




Stephanie Hyland
@hylandsl.bsky.social
machine learning for health at microsoft research, based in cambridge UK 🌻 she/her
found a file from PhD days with the FORTY-EIGHT ways "ACE inhibitor" was encoded in the EHR system we were working wth
November 23, 2025 at 5:04 PM
found a file from PhD days with the FORTY-EIGHT ways "ACE inhibitor" was encoded in the EHR system we were working wth
finally got around to booking my travel for #EurIPS2025! Looking forward to connecting with the European ML scene in Copenhagen
November 16, 2025 at 5:17 PM
finally got around to booking my travel for #EurIPS2025! Looking forward to connecting with the European ML scene in Copenhagen
uv is so good
uv is now stable enough that I'm switching my course over to using it. No more conda, we will create a generation of uv evangelicals
September 21, 2025 at 10:25 PM
uv is so good
Reposted by Stephanie Hyland

Some papers really have a good intro

September 10, 2025 at 9:26 PM
Some papers really have a good intro
Reposted by Stephanie Hyland

The more rigorous peer review happens in conversations and reading groups after the paper is out with reputational costs for publishing bad work
August 17, 2025 at 4:12 PM
The more rigorous peer review happens in conversations and reading groups after the paper is out with reputational costs for publishing bad work
Reposted by Stephanie Hyland

I'll admit, I was skeptical when they said Gemini was just like a bunch of PhDs. But I gotta admit they nailed it.

August 17, 2025 at 1:51 PM
I'll admit, I was skeptical when they said Gemini was just like a bunch of PhDs. But I gotta admit they nailed it.
what is the purpose of VQA datasets where text-only models do better than random?
August 14, 2025 at 2:08 PM
what is the purpose of VQA datasets where text-only models do better than random?

Reposted by Stephanie Hyland

quick diagram of Bluesky’s architecture and why it’s nicer here
August 2, 2025 at 11:19 PM
quick diagram of Bluesky’s architecture and why it’s nicer here
it's frustrating how inefficient review assignments are: we target a minimum number of completed reviews per paper but in accounting for inevitable no-shows, some people end up doing technically unnecessary (if still beneficial) reviews
July 30, 2025 at 4:23 PM
it's frustrating how inefficient review assignments are: we target a minimum number of completed reviews per paper but in accounting for inevitable no-shows, some people end up doing technically unnecessary (if still beneficial) reviews
New work from my team! arxiv.org/abs/2507.12950
Intersecting mechanistic interpretability and health AI 😎
We trained and interpreted sparse autoencoders on MAIRA-2, our radiology MLLM. We found a range of human-interpretable radiology reporting concepts, but also many uninterpretable SAE features.
Intersecting mechanistic interpretability and health AI 😎
We trained and interpreted sparse autoencoders on MAIRA-2, our radiology MLLM. We found a range of human-interpretable radiology reporting concepts, but also many uninterpretable SAE features.

Insights into a radiology-specialised multimodal large language model with sparse autoencoders
Interpretability can improve the safety, transparency and trust of AI models, which is especially important in healthcare applications where decisions often carry significant consequences. Mechanistic...
arxiv.org
July 18, 2025 at 9:30 AM
New work from my team! arxiv.org/abs/2507.12950
Intersecting mechanistic interpretability and health AI 😎
We trained and interpreted sparse autoencoders on MAIRA-2, our radiology MLLM. We found a range of human-interpretable radiology reporting concepts, but also many uninterpretable SAE features.
Intersecting mechanistic interpretability and health AI 😎
We trained and interpreted sparse autoencoders on MAIRA-2, our radiology MLLM. We found a range of human-interpretable radiology reporting concepts, but also many uninterpretable SAE features.
Reposted by Stephanie Hyland

We're excited to announce a second physical location for NeurIPS 2025, in Mexico City, which we hope will address concerns around skyrocketing attendance and difficulties in travel visas that some attendees have experienced in previous years.
Read more in our blog:
blog.neurips.cc/2025/07/16/n...
Read more in our blog:
blog.neurips.cc/2025/07/16/n...
July 16, 2025 at 10:05 PM
We're excited to announce a second physical location for NeurIPS 2025, in Mexico City, which we hope will address concerns around skyrocketing attendance and difficulties in travel visas that some attendees have experienced in previous years.
Read more in our blog:
blog.neurips.cc/2025/07/16/n...
Read more in our blog:
blog.neurips.cc/2025/07/16/n...
Reposted by Stephanie Hyland

