



@hochreitersepp.bsky.social
xLSTM for Real-Time DNS Tunnel Detection: arxiv.org/abs/2512.09565
DNS-HyXNet = xLSTM for DNS tunnels.
DNS-HyXNet has 99.99% accuracy, with F1-scores exceeding 99.96%, and per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. wow!
DNS-HyXNet = xLSTM for DNS tunnels.
DNS-HyXNet has 99.99% accuracy, with F1-scores exceeding 99.96%, and per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. wow!

December 11, 2025 at 11:18 AM
xLSTM for Real-Time DNS Tunnel Detection: arxiv.org/abs/2512.09565
DNS-HyXNet = xLSTM for DNS tunnels.
DNS-HyXNet has 99.99% accuracy, with F1-scores exceeding 99.96%, and per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. wow!
DNS-HyXNet = xLSTM for DNS tunnels.
DNS-HyXNet has 99.99% accuracy, with F1-scores exceeding 99.96%, and per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. wow!
xLSTM for PINNs that learn PDEs: arxiv.org/abs/2511.12512
“Across four PDEs under matched size and budget, xLSTM-PINN consistently reduces MSE, RMSE, MAE, and MaxAE with markedly narrower error bands.”
“cleaner boundary transitions with attenuated high-frequency ripples”
“Across four PDEs under matched size and budget, xLSTM-PINN consistently reduces MSE, RMSE, MAE, and MaxAE with markedly narrower error bands.”
“cleaner boundary transitions with attenuated high-frequency ripples”


November 20, 2025 at 1:20 PM
xLSTM for PINNs that learn PDEs: arxiv.org/abs/2511.12512
“Across four PDEs under matched size and budget, xLSTM-PINN consistently reduces MSE, RMSE, MAE, and MaxAE with markedly narrower error bands.”
“cleaner boundary transitions with attenuated high-frequency ripples”
“Across four PDEs under matched size and budget, xLSTM-PINN consistently reduces MSE, RMSE, MAE, and MaxAE with markedly narrower error bands.”
“cleaner boundary transitions with attenuated high-frequency ripples”
Reposted

Measuring AI Progress in Drug Discovery - A NEW LEADERBOARD IN TOWN
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744

November 19, 2025 at 6:52 AM
Measuring AI Progress in Drug Discovery - A NEW LEADERBOARD IN TOWN
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744
xLSTM for Vehicle Trajectory Prediction: arxiv.org/abs/2511.00266
X-TRACK based on xLSTM achieves SOTA.
“Compared to state-of-the-art baselines, X-TRACK achieves performance improvement by 79% at the 1-second prediction and 20% at the 5-second prediction in the case of highD”
Again xLSTM excels.
X-TRACK based on xLSTM achieves SOTA.
“Compared to state-of-the-art baselines, X-TRACK achieves performance improvement by 79% at the 1-second prediction and 20% at the 5-second prediction in the case of highD”
Again xLSTM excels.


November 4, 2025 at 12:44 PM
xLSTM for Vehicle Trajectory Prediction: arxiv.org/abs/2511.00266
X-TRACK based on xLSTM achieves SOTA.
“Compared to state-of-the-art baselines, X-TRACK achieves performance improvement by 79% at the 1-second prediction and 20% at the 5-second prediction in the case of highD”
Again xLSTM excels.
X-TRACK based on xLSTM achieves SOTA.
“Compared to state-of-the-art baselines, X-TRACK achieves performance improvement by 79% at the 1-second prediction and 20% at the 5-second prediction in the case of highD”
Again xLSTM excels.
xLSTM for robotic manipulation systems via diffusion-based imitation learning: arxiv.org/abs/2510.20406
PMP leverages xLSTM to denoise actions for robotics.
“PMP not only achieves state-of-the-art performance but also offers significantly faster training and inference.”
xLSTM excels in robotics.
PMP leverages xLSTM to denoise actions for robotics.
“PMP not only achieves state-of-the-art performance but also offers significantly faster training and inference.”
xLSTM excels in robotics.

