



Ian Shi
@heyitsmeianshi.bsky.social
PhD Student @ University of Toronto
Building foundation models for genomics!
Building foundation models for genomics!
Pinned
Ian Shi
@heyitsmeianshi.bsky.social
· Jul 15
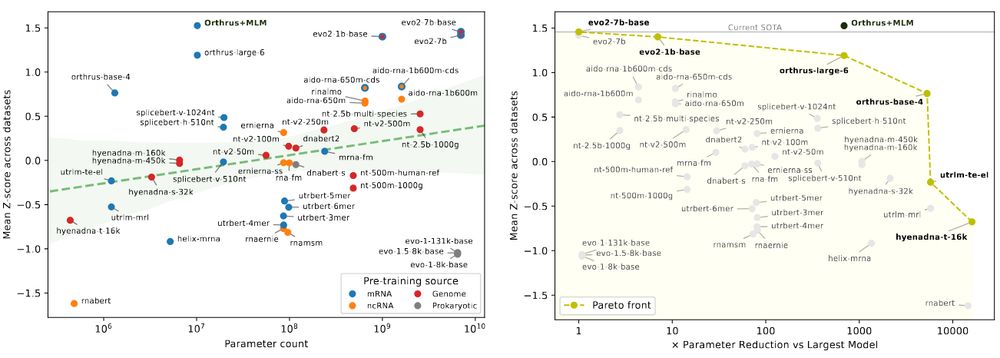
We're excited to release 𝐦𝐑𝐍𝐀𝐁𝐞𝐧𝐜𝐡, a new benchmark suite for mRNA biology containing 10 diverse datasets with 59 prediction tasks, evaluating 18 foundation model families.
Paper: biorxiv.org/content/10.1...
GitHub: github.com/morrislab/mR...
Blog: blank.bio/post/mrnabench
Paper: biorxiv.org/content/10.1...
GitHub: github.com/morrislab/mR...
Blog: blank.bio/post/mrnabench
We're excited to release 𝐦𝐑𝐍𝐀𝐁𝐞𝐧𝐜𝐡, a new benchmark suite for mRNA biology containing 10 diverse datasets with 59 prediction tasks, evaluating 18 foundation model families.
Paper: biorxiv.org/content/10.1...
GitHub: github.com/morrislab/mR...
Blog: blank.bio/post/mrnabench
Paper: biorxiv.org/content/10.1...
GitHub: github.com/morrislab/mR...
Blog: blank.bio/post/mrnabench
July 15, 2025 at 6:41 PM
We're excited to release 𝐦𝐑𝐍𝐀𝐁𝐞𝐧𝐜𝐡, a new benchmark suite for mRNA biology containing 10 diverse datasets with 59 prediction tasks, evaluating 18 foundation model families.
Paper: biorxiv.org/content/10.1...
GitHub: github.com/morrislab/mR...
Blog: blank.bio/post/mrnabench
Paper: biorxiv.org/content/10.1...
GitHub: github.com/morrislab/mR...
Blog: blank.bio/post/mrnabench