During the last couple of years, we have read a lot of papers on explainability and often felt that something was fundamentally missing🤔
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵

July 10, 2025 at 5:58 PM
During the last couple of years, we have read a lot of papers on explainability and often felt that something was fundamentally missing🤔
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵
Reposted by Stephanie Hyland

ExplainableAI has long frustrated me by lacking a clear theory of what an explanation should do. Improve use of a model for what? How? Given a task what's max effect explanation could have? It's complicated bc most methods are functions of features & prediction but not true state being predicted 1/
July 2, 2025 at 4:53 PM
ExplainableAI has long frustrated me by lacking a clear theory of what an explanation should do. Improve use of a model for what? How? Given a task what's max effect explanation could have? It's complicated bc most methods are functions of features & prediction but not true state being predicted 1/
Reposted by Stephanie Hyland

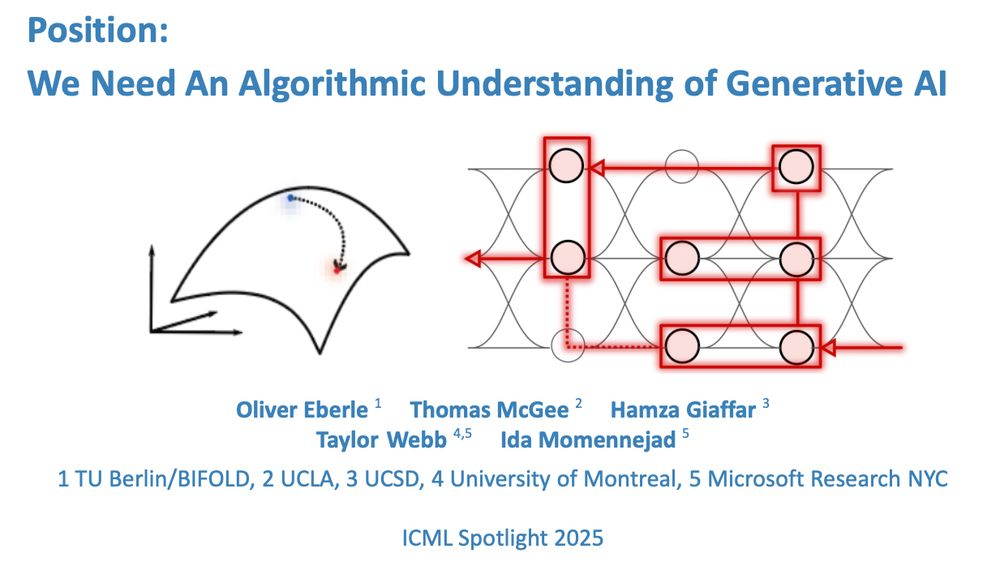
Pleased to share our ICML Spotlight with @eberleoliver.bsky.social, Thomas McGee, Hamza Giaffar, @taylorwwebb.bsky.social.
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
June 20, 2025 at 3:48 PM
Pleased to share our ICML Spotlight with @eberleoliver.bsky.social, Thomas McGee, Hamza Giaffar, @taylorwwebb.bsky.social.
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
This is cool arxiv.org/abs/2505.18235.
Linear representation hypothesis discourse needs more differential geometry i m o
Linear representation hypothesis discourse needs more differential geometry i m o
The Origins of Representation Manifolds in Large Language Models
There is a large ongoing scientific effort in mechanistic interpretability to map embeddings and internal representations of AI systems into human-understandable concepts. A key element of this effort...
arxiv.org
June 27, 2025 at 10:07 AM
This is cool arxiv.org/abs/2505.18235.
Linear representation hypothesis discourse needs more differential geometry i m o
Linear representation hypothesis discourse needs more differential geometry i m o
Reposted by Stephanie Hyland