October 26, 2025 at 5:22 PM
xLSTM for robotic manipulation systems via diffusion-based imitation learning: arxiv.org/abs/2510.20406
PMP leverages xLSTM to denoise actions for robotics.
“PMP not only achieves state-of-the-art performance but also offers significantly faster training and inference.”
xLSTM excels in robotics.
PMP leverages xLSTM to denoise actions for robotics.
“PMP not only achieves state-of-the-art performance but also offers significantly faster training and inference.”
xLSTM excels in robotics.
Tenure Track in quantum informatics! Super cool position. Super cool team. World-class research. Scientifically outstanding work.

(I/III) We're excited to announce a new tenure track opening! The position is called 'quantum informatics' and is affiliated with our QUICK group within the CS+AI division at @jku.at 🇦🇹. Application deadline is November 30th, 2025: www.jku.at/en/the-jku/w...

October 22, 2025 at 7:36 AM
Tenure Track in quantum informatics! Super cool position. Super cool team. World-class research. Scientifically outstanding work.
xLSTM for Toxic Comment Classification: arxiv.org/abs/2510.17018
“On the Jigsaw Toxic Comment benchmark, xLSTM attains 96.0% accuracy and 0.88 macro-F1, outperforming BERT by 33% on threat and 28% on identity_hate categories, with 15× fewer parameters and <50 ms inference latency.”
xLSTM is fast!
“On the Jigsaw Toxic Comment benchmark, xLSTM attains 96.0% accuracy and 0.88 macro-F1, outperforming BERT by 33% on threat and 28% on identity_hate categories, with 15× fewer parameters and <50 ms inference latency.”
xLSTM is fast!


October 21, 2025 at 5:19 AM
xLSTM for Toxic Comment Classification: arxiv.org/abs/2510.17018
“On the Jigsaw Toxic Comment benchmark, xLSTM attains 96.0% accuracy and 0.88 macro-F1, outperforming BERT by 33% on threat and 28% on identity_hate categories, with 15× fewer parameters and <50 ms inference latency.”
xLSTM is fast!
“On the Jigsaw Toxic Comment benchmark, xLSTM attains 96.0% accuracy and 0.88 macro-F1, outperforming BERT by 33% on threat and 28% on identity_hate categories, with 15× fewer parameters and <50 ms inference latency.”
xLSTM is fast!
gLSTM extends xLSTM to a graph neural network architecture: arxiv.org/abs/2510.08450
"gLSTM mitigates sensitivity over-squashing and capacity over-squashing."
"gLSTM achieves comfortably state of the art results on the Diameter and Eccentricity Graph Property Prediction tasks"
"gLSTM mitigates sensitivity over-squashing and capacity over-squashing."
"gLSTM achieves comfortably state of the art results on the Diameter and Eccentricity Graph Property Prediction tasks"

October 10, 2025 at 12:13 PM
gLSTM extends xLSTM to a graph neural network architecture: arxiv.org/abs/2510.08450
"gLSTM mitigates sensitivity over-squashing and capacity over-squashing."
"gLSTM achieves comfortably state of the art results on the Diameter and Eccentricity Graph Property Prediction tasks"
"gLSTM mitigates sensitivity over-squashing and capacity over-squashing."
"gLSTM achieves comfortably state of the art results on the Diameter and Eccentricity Graph Property Prediction tasks"
xLSTM for Intrusion Detection: arxiv.org/abs/2510.08333
"The xLSTM-based IDS achieves an F1-score of 98.9%, surpassing the transformer-based model at 94.3%."
xLSTM is faster than transformer when using fast kernels as provided in github.com/nx-ai/mlstm_... and github.com/NX-AI/flashrnn
"The xLSTM-based IDS achieves an F1-score of 98.9%, surpassing the transformer-based model at 94.3%."
xLSTM is faster than transformer when using fast kernels as provided in github.com/nx-ai/mlstm_... and github.com/NX-AI/flashrnn



October 10, 2025 at 8:54 AM
xLSTM for Intrusion Detection: arxiv.org/abs/2510.08333
"The xLSTM-based IDS achieves an F1-score of 98.9%, surpassing the transformer-based model at 94.3%."
xLSTM is faster than transformer when using fast kernels as provided in github.com/nx-ai/mlstm_... and github.com/NX-AI/flashrnn
"The xLSTM-based IDS achieves an F1-score of 98.9%, surpassing the transformer-based model at 94.3%."
xLSTM is faster than transformer when using fast kernels as provided in github.com/nx-ai/mlstm_... and github.com/NX-AI/flashrnn
xLSTM for long-term context using short sliding windows: arxiv.org/abs/2509.24552
"SWAX, a hybrid consisting of sliding-window attention and xLSTM."
"SWAX trained with stochastic window sizes significantly outperforms regular window attention both on short and long-context problems."
"SWAX, a hybrid consisting of sliding-window attention and xLSTM."
"SWAX trained with stochastic window sizes significantly outperforms regular window attention both on short and long-context problems."

