



Janu Verma
@januverma.bsky.social
Principal Applied Scientist, Microsoft.
Interested in AI, RecSys, Maths.
Trains and fine-tunes models.
januverma.substack.com
Interested in AI, RecSys, Maths.
Trains and fine-tunes models.
januverma.substack.com
New work: Multi-turn tool use using RL
Link: open.substack.com/pub/januverm...
Link: open.substack.com/pub/januverm...

Multi-Turn Tool Use with RL
Think → Code → Check → Answer
open.substack.com
November 4, 2025 at 3:06 PM
New work: Multi-turn tool use using RL
Link: open.substack.com/pub/januverm...
Link: open.substack.com/pub/januverm...
Add. Related. Context.
Often, the most significant performance gains come from enriching models with related, contextual info. Models get better by being exposed to auxiliary signals that deepen their understanding of the task.
Often, the most significant performance gains come from enriching models with related, contextual info. Models get better by being exposed to auxiliary signals that deepen their understanding of the task.
July 11, 2025 at 12:23 PM
Add. Related. Context.
Often, the most significant performance gains come from enriching models with related, contextual info. Models get better by being exposed to auxiliary signals that deepen their understanding of the task.
Often, the most significant performance gains come from enriching models with related, contextual info. Models get better by being exposed to auxiliary signals that deepen their understanding of the task.
My latest blog post dives into the protein folding problem - a fundamental question in molecular biology that puzzled scientists for decades, until deep learning models like AlphaFold changed the game. I walk through the biological and computational roots of the problem.

July 9, 2025 at 10:16 AM
My latest blog post dives into the protein folding problem - a fundamental question in molecular biology that puzzled scientists for decades, until deep learning models like AlphaFold changed the game. I walk through the biological and computational roots of the problem.
As a personal research project, I’m exploring the efficacy of LLMs for Recommendation System tasks. Check out my experments at januverma.substack.com

Incomplete Distillation | Janu Verma | Substack
personal research journal containing articles based on my explorations with cutting edge AI. Click to read Incomplete Distillation, by Janu Verma, a Substack publication. Launched 11 days ago.
januverma.substack.com
February 4, 2025 at 2:27 PM
As a personal research project, I’m exploring the efficacy of LLMs for Recommendation System tasks. Check out my experments at januverma.substack.com
Recently, I’ve been exploring the potential of LLMs for recommendation tasks. Sharing the first report of my project where I experiment with the ability of Llama 1B model to understand user preferences from their past behavior.
open.substack.com/pub/januverm...
open.substack.com/pub/januverm...

Large Language Models for Recommender Systems
Can LLMs reason over user behaviour data to decipher preferences?
open.substack.com
January 24, 2025 at 6:03 PM
Recently, I’ve been exploring the potential of LLMs for recommendation tasks. Sharing the first report of my project where I experiment with the ability of Llama 1B model to understand user preferences from their past behavior.
open.substack.com/pub/januverm...
open.substack.com/pub/januverm...
Have we swapped “reasoning” for “agentic” as the new shibboleth
January 16, 2025 at 4:17 PM
Have we swapped “reasoning” for “agentic” as the new shibboleth
Just came back after a month in India, no-laptop family time. Any tips on how to motivate myself to do any work are highly appreciated 🙏
January 10, 2025 at 11:57 AM
Just came back after a month in India, no-laptop family time. Any tips on how to motivate myself to do any work are highly appreciated 🙏
Reposted by Janu Verma

The queen of examples and counterexamples!

Mathematician Mary Ellen Rudin was born 100 years ago today! One of the great set topologists of her age, her inspired leaps between mathematical realms was the stuff of legend. Here is her story:
tinyurl.com/mrytfn86
#MathSky #WomenInSTEM #HistSci 🧮🧪
tinyurl.com/mrytfn86
#MathSky #WomenInSTEM #HistSci 🧮🧪

Impossible Creatures and How to Make Them: The Topological Legacy of Mathematician Mary Ellen Rudin
There’s a lot to like about plain old, everyday space. No matter where you are, there’s always a way to get to where you need to go, and you can always figure out how long any route from here to there might be. Calculus works in it, and that means we can solve a lot of problems about how stuff moves through it. No matter what scale you exist at, you never lack for neighbours. Yes, space is pretty great, but what, mathematically, is it about normal space that lets it be that way, and what can you
tinyurl.com
December 8, 2024 at 1:50 AM
The queen of examples and counterexamples!
Reposted by Janu Verma

The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
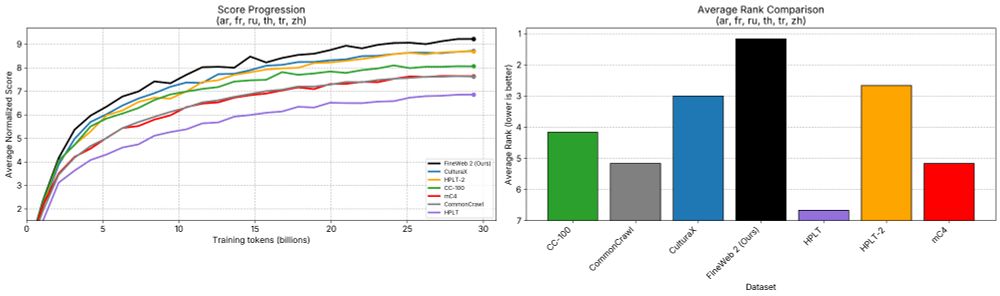
December 8, 2024 at 9:08 AM
The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
Nothing like waking up to see your models training in a nice way. #neuralnets
December 4, 2024 at 7:43 AM
Nothing like waking up to see your models training in a nice way. #neuralnets
Reposted by Janu Verma

This seems like… what we started with, no? arxiv.org/abs/2410.02724

Large Language Models as Markov Chains
Large language models (LLMs) have proven to be remarkably efficient, both across a wide range of natural language processing tasks and well beyond them. However, a comprehensive theoretical analysis o...
arxiv.org
December 3, 2024 at 12:19 PM
This seems like… what we started with, no? arxiv.org/abs/2410.02724
Taxi Driver knew better

December 2, 2024 at 4:04 PM
Taxi Driver knew better
Reposted by Janu Verma

I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
youtu.be/2AthqCX3h8U

Jonathan Berant (Tel Aviv University / Google) / Towards Robust Language Model Post-training
YouTube video by Yoav Artzi
youtu.be
December 2, 2024 at 3:45 AM
I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
youtu.be/2AthqCX3h8U
Reposted by Janu Verma

Won’t help with my reputation but since I worked on social network analysis/regulation: if Bluesky ever is a success, they are extremely likely to retrain AI models (not necessarily LLM) on user data.
November 29, 2024 at 6:53 PM
Won’t help with my reputation but since I worked on social network analysis/regulation: if Bluesky ever is a success, they are extremely likely to retrain AI models (not necessarily LLM) on user data.
If you are trying to fine-tune (instruction sft) a LLM for a specific task, how much should you work on refining the prompt? The general alpaca format seem suboptimal and far from how we use these models.
November 30, 2024 at 8:49 AM
If you are trying to fine-tune (instruction sft) a LLM for a specific task, how much should you work on refining the prompt? The general alpaca format seem suboptimal and far from how we use these models.