🚀 After two+ years of intense research, we’re thrilled to introduce Skala — a scalable deep learning density functional that hits chemical accuracy on atomization energies and matches hybrid-level accuracy on main group chemistry — all at the cost of semi-local DFT ⚛️🔥🧪🧬
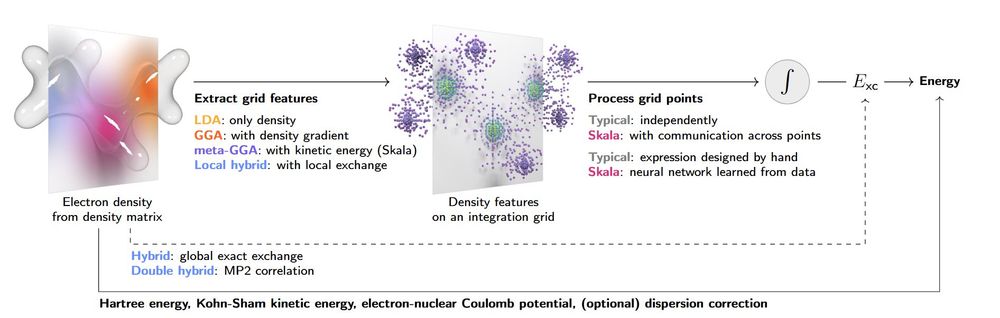
June 18, 2025 at 11:24 AM
🚀 After two+ years of intense research, we’re thrilled to introduce Skala — a scalable deep learning density functional that hits chemical accuracy on atomization energies and matches hybrid-level accuracy on main group chemistry — all at the cost of semi-local DFT ⚛️🔥🧪🧬
Limited time offer: I get an email every time someone fills in this form, so act now to add to the chaos of my inbox before I figure out how to turn this off
June 18, 2025 at 4:16 PM
Limited time offer: I get an email every time someone fills in this form, so act now to add to the chaos of my inbox before I figure out how to turn this off
A strange thing about living near Duxford is having WW2-era planes flying overhead on a regular basis.
June 15, 2025 at 10:59 AM
A strange thing about living near Duxford is having WW2-era planes flying overhead on a regular basis.
Reposted by Stephanie Hyland

90% of doing science is being open to new ideas.

May 31, 2025 at 6:14 PM
90% of doing science is being open to new ideas.
Reposted by Stephanie Hyland

I am disappointed in the AI discourse steveklabnik.com/writing/i-am...
I am disappointed in the AI discourse
steveklabnik.com
May 28, 2025 at 5:33 PM
I am disappointed in the AI discourse steveklabnik.com/writing/i-am...
Reposted by Stephanie Hyland

What happens in SAIL 2025 stays in SAIL 2025 -- except for these anonymized hot takes! 🔥 Jotted down 17 de-identified quotes on AI and medicine from medical executives, journal editors, and academics in off-the-record discussions in Puerto Rico
irenechen.net/sail2025/
irenechen.net/sail2025/

May 12, 2025 at 2:02 PM
What happens in SAIL 2025 stays in SAIL 2025 -- except for these anonymized hot takes! 🔥 Jotted down 17 de-identified quotes on AI and medicine from medical executives, journal editors, and academics in off-the-record discussions in Puerto Rico
irenechen.net/sail2025/
irenechen.net/sail2025/
Reposted by Stephanie Hyland

Registration is now open for #CHIL2025! This year's program will feature
🔹Keynote presentations
🔹Panel discussions
🔹Year in Review
🔹Posters sessions
🔹Doctoral Symposium lightning talks
👉 Schedule: chil.ahli.cc/attend/sched...
👉 Register: ahli.cc/chil25-regis...
🔹Keynote presentations
🔹Panel discussions
🔹Year in Review
🔹Posters sessions
🔹Doctoral Symposium lightning talks
👉 Schedule: chil.ahli.cc/attend/sched...
👉 Register: ahli.cc/chil25-regis...

May 3, 2025 at 12:31 PM
Registration is now open for #CHIL2025! This year's program will feature
🔹Keynote presentations
🔹Panel discussions
🔹Year in Review
🔹Posters sessions
🔹Doctoral Symposium lightning talks
👉 Schedule: chil.ahli.cc/attend/sched...
👉 Register: ahli.cc/chil25-regis...
🔹Keynote presentations
🔹Panel discussions
🔹Year in Review
🔹Posters sessions
🔹Doctoral Symposium lightning talks
👉 Schedule: chil.ahli.cc/attend/sched...
👉 Register: ahli.cc/chil25-regis...
Reposted by Stephanie Hyland

I wrote something up for AI people who want to get into bluesky and either couldn't assemble an exciting feed or gave up doomscrolling when their Following feed switched to talking politics 24/7.

The AI Researcher's Guide to a Non-Boring Bluesky Feed | Naomi Saphra
How to migrate to bsky without a boring feed.
nsaphra.net
April 26, 2025 at 1:31 AM
I wrote something up for AI people who want to get into bluesky and either couldn't assemble an exciting feed or gave up doomscrolling when their Following feed switched to talking politics 24/7.