September 30, 2025 at 5:18 AM
xLSTM for long-term context using short sliding windows: arxiv.org/abs/2509.24552
"SWAX, a hybrid consisting of sliding-window attention and xLSTM."
"SWAX trained with stochastic window sizes significantly outperforms regular window attention both on short and long-context problems."
"SWAX, a hybrid consisting of sliding-window attention and xLSTM."
"SWAX trained with stochastic window sizes significantly outperforms regular window attention both on short and long-context problems."
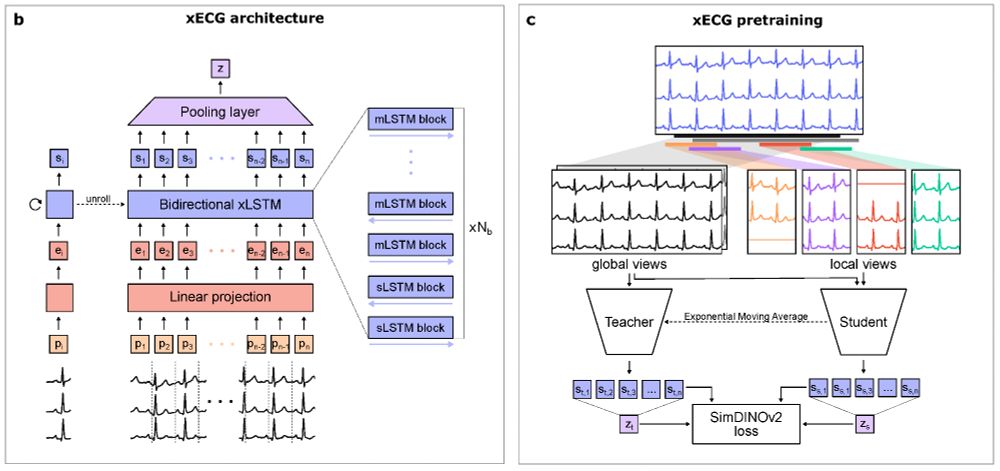
xLSTM shines as an Electrocardiogram (ECG) foundation model: arxiv.org/abs/2509.10151
"xECG achieves superior performance over earlier approaches, defining a new baseline for future ECG foundation models."
xLSTM is perfectly suited for time series prediction as shown by TiRex.
"xECG achieves superior performance over earlier approaches, defining a new baseline for future ECG foundation models."
xLSTM is perfectly suited for time series prediction as shown by TiRex.

