 Webinar - Tomorrow! -6/18 at 9am PST-
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
Sign Up - t.co/0iWPIMZY8C
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
Sign Up - t.co/0iWPIMZY8C
Don't miss our webinar tomorrow! -6/18 at 9am PST-
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
tinyurl.com/rb5my7d8
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
tinyurl.com/rb5my7d8
How to Incrementally Get Results from Your Graph Data with Feldera
In this webinar, you'll learn how Feldera incrementally evaluates recursive graph computations.
tinyurl.com
June 17, 2025 at 5:11 PM
Don't miss our webinar tomorrow! -6/18 at 9am PST-
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
tinyurl.com/rb5my7d8
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations-ideal for real-time applications in authorization, networks, and observability.
tinyurl.com/rb5my7d8
📢 Webinar - 6/18 at 9am PST!
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations. Learn to easily build these mechanisms with #SQL, without the hassle of constant recomputation.
tinyurl.com/rb5my7d8
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations. Learn to easily build these mechanisms with #SQL, without the hassle of constant recomputation.
tinyurl.com/rb5my7d8

June 11, 2025 at 10:13 PM
📢 Webinar - 6/18 at 9am PST!
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations. Learn to easily build these mechanisms with #SQL, without the hassle of constant recomputation.
tinyurl.com/rb5my7d8
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations. Learn to easily build these mechanisms with #SQL, without the hassle of constant recomputation.
tinyurl.com/rb5my7d8
We’ll be at the #Databricks Data + AI Summit in SF next week (6/9–12).
If you’re around and want to chat about how incremental computing can make your #SparkSQL workloads go from hours to seconds — let’s connect.
Grab some time here: calendly.com/matt-feldera...
#DataAISummit #DataEngineering
If you’re around and want to chat about how incremental computing can make your #SparkSQL workloads go from hours to seconds — let’s connect.
Grab some time here: calendly.com/matt-feldera...
#DataAISummit #DataEngineering
June 5, 2025 at 8:47 PM
We’ll be at the #Databricks Data + AI Summit in SF next week (6/9–12).
If you’re around and want to chat about how incremental computing can make your #SparkSQL workloads go from hours to seconds — let’s connect.
Grab some time here: calendly.com/matt-feldera...
#DataAISummit #DataEngineering
If you’re around and want to chat about how incremental computing can make your #SparkSQL workloads go from hours to seconds — let’s connect.
Grab some time here: calendly.com/matt-feldera...
#DataAISummit #DataEngineering
Reposted by Feldera
Today, the USENIX newsletter ;login: published an interview with me: www.usenix.org/publications.... Read it to find out about Open vSwitch, @feldera.bsky.social, and more!

Interview with Ben Pfaff
www.usenix.org
May 22, 2025 at 10:58 PM
Today, the USENIX newsletter ;login: published an interview with me: www.usenix.org/publications.... Read it to find out about Open vSwitch, @feldera.bsky.social, and more!
🧵1/ Real-Time Medallion, No Re-Architecture Required.
A customer came to us with a classic Medallion setup: Spark + Delta Lake, batch jobs moving data from bronze to gold. It worked—until users started asking for fresher insights.
A customer came to us with a classic Medallion setup: Spark + Delta Lake, batch jobs moving data from bronze to gold. It worked—until users started asking for fresher insights.
May 28, 2025 at 11:33 PM
🧵1/ Real-Time Medallion, No Re-Architecture Required.
A customer came to us with a classic Medallion setup: Spark + Delta Lake, batch jobs moving data from bronze to gold. It worked—until users started asking for fresher insights.
A customer came to us with a classic Medallion setup: Spark + Delta Lake, batch jobs moving data from bronze to gold. It worked—until users started asking for fresher insights.
Feldera's Chief Scientist, Mihai Budiu will be giving a talk on the convergence between stream processing and databases at EventCentric in Antwerp on June 4: 2025.eventcentric.eu/program/unif...
EventCentric | For people who architect, build, and run event-driven systems | June 4-5EventCentric 2025 - Program
Non-vendor led conference on building event-driven systems. Antwerp, June 4-5 2025
2025.eventcentric.eu
May 22, 2025 at 4:06 AM
Feldera's Chief Scientist, Mihai Budiu will be giving a talk on the convergence between stream processing and databases at EventCentric in Antwerp on June 4: 2025.eventcentric.eu/program/unif...
Reposted by Feldera

It's a wonderful time to join us at @feldera.bsky.social! 🚀
If you're a systems engineer who loves working on data-intensive systems and is fluent in Rust, Kubernetes, Docker and cloud tech, do apply!
jobs.ashbyhq.com/feldera/9754...
If you're a systems engineer who loves working on data-intensive systems and is fluent in Rust, Kubernetes, Docker and cloud tech, do apply!
jobs.ashbyhq.com/feldera/9754...
Software Engineer: Cloud
Software Engineer: Cloud
jobs.ashbyhq.com
May 2, 2025 at 10:41 PM
It's a wonderful time to join us at @feldera.bsky.social! 🚀
If you're a systems engineer who loves working on data-intensive systems and is fluent in Rust, Kubernetes, Docker and cloud tech, do apply!
jobs.ashbyhq.com/feldera/9754...
If you're a systems engineer who loves working on data-intensive systems and is fluent in Rust, Kubernetes, Docker and cloud tech, do apply!
jobs.ashbyhq.com/feldera/9754...
Learn how to transform your slow batch jobs into real-time, always-up-to-date insights with our new user guide for converting Spark jobs to incremental Feldera pipelines.
www.feldera.com/blog/warpspeed
www.feldera.com/blog/warpspeed
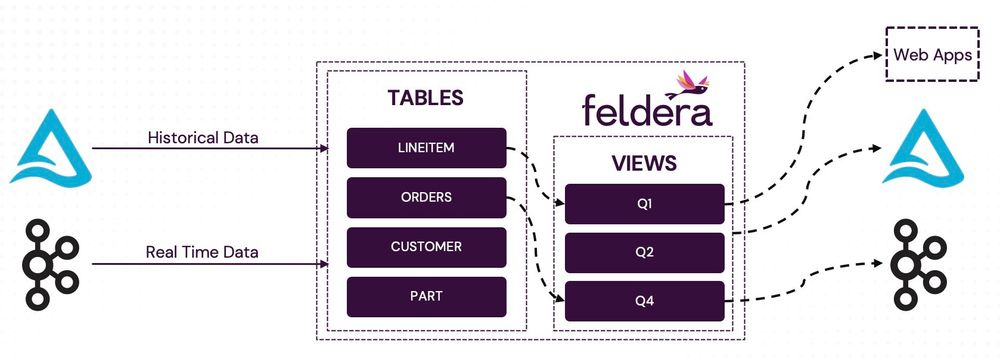
May 8, 2025 at 3:21 PM
Learn how to transform your slow batch jobs into real-time, always-up-to-date insights with our new user guide for converting Spark jobs to incremental Feldera pipelines.
www.feldera.com/blog/warpspeed
www.feldera.com/blog/warpspeed