



garreth
@garrethlee.bsky.social
🇮🇩 | Co-Founder at Mundo AI (YC W25) | ex-{Hugging Face, Cohere}
Pinned
garreth
@garrethlee.bsky.social
· Dec 16

🚀 With Meta's recent paper replacing tokenization in LLMs with patches 🩹, I figured that it's a great time to revisit how tokenization has evolved over the years using everyone's favourite medium - memes!
Let's take a trip down memory lane!
[1/N]
Let's take a trip down memory lane!
[1/N]
🚀 With Meta's recent paper replacing tokenization in LLMs with patches 🩹, I figured that it's a great time to revisit how tokenization has evolved over the years using everyone's favourite medium - memes!
Let's take a trip down memory lane!
[1/N]
Let's take a trip down memory lane!
[1/N]
December 16, 2024 at 5:31 PM
🚀 With Meta's recent paper replacing tokenization in LLMs with patches 🩹, I figured that it's a great time to revisit how tokenization has evolved over the years using everyone's favourite medium - memes!
Let's take a trip down memory lane!
[1/N]
Let's take a trip down memory lane!
[1/N]
Shouted out by the goat 🥹🤗

It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
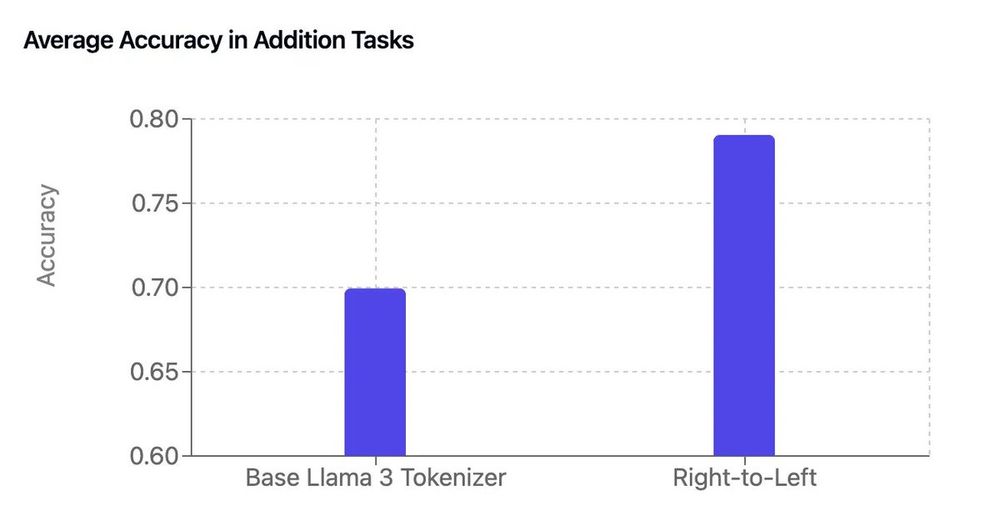
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
November 25, 2024 at 4:07 PM
Shouted out by the goat 🥹🤗
I made a simple CLI tool to write conventional git commit messages using the Hugging Face Inference API 🤗 (with some useful functionality baked into it)
➡️ To install: `pip install gcmt`
➡️ To install: `pip install gcmt`
November 25, 2024 at 4:31 AM
I made a simple CLI tool to write conventional git commit messages using the Hugging Face Inference API 🤗 (with some useful functionality baked into it)
➡️ To install: `pip install gcmt`
➡️ To install: `pip install gcmt`