September 16, 2025 at 5:20 AM
xLSTM shines as an Electrocardiogram (ECG) foundation model: arxiv.org/abs/2509.10151
"xECG achieves superior performance over earlier approaches, defining a new baseline for future ECG foundation models."
xLSTM is perfectly suited for time series prediction as shown by TiRex.
"xECG achieves superior performance over earlier approaches, defining a new baseline for future ECG foundation models."
xLSTM is perfectly suited for time series prediction as shown by TiRex.
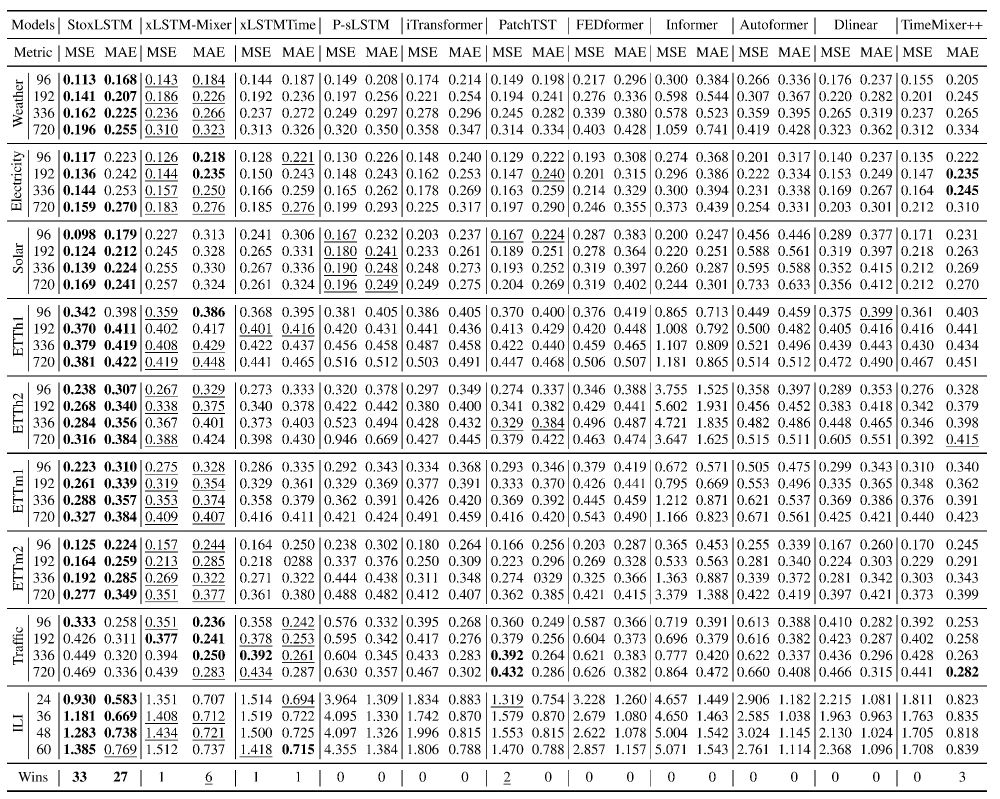
xLSTM excels in time series forecasting: arxiv.org/abs/2509.01187 .
Introduces "stochastic xLSTM" (StoxLSTM).
"StoxLSTM consistently outperforms state-of-the-art baselines with better robustness and stronger generalization ability."
We know that xLSTM is king at time series from our TiRex.
Introduces "stochastic xLSTM" (StoxLSTM).
"StoxLSTM consistently outperforms state-of-the-art baselines with better robustness and stronger generalization ability."
We know that xLSTM is king at time series from our TiRex.


September 3, 2025 at 5:38 AM
xLSTM excels in time series forecasting: arxiv.org/abs/2509.01187 .
Introduces "stochastic xLSTM" (StoxLSTM).
"StoxLSTM consistently outperforms state-of-the-art baselines with better robustness and stronger generalization ability."
We know that xLSTM is king at time series from our TiRex.
Introduces "stochastic xLSTM" (StoxLSTM).
"StoxLSTM consistently outperforms state-of-the-art baselines with better robustness and stronger generalization ability."
We know that xLSTM is king at time series from our TiRex.
xLSTM for Cellular Traffic Forecasting: arxiv.org/abs/2507.19513
"Empirical results showed a 23% MAE reduction over the original STN and a 30% improvement on unseen data, highlighting strong generalization."
xLSTM shines again in time series forecasting.
"Empirical results showed a 23% MAE reduction over the original STN and a 30% improvement on unseen data, highlighting strong generalization."
xLSTM shines again in time series forecasting.

July 29, 2025 at 5:02 AM
xLSTM for Cellular Traffic Forecasting: arxiv.org/abs/2507.19513
"Empirical results showed a 23% MAE reduction over the original STN and a 30% improvement on unseen data, highlighting strong generalization."
xLSTM shines again in time series forecasting.
"Empirical results showed a 23% MAE reduction over the original STN and a 30% improvement on unseen data, highlighting strong generalization."
xLSTM shines again in time series forecasting.
xLSTM for Monaural Speech Enhancement: arxiv.org/abs/2507.04368
xLSTM has superior performance vs. Mamba and Transformers but is slower than Mamba.
New Triton kernels: xLSTM is faster than MAMBA at training and inference: arxiv.org/abs/2503.13427 and arxiv.org/abs/2503.14376
xLSTM has superior performance vs. Mamba and Transformers but is slower than Mamba.
New Triton kernels: xLSTM is faster than MAMBA at training and inference: arxiv.org/abs/2503.13427 and arxiv.org/abs/2503.14376


July 8, 2025 at 5:48 AM
xLSTM for Monaural Speech Enhancement: arxiv.org/abs/2507.04368
xLSTM has superior performance vs. Mamba and Transformers but is slower than Mamba.
New Triton kernels: xLSTM is faster than MAMBA at training and inference: arxiv.org/abs/2503.13427 and arxiv.org/abs/2503.14376
xLSTM has superior performance vs. Mamba and Transformers but is slower than Mamba.
New Triton kernels: xLSTM is faster than MAMBA at training and inference: arxiv.org/abs/2503.13427 and arxiv.org/abs/2503.14376
xLSTM for Aspect-based Sentiment Analysis: arxiv.org/abs/2507.01213
Another success story of xLSTM. MEGA: xLSTM with Multihead Exponential Gated Fusion.
Experiments on 3 benchmarks show that MEGA outperforms state-of-the-art baselines with superior accuracy and efficiency”
Another success story of xLSTM. MEGA: xLSTM with Multihead Exponential Gated Fusion.
Experiments on 3 benchmarks show that MEGA outperforms state-of-the-art baselines with superior accuracy and efficiency”

July 5, 2025 at 10:28 AM
xLSTM for Aspect-based Sentiment Analysis: arxiv.org/abs/2507.01213
Another success story of xLSTM. MEGA: xLSTM with Multihead Exponential Gated Fusion.
Experiments on 3 benchmarks show that MEGA outperforms state-of-the-art baselines with superior accuracy and efficiency”
Another success story of xLSTM. MEGA: xLSTM with Multihead Exponential Gated Fusion.
Experiments on 3 benchmarks show that MEGA outperforms state-of-the-art baselines with superior accuracy and efficiency”
xLSTM for multivariate time series anomaly detection: arxiv.org/abs/2506.22837
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.

July 1, 2025 at 8:30 AM
xLSTM for multivariate time series anomaly detection: arxiv.org/abs/2506.22837
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.
xLSTM for Human Action Segmentation: arxiv.org/abs/2506.09650
"HopaDIFF, leveraging a novel cross-input gate attentional xLSTM to enhance holistic-partial long-range reasoning"
"HopaDIFF achieves state-of-theart results on RHAS133 in diverse evaluation settings."
"HopaDIFF, leveraging a novel cross-input gate attentional xLSTM to enhance holistic-partial long-range reasoning"
"HopaDIFF achieves state-of-theart results on RHAS133 in diverse evaluation settings."

June 12, 2025 at 7:48 AM
xLSTM for Human Action Segmentation: arxiv.org/abs/2506.09650
"HopaDIFF, leveraging a novel cross-input gate attentional xLSTM to enhance holistic-partial long-range reasoning"
"HopaDIFF achieves state-of-theart results on RHAS133 in diverse evaluation settings."
"HopaDIFF, leveraging a novel cross-input gate attentional xLSTM to enhance holistic-partial long-range reasoning"
"HopaDIFF achieves state-of-theart results on RHAS133 in diverse evaluation settings."
Mein Buch “Was kann Künstliche Intelligenz?“ ist erschienen. Eine leicht zugängliche Einführung in das Thema Künstliche Intelligenz. LeserInnen – auch ohne technischen Hintergrund – wird erklärt, was KI eigentlich ist, welche Potenziale sie birgt und welche Auswirkungen sie hat.

June 4, 2025 at 5:13 PM
Mein Buch “Was kann Künstliche Intelligenz?“ ist erschienen. Eine leicht zugängliche Einführung in das Thema Künstliche Intelligenz. LeserInnen – auch ohne technischen Hintergrund – wird erklärt, was KI eigentlich ist, welche Potenziale sie birgt und welche Auswirkungen sie hat.
We are soooo proud. Our European-developed TiRex is leading the field—significantly ahead of U.S. competitors like Amazon, Datadog, Salesforce, and Google, as well as Chinese models from companies such as Alibaba.

Ever though you could get a 35 million parameter time series state-of-the art foundation model that you can run on embedded hardware? Thanks to @hochreitersepp.bsky.social and his team at NXAI, you can. Amazing work!
Paper: arxiv.org/abs/2505.23719
Code: github.com/NX-AI/tirex
Paper: arxiv.org/abs/2505.23719
Code: github.com/NX-AI/tirex

TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In-Context Learning
In-context learning, the ability of large language models to perform tasks using only examples provided in the prompt, has recently been adapted for time series forecasting. This paradigm enables zero...
arxiv.org
June 4, 2025 at 8:59 AM
We are soooo proud. Our European-developed TiRex is leading the field—significantly ahead of U.S. competitors like Amazon, Datadog, Salesforce, and Google, as well as Chinese models from companies such as Alibaba.
Attention!! Our TiRex time series model, built on xLSTM, is topping all major international leaderboards. A European-developed model is leading the field—significantly ahead of U.S. competitors like Amazon, Datadog, Salesforce, and Google, as well as Chinese models from Alibaba.
Ever though you could get a 35 million parameter time series state-of-the art foundation model that you can run on embedded hardware? Thanks to @hochreitersepp.bsky.social and his team at NXAI, you can. Amazing work!
Paper: arxiv.org/abs/2505.23719
Code: github.com/NX-AI/tirex
Paper: arxiv.org/abs/2505.23719
Code: github.com/NX-AI/tirex
TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In-Context Learning
In-context learning, the ability of large language models to perform tasks using only examples provided in the prompt, has recently been adapted for time series forecasting. This paradigm enables zero...
arxiv.org
June 2, 2025 at 12:12 PM
Attention!! Our TiRex time series model, built on xLSTM, is topping all major international leaderboards. A European-developed model is leading the field—significantly ahead of U.S. competitors like Amazon, Datadog, Salesforce, and Google, as well as Chinese models from Alibaba.
TiRex 🦖 time series xLSTM model ranked #1 on all leaderboards.
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq

Introducing TiRex - xLSTM based time series model | NXAI
TiRex model at the top 🦖
We are proud of TiRex - our first time series model based on #xLSTM technology.
Key take aways:
🥇 Ranked #1 on official international leaderboards
➡️ Outperforms models ...
www.linkedin.com
June 2, 2025 at 12:12 PM
TiRex 🦖 time series xLSTM model ranked #1 on all leaderboards.
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq
Reposted
Recommended read for the weekend: Sepp Hochreiter's book on AI!
Lots of fun anecdotes and easily accessible basics on AI!
www.beneventopublishing.com/ecowing/prod...
Lots of fun anecdotes and easily accessible basics on AI!
www.beneventopublishing.com/ecowing/prod...

May 30, 2025 at 12:28 PM
Recommended read for the weekend: Sepp Hochreiter's book on AI!
Lots of fun anecdotes and easily accessible basics on AI!
www.beneventopublishing.com/ecowing/prod...
Lots of fun anecdotes and easily accessible basics on AI!
www.beneventopublishing.com/ecowing/prod...
xLSTM for the classification of assembly tasks: arxiv.org/abs/2505.18012
"xLSTM model demonstrated better generalization capabilities to new operators. The results clearly show that for this type of classification, the xLSTM model offers a slight edge over Transformers."
"xLSTM model demonstrated better generalization capabilities to new operators. The results clearly show that for this type of classification, the xLSTM model offers a slight edge over Transformers."

May 26, 2025 at 5:07 AM
xLSTM for the classification of assembly tasks: arxiv.org/abs/2505.18012
"xLSTM model demonstrated better generalization capabilities to new operators. The results clearly show that for this type of classification, the xLSTM model offers a slight edge over Transformers."
"xLSTM model demonstrated better generalization capabilities to new operators. The results clearly show that for this type of classification, the xLSTM model offers a slight edge over Transformers."
Reposted

Happy to introduce 🔥LaM-SLidE🔥!
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n

May 22, 2025 at 12:24 PM
Happy to introduce 🔥LaM-SLidE🔥!
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
Reposted

1/11 Excited to present our latest work "Scalable Discrete Diffusion Samplers: Combinatorial Optimization and Statistical Physics" at #ICLR2025 on Fri 25 Apr at 10 am!
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels

April 24, 2025 at 8:57 AM
1/11 Excited to present our latest work "Scalable Discrete Diffusion Samplers: Combinatorial Optimization and Statistical Physics" at #ICLR2025 on Fri 25 Apr at 10 am!
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels